在大语言模型驱动下的自主智能体方面,作者所在团队发布了该领域的早期综述(见A Survey on LLM-based Autonomous Agents),并构建了用户行为分析领域中首个基于自主智能体的模拟环境RecAgent(见RUC-GSAI/YuLan-Rec),欢迎大家关注。
基于大语言模型的智能体(LLM-based Agent)在近期得到了广泛关注。本文汇总了在ICLR’24提交的论文中,基于大语言模型的智能体相关的全部论文,并进行了分类汇总,共计98篇。
今天我们给大家分享的是「智能体能力」主题的论文,共40篇。
Survey: https://github.com/Paitesanshi/LLM-Agent-Survey
Code: https://github.com/RUC-GSAI/YuLan-Rec
1. Agent Instructs Large Language Models to be General Zero-Shot Reasoners
本文通过构造agent来生成任务相关的(task-specific)指令(instructions),从而优化LLM的推理能力。

链接:https://www.aminer.cn/pub/651f6e093fda6d7f06d0c761/?f=cs
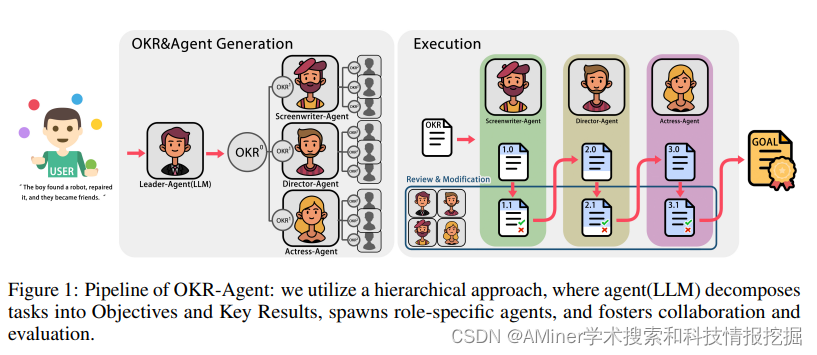
