正文
关于下方文字内容,作者:陈思宇, 西南大学教育经济学,通信邮箱:[email protected]
Anton Korinek, Language Models and Cognitive Automation for Economic Research. NBER, 2023.
Large language models (LLMs) such as ChatGPT have the potential to revolutionize research in economics and other disciplines. I describe 25 use cases along six domains in which LLMs are starting to become useful as both research assistants and tutors: ideation, writing, background research, data analysis, coding, and mathematical derivations. I provide general instructions and demonstrate specific examples for how to take advantage of each of these, classifying the LLM capabilities from experimental to highly useful. I hypothesize that ongoing advances will improve the performance of LLMs across all of these domains, and that economic researchers who take advantage of LLMs to automate micro tasks will become significantly more productive. Finally, I speculate on the longer-term implications of cognitive automation via LLMs for economic research.
《用于经济学研究的语言模型和认知自动化》
目录



一,摘要
本文将大型语言模型的功能分为六大领域:构思、写作、背景研究、数据分析、编程、数学推导,用25个案例分别阐释了大型语言模型LLMs在六大领域中的作用和实用性。本文将LLMs的作用分为3个等级:实验性的、有用的、非常有用的。本文假设LLMs的持续发展将提高LLMs在以上6个领域的性能,使得运用LLMs自动化微任务的经济学研究者大大提高生产力。最后本文通过经济学研究LLMs预测了认知自动化的长期意义。
二,引言

1.研究背景
大型LLM的最新进展可能彻底改变经济学和其他学科的研究。LLM刚刚突破瓶颈,在广泛的认知任务中变得有用,2022年11月28日Open AI发布的GPT3.5模型在发布两个月内就获得了超1亿客户,并且GPT3.5可以每14天产生一卷相当于人类打印作品的文本。(Thompson)。谷歌和微软正计划允许用户访问LLM。
2.研究目的
1)提高生产力
本文基于最近的研究,阐释了25个现代LLM模型的案例。经过作者的实验,本文将LLM的功能分为六种:构思、写作、背景研究、数据分析、编码和数学推导。本文提供了使用这些功能的说明,并使用具体的例子来演示。此外,本文试图将每个LLM功能从实验性到非常有用进行分类。(见第29页的表1)。本文希望这一描述帮助其他研究人员使用LLM的功能。目前,本文认为LLM是最有用的工具,LLM可以自动执行研究人员在一天中多次参与的小型“微任务”,但由于这些任务太小,无法分配给人类研究助理。LLM因其高速度和低交易成本而适用于此类任务。此外,LLM在编码和数据分析任务以及构思和写作方面也有帮助。研究人员可以通过将LLM纳入他们的工作流程来显著提高他们的生产力。
2)预测未来LLM的功能
研究LLM的当前功能可以预测未来几代LLM的功能。近年来,用于培训尖端LLM的计算量(计算能力)平均每六个月翻一倍,带来了LLM功能的快速增长。人们普遍预计,这些进步将继续下去,而且更强大的LLM系统将很快发布。长期来看,本文假设LLM可能会进入一个认知自动化的时代,这可能会对经济学和其他学科的科学进步产生深远的影响。此外,这种认知自动化也可能对认知劳动的价值产生明显影响。
3.文献综述
1)低估LLM的功能
Bender认为LLM是“随机鹦鹉”(Bender et al., 2021)或“高级自动补全”。Thompson的研究表明“Mensa International的一位前主席报告称,ChatGPT在语言IQ测试中获得了147分。”尽管人类的智能水平相对静止,但LLM正在迅速发展,每一次新的迭代都让它变得更加准确和强大。
2)高估LLM的功能
另外一些研究者认为ChatGPT是人工通用智能(AGI),即人工智能。LLM可以在内容完全错误的时候产生权威风格的文本,这可能会欺骗读者,让他们相信虚假内容。
本文认为LLM在生成内容方面越来越具有比较优势;人类目前在评估和区分内容方面具有比较优势。LLM在处理大量文本方面也具有超人的能力。这些功能可以促进人机合作。
三,大型语言模型LLM
1.基础模型
Bommasani认为LLM是基础模型的一类,可以看作是21世纪20年代人工智能的新范式。基础模型是大型深度学习模型,参数计数在1011的数量级,并且还在不断增长。研究人员在丰富的数据上对模型进行预训练,以创建一个基础,然后通过一个称为微调的过程来适应不同的应用。例如,对一个LLM进行微调,使其充当聊天机器人(如ChatGPT)或生成计算机代码的系统(如Codex)。OpenAI的GPT-3.5, DeepMind的Chinchilla,谷歌的PaLM和LaMDA以及Anthropic的Claude都是一些尖端的LLM。
基础模型的预训练在自监督学习的过程中使用了大量的计算和数据,模型通过连续预测被屏蔽的数据来学习训练数据中固有的结构。例如,为了训练一个LLM,研究人员向模型提供一些含有被屏蔽词的文本片段,模型学习预测缺失的词是什么。这些数据来自维基百科、科学文章、书籍和其他网上资料。
2.OpenAI提出的缩放法则(Scaling Laws)
基础模型和扩展LLM与前几代深度学习模型的区别在于最新一代LLM缩小了人类广泛能力与特定AI系统能力的差异。LLM的整体性能根据可预测的缩放法则得到了改善,缩放法则即几代机器学习模型的经验规律。Kaplan认为缩放法则观察到,通过对数损失来衡量的LLM的拟合优度随着“训练计算量”提高,“训练计算量”即训练模型而执行的计算次数,以及训练数据的参数计数和大小。Hoffmann认为成比例增加缩放参数计数和LLM训练数据的大小是最优的。
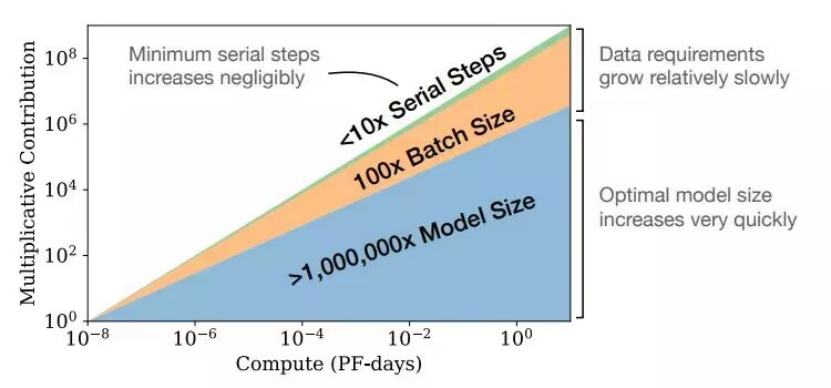
缩放法则见论文Training Compute-Optimal Large Language Models
四,LLM的应用
本节展示了LLM在经济研究中的使用案例,分为六个领域:构思、写作、背景研究、编码、数据分析和数学推导。对于每个领域,本文提供了一个普遍的解释和一些具体的用例来说明如何利用LLM的功能。除非另有说明,本文使用的是当前领先的公开可用系统GPT-3 (text-davinci-003),它比ChatGPT略强大,但生成的输出类似。为了最大限度地提高再现性,本文将模型的“Temperature”参数设置为0,这使得系统提供的响应具有确定性。该系统是在2021年截止的数据上进行训练的,由于不能访问互联网,所以生成的文本完全基于训练过程中获得的参数。此外,该系统没有记忆,信息不能从一个阶段延续到下一个阶段。该系统可以处理的文本量小于4000个字符,相当于大约3000个单词。LLM生成的结果会根据提示而变化。提示中的微小变化,例如不同的间距或标点符号,也会导致完全不同的输出。
本文展示的所有应用程序的共同点是,LLM快速的响应时间和低交易成本,这使LLM在外包微任务中非常有用,即使在一些任务中,LLM容易出错。
1.构思
1)头脑风暴
基于人类知识横截面的大量数据,研究人员训练LLM,因此LLM在头脑风暴与定义主题相关的想法和示例方面非常有用。
本文向LLM提问“请头脑风暴,通过哪些经济渠道,人工智能的进步可能会加剧不平等”。LLM模型所列出的渠道不具有创新性,但却是切题的,在很大程度上合理,而且比本文想到的方面更广。在第5点之后,本文观察到,类似于人类头脑风暴中的趋势,LLM创造力下降,反应重复。
2)评估想法
LLM也可以评估不同的想法,特别是提供不同研究计划的优点和缺点。本文输入“我正在写一篇关于人工智能对不平等的影响的论文。你觉得哪个更有用,一篇关于人工智能如何增加不平等的论文还是一篇关于人工智能如何减少不平等的论文?”