2. OKR-Agent: An Object and Key Results Driven Agent System with Hierarchical Self-Collaboration and Self-Evaluation
本文提出了OKR-Agent方法,利用自协作(self-collaboration)和自校正(self-correction)机制,通过层次化的(hierarchical) agent来解决复杂任务。
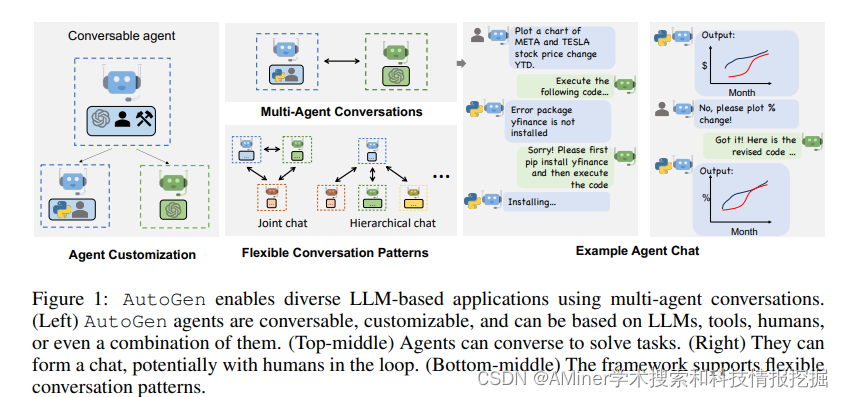
3. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
本文提出了开源框架AutoGen,能够构建依靠多智能体对话来完成任务的应用程序。
链接:https://www.aminer.cn/pub/64dd9b053fda6d7f0622e6e8/?f=cs
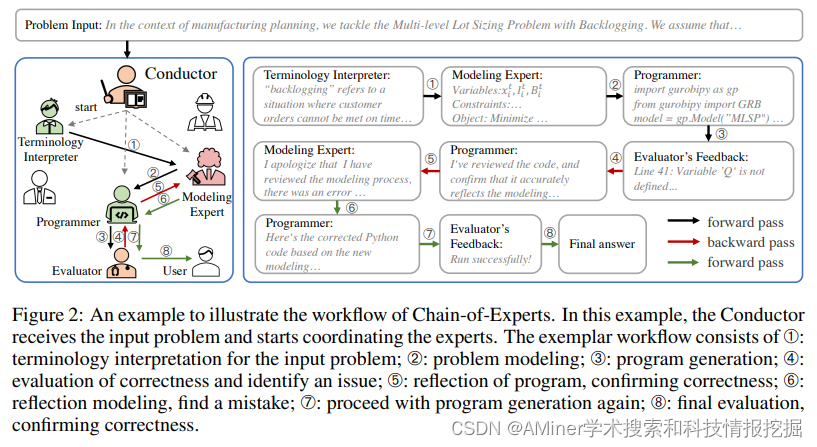
4. Chain-of-Experts: When LLMs Meet Complex Operations Research Problems
本文研究了对复杂运筹学问题的建模和编程,首次提出了基于LLM的解决方案,它是一个多智能体协作增强推理的框架,即Chain-of-Expers(CoE),以减轻对领域专家的严重依赖。
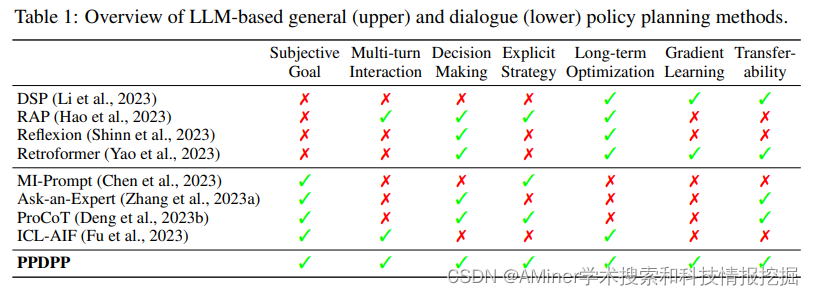
5. Plug-and-Play Policy Planner for Large Language Model Powered Dialogue Agents