LLM模型的回应表明,研究AI如何增加不平等对积极工作更有用,而研究它如何减少不平等对规范性工作更有用。
3)提供反证
LLM擅长提供支持给定观点的论点和反驳论点。这有助于消除我们人类大脑中常见的确认偏误。本文的案例是“人工智能会加剧不平等。主要的反对意见是什么?”
LLM给出的一些反论点很好,一些很差,但LLM输出的内容涵盖了作者知道的主要观点。
2.写作
LLM的核心竞争力是生成文本。LLM在许多与写作相关的任务上都相当有用,这包括基于要点合成文本、改变文本风格、编辑文本、评估风格、生成标题、生成标题和推文。
1)合成文本
LLM可以将粗略的要点转化为结构良好、清晰易读的句子。本文使用了以下例子“请写整合以下论点并超越段落,总结一个主题句。”合成文本的功能让研究人员可以将精力集中在文章中的观点上,而不是写作过程本身。LLM也能以特定风格写作。例如,如果我们加上“以学术风格写作”、“口语化风格”、“非经济学家可以理解的风格”或“以你最喜欢的政治家的风格写作”,上面的例子就会有所不同。LLM还可以用LaTeX格式编写文本。
2)编辑文本
LLM可以修正文本的语法或拼写错误,改变风格,提高清晰度和简洁性。这组功能对于想要提高写作水平的非母语人士来说是最有用的。在下面的例子中,本文用黑体字标出了每个有错误的单词以及系统所做的更正。本文使用命令“你能纠正下面的句子吗?”
LLM可以解释它的编辑,这样学生就可以从中学习。LLM也可以根据不同水平的读者转换文本,使不同水平的读者理解。例如,使用“重写下面的文本,以便8岁的儿童理解。”
3)评估文本
LLM还可以评估文本的风格、清晰度、相似度。但以下关于这篇论文摘要草稿的提问,LLM给出的回答并不理想。
“下面这篇文章在文体上的主要缺点是什么?”“你能重写这段话来改正这些缺点吗?”作者同意LLM所指出的所有缺点。重写的版本减少了其中的一些缺点,但做得并不完美。该系统还可以回答“以下文本中哪个论证最难理解?”等问题。
4)生成标题、大纲
LLM可以生成朗朗上口的标题或大纲,下面的例子是基于作者最近一篇论文的摘要(Korinek and Juelfs, 2022)给出的3个标题
1.《面向未来的社会:为自主机器和劳动力的衰落做准备》2.《工作的终结?”导航自动化机器对劳动力的影响》3.《自主机器对劳动力的影响:如何分配工作和收入》这三个LLM建议的标题都非常适合这篇论文。
5)生成推文
LLM可以生成推文,本文在实验中命令LLM写5条推文来总结一段文本。
3.背景研究
1)总结文本
本文的实验是把一段文字总结成一个句子。“大型语言模型(LLM)有可能彻底改变经济研究。本文描述了LLM有作用的六个领域:构思、背景研究、写作、数据分析、编码和数学推导。我提供了一般说明,并演示了如何利用这些领域,并对LLM功能进行了分类,这些功能是实验性的、有用的、非常有用的。我假设,持续的进步将提高LLM在这些领域的表现,并且利用LLM自动化微任务的经济研究人员将大大提高生产力。最后,我通过LLM推测认知自动化对经济研究的长期影响。本文通过说明和演示LLM案例,讨论了大型语言模型的潜力。” LLM提供的总结句涵盖了所有要点。