本文提出了一个新的对话策略规划范式,赋予LLM使用可调的(tunable)语言插件主动解决对话问题的策略。
6. Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph
本文提出了LLM与KG相结合的新范式Think-on-Graph(ToG),通过在图上beam search帮助LLM agent找到最佳推理路径。
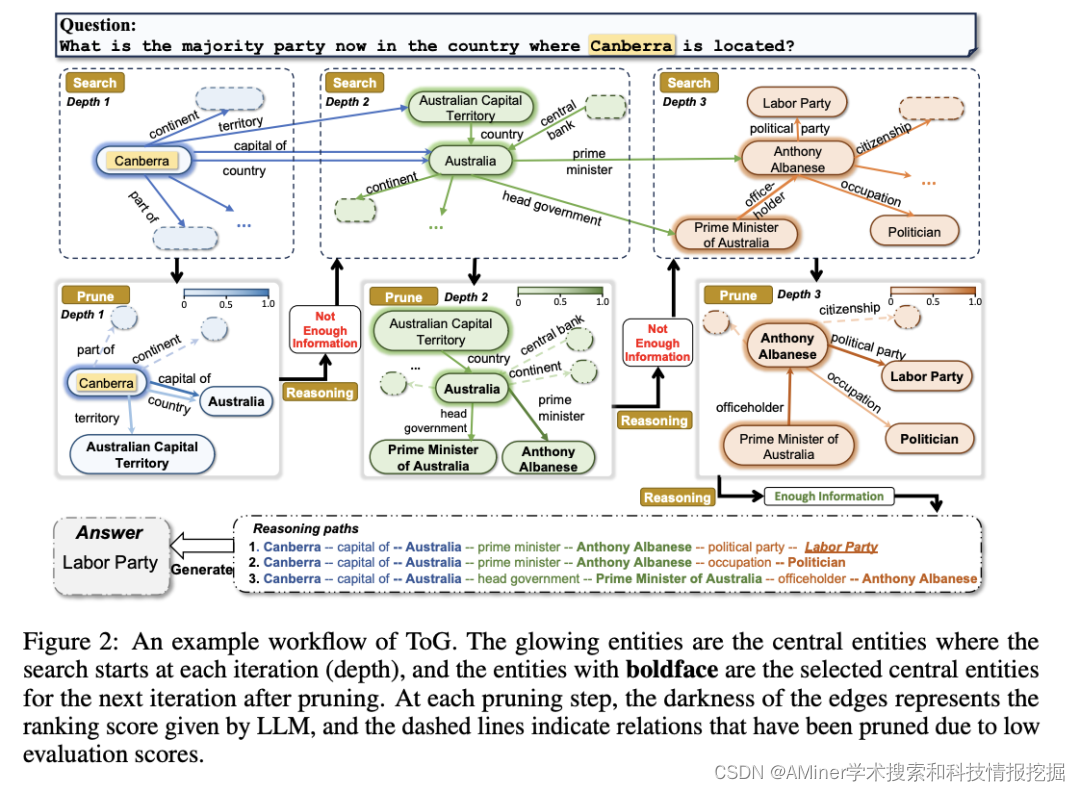
链接:https://www.aminer.cn/pub/64b60eaa3fda6d7f06eae92c/?f=cs
7. THOUGHT PROPAGATION: AN ANALOGICAL APPROACH TO COMPLEX REASONING WITH LARGE LANGUAGE MODELS
本文提出了TP(Thought Propagation),通过探索类似的问题的解决方案来增强LLM agent的复杂推理能力。
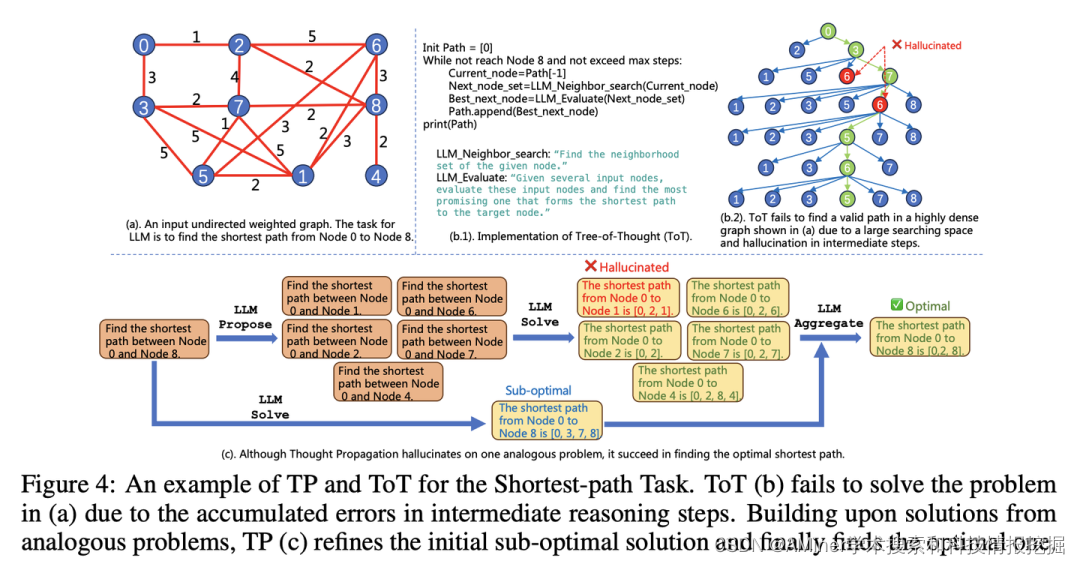
链接:https://www.aminer.cn/pub/652378c7939a5f4082e153d9/?f=cs
8. Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