2)文献综述
LLM在文献检索方面用处有限,LLM可能检索到不存在的论文,更准确的工具可以在网站上找到https://elicit.org:。这个网站只报告已存在的论文。
3)格式化参考文献
本文案例是“请将以下参考文献转换为bibtex格式”“现在将其格式化为APA格式。如果LLM在训练数据集中遇到高被引作品,例如“bibtex reference For stiglitz weiss”LLM能很好地发挥作用,让用户不必复制或输入相关作品的详细引用信息。但系统为被引次数较低的作品生成bibtex参考文献时,会公然编造文章和引文信息。
4)翻译文本
Jiao等人(2023)认为,在资源丰富的欧洲语言上,ChatGPT等LLM与商业翻译产品相比具有竞争力。但在资源较少的语言上,数字化文本和数字化翻译较少,其性能更差。
5)解释理论
LLM可以作为导师,非常清楚地解释许多常见的经济概念,这对试图学习新知识的学生非常有用,甚至对专业领域的更高级的研究人员也非常有用。本文案例是请解释“为什么工具变量是有用的?” LLM解释工具变量解释得非常好,但回答福利经济学第一、二定理非常糟糕。
4.编程
GPT3.5经过了大量计算机代码的训练,因此在编码方面相当强大。OpenAI的Codex可以通过code-davinci-002模型访问,或者作为Copilot集成到GitHub中。语言模型text-davinci-003是code-davinci-002的后代,因此它不仅能够生成自然语言,还能够生成计算机代码。虽然LLM最精通的两种编程语言是python和R,但它在任何一种常见的编程语言中都有作用——从Excel基本函数到复杂的C/ C++代码。
1)写代码
案例是 Python代码计算斐波那契数。该系统的另一个例子是绘制图形。本文将上面的提示修改为“ Python代码计算斐波那契数,并绘制前10个数字并与指数曲线进行比较”。结果运行良好。
但目前公开可用的LLM的能力不足以在没有人工帮助的情况下编写完整的代码来模拟大多数经济问题——例如,最优消费平滑、最优垄断定价等基本经济问题。
2)解释代码
LLM也可以用简单的英语解释给定代码的作用, 当研究者使用不太熟悉的编程语言时,这个功能特别有用。
3)翻译代码
通常,一种编程语言的代码需要转换成另一种语言,例如,我们可以将一个项目移植到另一个平台,LLM可以修改在StackExchange等在线编码论坛上发现的有用但使用错误语言的代码片段。
当前的LLM在跨大多数常见语言翻译短代码方面非常可靠。对于较长的序列,LLM仍然需要人工的帮助。
4)修复漏洞
本文使用的案例是“下面这段代码的错误是什么?”
LLM对于发现拼写错误和违反基本语法的情况非常有用。它还有一些超出此范围的功能,例如,LLM还可以应用于当索引混淆时。对于高级错误,例如代码底层算法中的错误,LLM仍然需要人工调试。
5.数据分析
1)从文本中提取数据
本文实验了LLM如何从书面文本中提取数据。“马克的经济学得了A,数学得了B+。莎莉的经济学和数学都得了A-。弗兰克经济学得了B,数学得了C。重新格式化如下:姓名和经济成绩和数学成绩。”
LLM还可以提取以下10种类型数据:电话号码、邮政编码、社会保险号、信用卡号、银行账号、日期、时间、价格、百分比、测量(长度、重量等)。
2)按格式整理数据
LLM同样可以将数据转换成所需的格式。建立在前面的例子中,LLM首先将数据格式化为逗号分隔的格式values (CSV)格式,然后将其格式化为LaTeX表。
3)文本分类
本文要求GPT3.5对美国劳工部职业信息网络(O*NET)数据库的5个任务进行容易或难自动化分类,并证明其分类的合理性。实验结果证明,分类是合理的,但并不完全稳健。当提示词发生变化时,系统对本质上相同的问题的答案也会发生变化。
4)提取观点
LLM还可以从文本中提取情感态度。例如,LLM可以将推文分类为“积极”或“消极”。同样,LLM可以对联邦公开市场委员会(FOMC)设定美国利率的声明进行分类, 这份声明是鹰派还是鸽派?该声明是鹰派的。委员会上调联邦基金利率目标区间,减持国债、机构债和机构抵押贷款支持证券。委员会还坚定地致力于将通胀恢复到2%的目标。该系统的评估是正确的,并且有充分的理由。
5)模拟人类受试者
Argyle et al.(2022)观察到LLM的训练数据中包含大量关于人类的信息,他提出使用LLM来模拟人类受试者。他将GPT3设定在真实人类的社会人口背景上,证明了对调查问题的后续回答与具有所描述背景的人类的实际反应高度相关。Horton(2022)展示了经济学的应用,他使用模拟的测试对象来复制和扩展几个行为实验。
6.数学推导
Noorbakhsh et al. 2021)表明,LLM可以对数学任务进行微调。Frieder等人(2023)开发了一个研究生水平数学问题的数据集,并得出结论,ChatGPT的数学能力明显低于普通数学研究生的数学能力。目前的LLM主要是通过文本和数学论文进行培训。
1)建模
本文使用LLM描述了一个消费者的消费能力,其中一种商品的消费能力是等弹性的,而另一种商品的消费能力是线性的,用LaTeX编写,并为价格分配变量。基于这个提示,LLM知道继续处理消费者的优化问题。左列显示生成的文本,右列显示由LaTeX编译的版本。可以看出,LLM正确地填充了合适的预算约束,并建立了相关的最大化问题。在拉格朗日方程中,系统包含带有异常符号的预算约束。它正确地推导出了三个一阶条件中的两个——但却在等弹性效用函数的导数上出错了。虽然阅读生成的文本和发现错误需要花费时间,但LLM自动写出最大化问题和拉格朗日问题,并在几秒钟内解决部分最大化问题,仍然有助于节省宝贵的研究时间。