本文提出了语言智能体树搜索(Language Agent Tree Search, LATS)来协同大模型的计划、行动和推理。
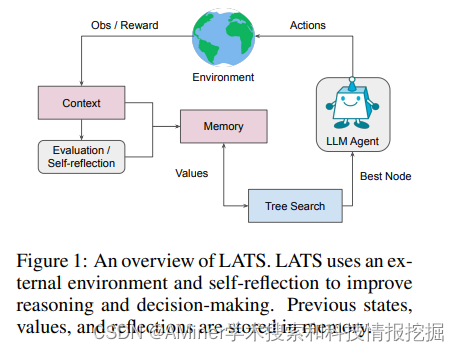
链接:https://www.aminer.cn/pub/652379d2939a5f4082e1c7ab/?f=cs
9. REX: Rapid Exploration and eXploitation for AI agents
有效探索行动空间对于LLM-based agent完成各种任务至关重要,本文提出了一种方法,能够快速探索(explore)和开发(exploit)该动作空间。

链接:https://www.aminer.cn/pub/64b76c6a3fda6d7f068ee2cd/?f=cs
10. Asking Before Acting: Gather Information in Embodied Decision-Making with Language Models
本文提出了ABA方法(Asking Before Acting),一个赋予智能体在与环境交互的过程中,主动用自然语言询问外部相关信息的方法。
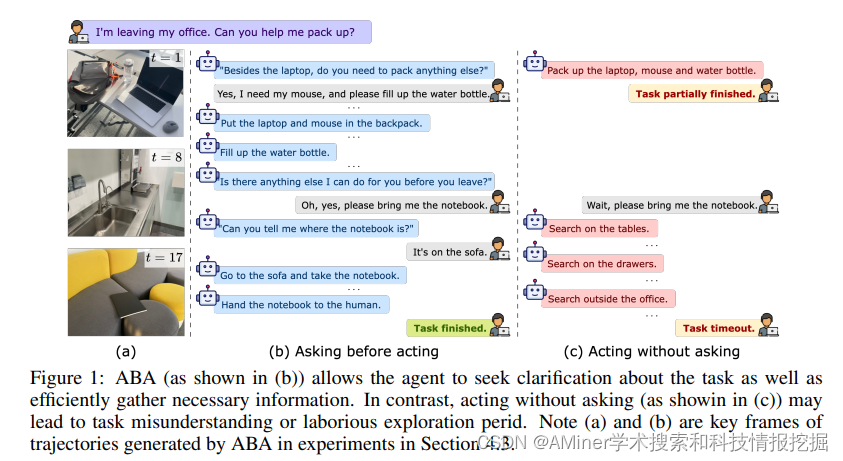
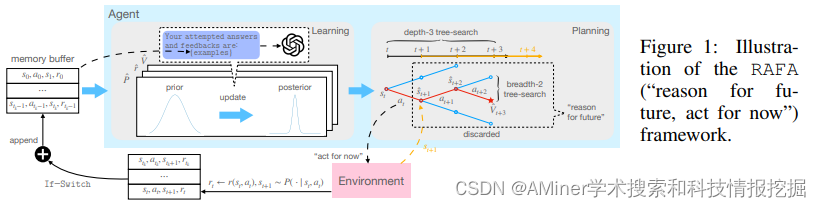
11. Reason for Future, Act for Now: A Principled Architecture for Autonomous LLM Agents
本文提出了一个框架,它基于可证明的后悔界来指导推理和行动。
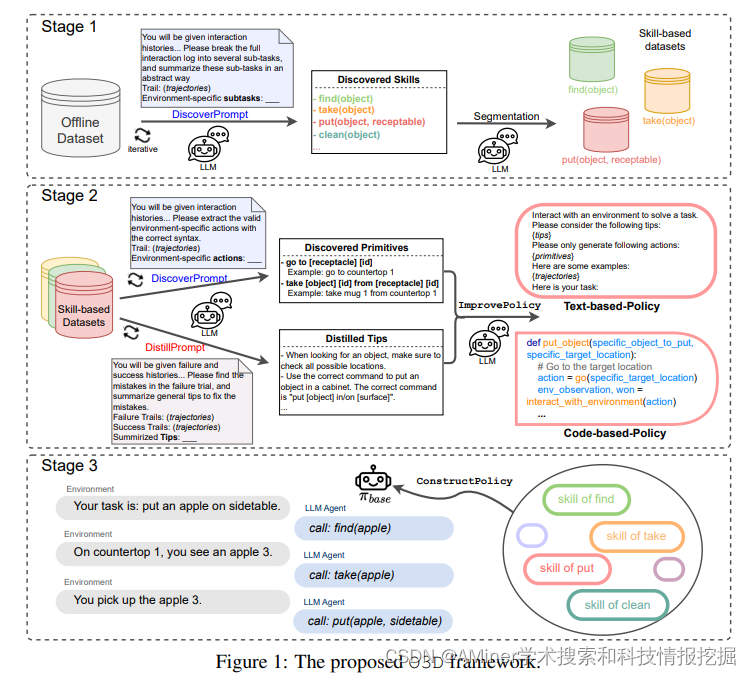
12. O3D: Offline Data-driven Discovery and Distillation for Sequential Decision-Making with Large Language Models
本文提出了一个离线学习框架,使用大量离线数据(如人类交互数据)来提高LLM-based 的in-context learning的能力。
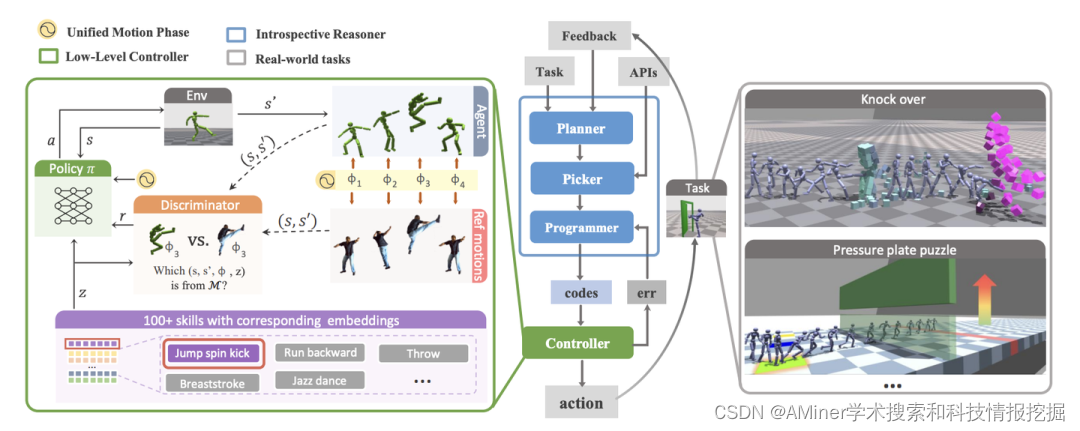
13. Reason to Behave: Achieving Human-Like Task Execution for Physics-Based Characters
本文提出了一个由大模型内省推理器与增强控制器相结合的开源框架,为智能体赋予行为理性(Reason to Behave)。
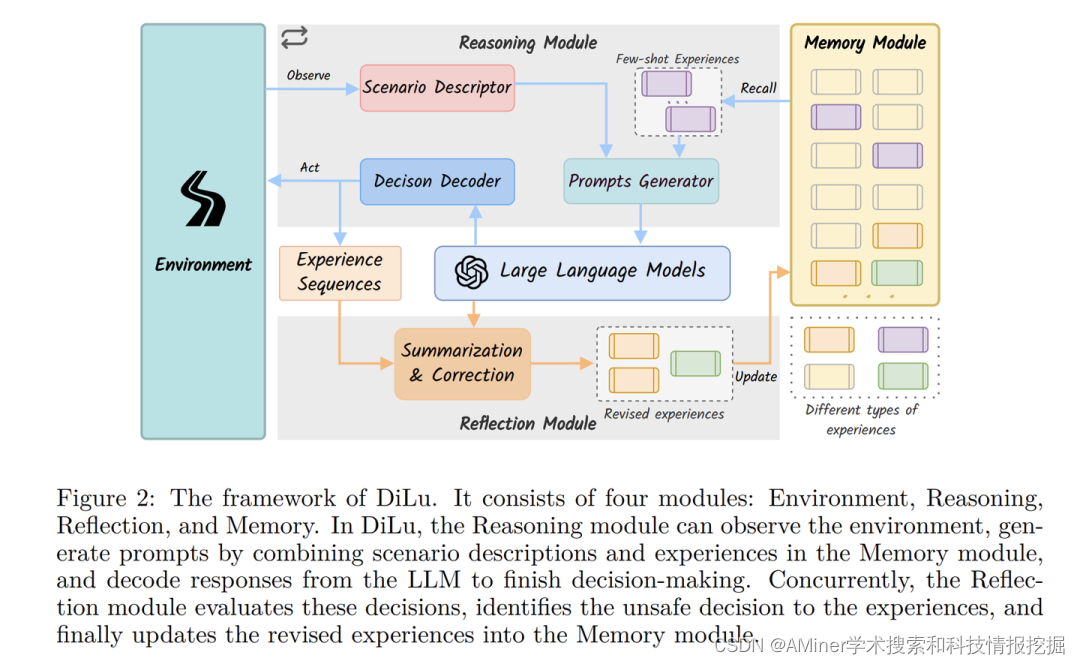
14. DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models
本文提出了DiLu框架,该框架结合了推理和反思模块,使系统能够基于常识知识进行决策并不断发展。
链接:https://www.aminer.cn/pub/6516338d3fda6d7f065e5029/?f=cs