2)推导方程
如前面的例子所示,目前LLM在推导方程方面已经具备了一定的有限能力。事实上,继续上面的例子,本更文正了一阶条件中的错误,并要求系统生成余项。该系统正确地推导出了最优化问题的解。
然而,系统的数学能力还是相当有限的:在得到正确的解后,本文修正了拉格朗日中的符号错误,并试图重新生成其余的推导,但系统产生了乱码。作者又尝试了其他几个推导,发现错误率太高,系统无法在这个应用中发挥作用。
3)解释模型
目前LLM解释简单模型的能力也有限。下面是一个例子,系统解释了著名的蝙蝠和球问题背后的数学原理:解决蝙蝠和球的问题,并陈述所有中间步骤。提示不同时,结果不同。当被要求展示中间步骤时,LLM经常产生更可靠的内容,这被称为“思维链提示”——类似于学生在被要求解释他们报告的解决方案背后的中间步骤时更不容易出错(Wei et al., 2022b)。
五,结论
下表总结了本文中说明的所有示例任务,按LLM应用的六个领域进行分类。在该表的第三列报告了截至2023年2月1日作者对所描述的LLM功能的有用程度的主观评价。作者的评分范围从1到3,其中1描述了LLM具有实验性的能力,但提供了不一致的结果,需要严格人为修改;2表示有用且可能节省时间的能力,但是有可能不一致,仍需仔细修改;3表示已经非常实用,并且大多数时候都以预期的方式工作。
1 =实验性的;结果不一致,需要严格的人为监督
2 =有用的;需要监督,但可能会节省时间
3 =非常有用;将这些融入到你的工作流程中会节省时间
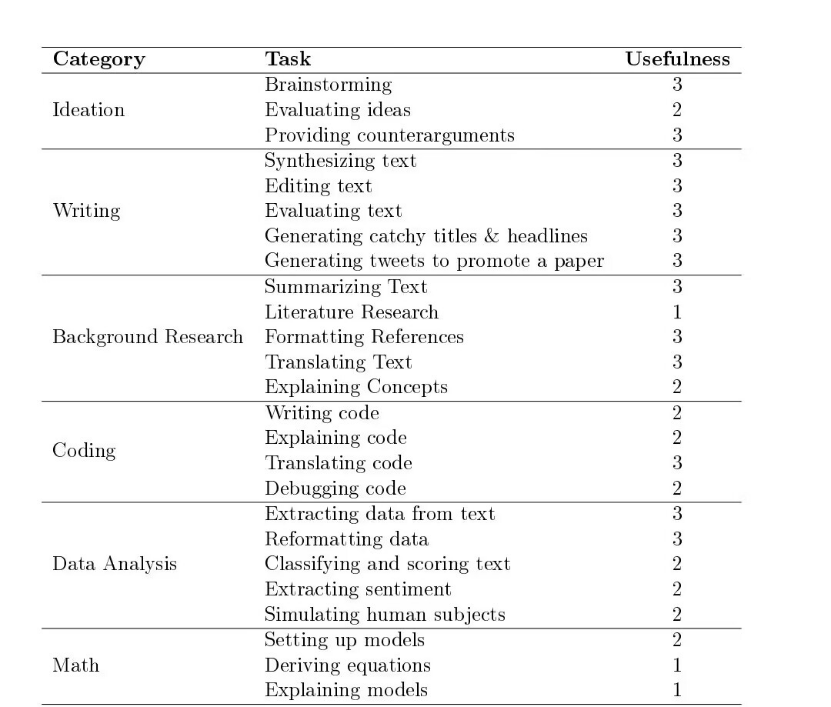
LLM已经成为对构思、写作和背景研究、数据分析、编码和数学推导等任务有用的研究工具。
在短期内,通过LLM的认知自动化将使研究人员变得更加富有成效。这可能有助于提高经济学的整体进步速度。
从中期来看,LLM将在生成研究论文的内容方面越来越有用。人类研究人员将专注于他们的比较优势——通过提出问题、建议获得答案的方向,区分哪些产生内容是有用的,并且编辑信息和提供反馈,类似于顾问。LLM的进步将意味着LLM将越来越好地执行任务,因此对人类提供输入、编辑和反馈的需求将会减少。
从长远来看,经济学家应该吸取AI进步的“惨痛教训”,Sutton将其描述为:在AI的大部分历史中,研究人员致力于通过将特定领域的知识编程到AI系统中,使其更智能、更强大,他观察到,这种策略在短期内总是有帮助的,但它的好处最终会趋于平稳。
有了足够的计算能力,足够先进的人工智能系统可能产生并阐明卓越的经济模型,而人类经济学家的认知工作最终可能变得多余。
六,前景
认知自动化给经济学家提出了新研究问题:
1.认知自动化对劳动力市场意味着什么?它是否也会加速体力劳动的自动化?我们的社会如何才能最好地为即将到来的变化做好准备?
2.认知自动化对教育的影响是什么?人力资本会贬值吗?
3.认知自动化将如何影响技术进步和经济增长?如果人类劳动可以实现自动化,未来增长的瓶颈会是什么?
4.我们如何才能最好地解决AI对齐问题?