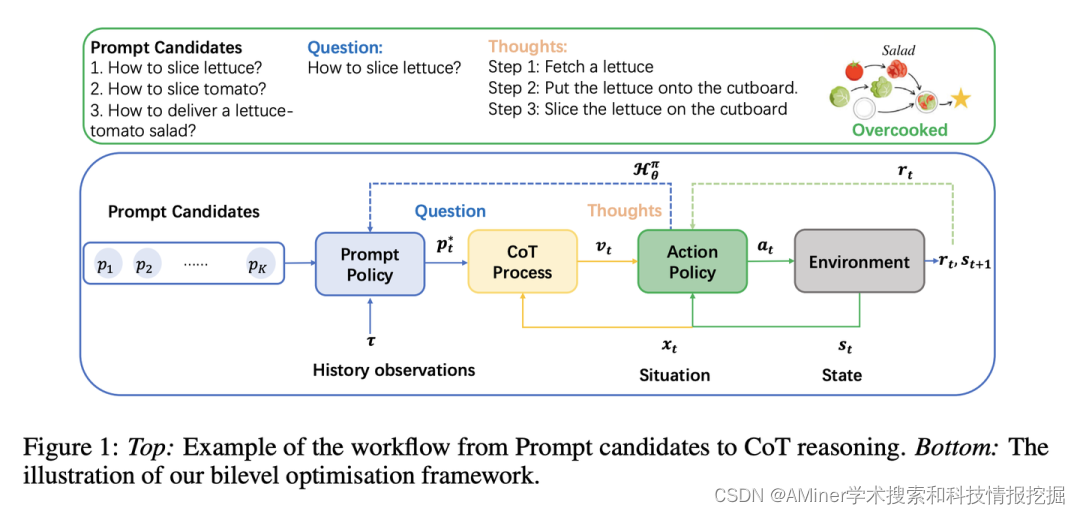
15. Ask more, know better: Reinforce-Learned Prompt Questions for Decision Making with Large Language Models
本文提出了一个新的领导者-追随者双层框架Bilevel-LLM,能够学习提出相关问题(提示),并随后进行推理,以指导agent学习在环境中要执行的行动。
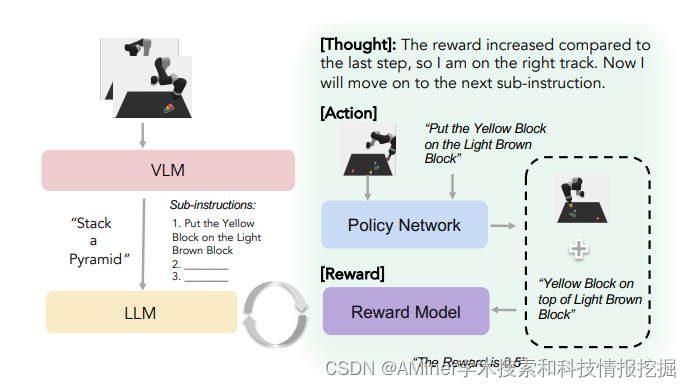
16. MultiReAct: Multimodal Tools Augmented Reasoning-Acting Traces for Embodied Agent Planning
当面对抽象指令中描述的长期任务时,LLM会遇到实质性的挑战。为了解决这些问题并提高LLM在具体场景中的规划能力,本文提出了一种新的方法,称为MultiReAct。
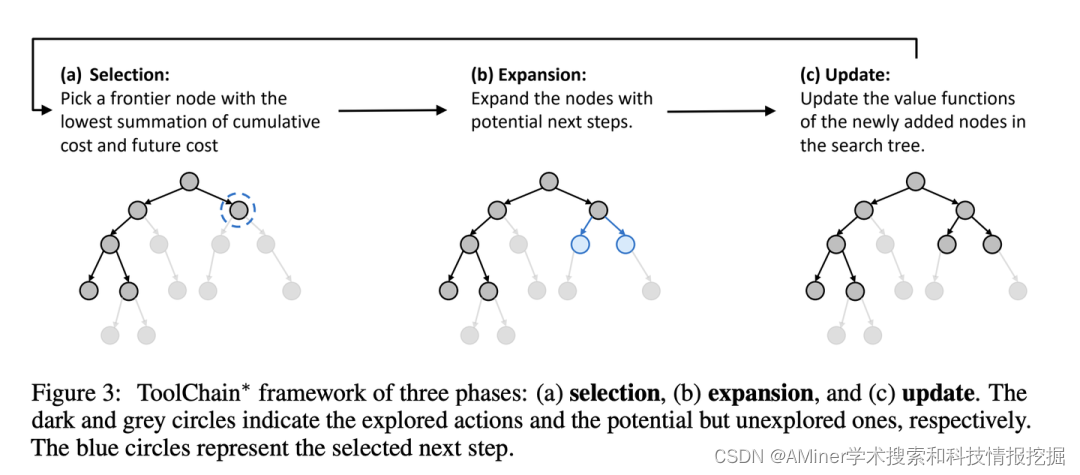
17. ToolChain: Efficient Action Space Navigation in Large Language Models with A Search
本文提出ToolChain∗,一个基于A*搜索的LLM智能体规划算法。
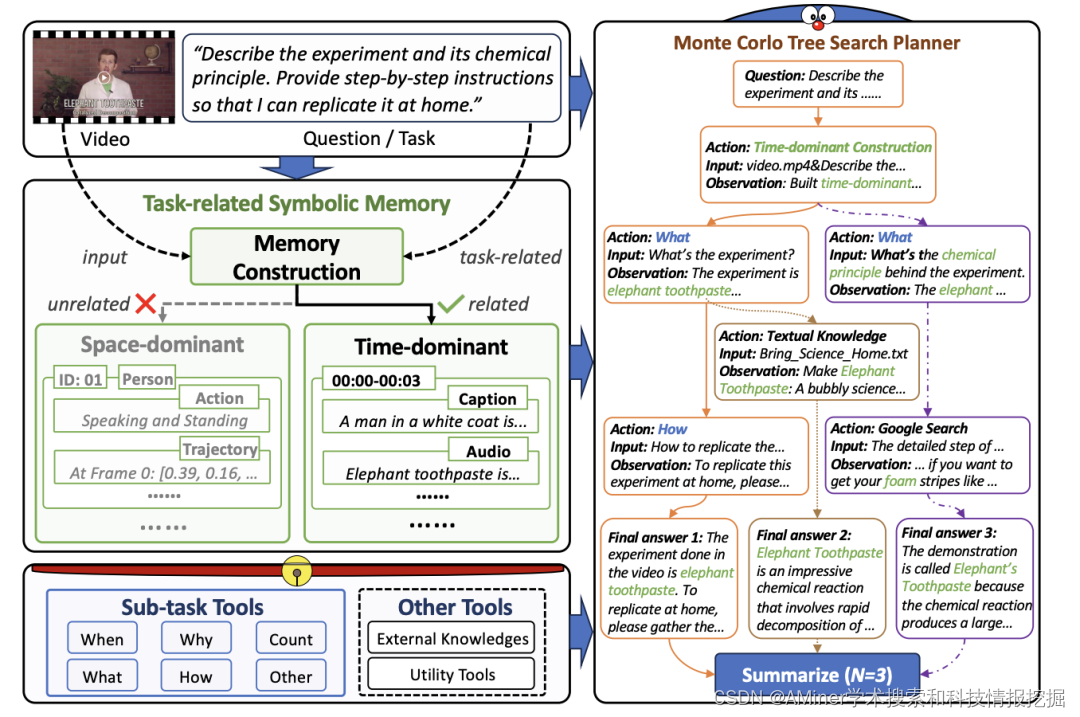
18. DoraemonGPT: Toward Solving Real-world Tasks with Large Language Models
本文提出DORAEMONGPT,一种新的基于蒙特卡罗树搜索的LLM规划器,可以有效探索使用各种工具的规划空间。
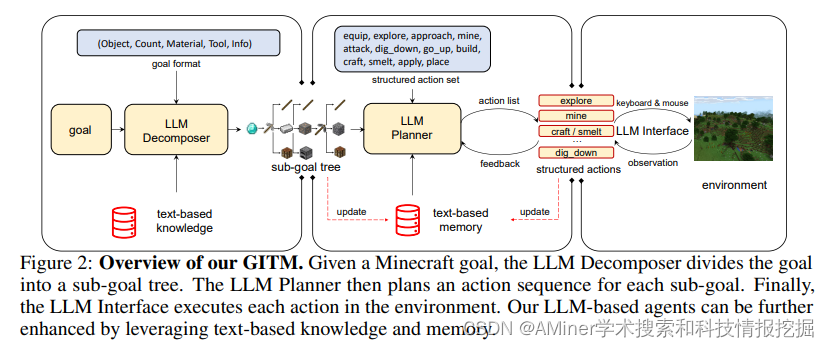
19. Ghost in the Minecraft: Hierarchical Agents for Minecraft via Large Language Models with Text-based Knowledge and Memory
本文提出了GITM(Ghost in Minecraft),一种新的层次化智能体,将LLM和基于文本的知识与记忆结合。
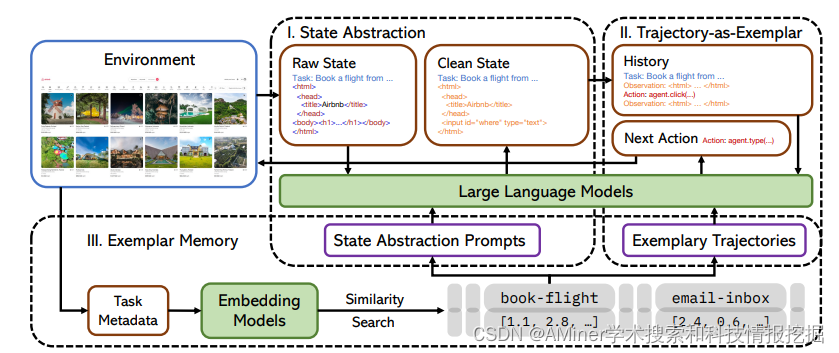
20. Synapse: Trajectory-as-Exemplar Prompting with Memory for Computer Control
本文提出了Synapse,一种结合轨迹示例提示和相关记忆结合的智能体,以解决计算机控制问题。
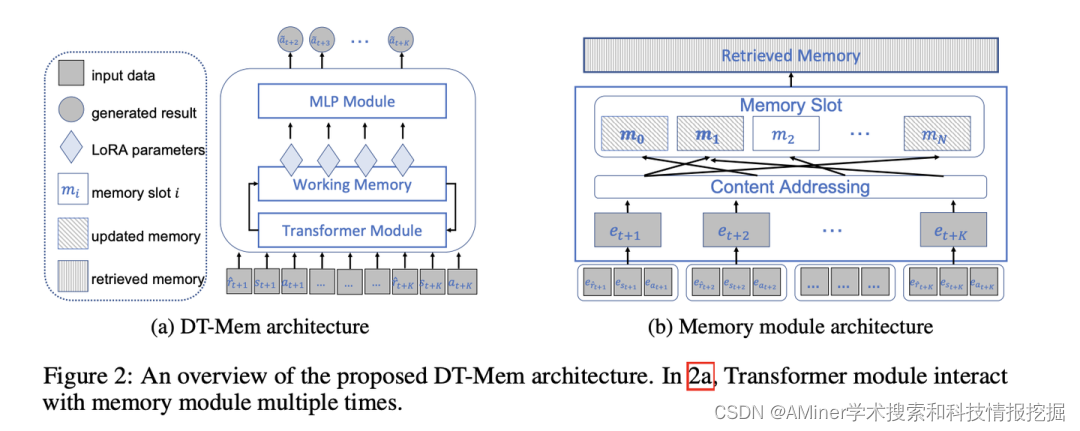
21. Think Before You Act: Decision Transformers with Internal Memory
本文借鉴了人类大脑分布式记忆存储的特点 ,提出了构建LLM内部记忆模块DT-Mem来存储、混合和检索不同下游任务的信息。
链接:https://www.aminer.cn/pub/64741a3ad68f896efaa6213a/?f=cs
22. Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading
本文提出MemWalker,一个交互式长文本阅读agent,通过迭代提示,根据自身推理决定仔细阅读文本的哪一部分。

链接:https://www.aminer.cn/pub/65252a2b939a5f4082692249/?f=cs
23. Prospector: Improving LLM Agents with Self-Asking and Trajectory Ranking
基于ICL(in-context learning)的方法缺乏基于环境奖励的轨迹优化机制,本文提出了Prospector,一个具有自我询问和轨迹排序的可反思的(reflective) LLM-based智能体。
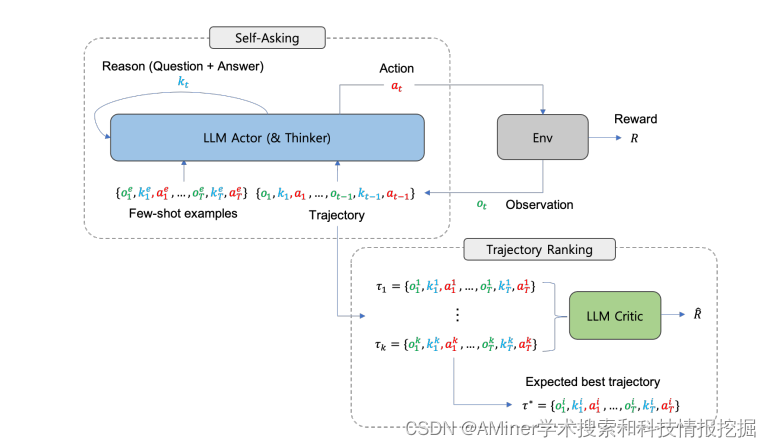
24. Adapting LLM Agents Through Communication
本文提出了交流学习范式(Learning through Communication, LTC),能够使LLM-based agent在与环境和其他agent的不断交流中训练,从而使agent无需人类监督,即可适配新的任务。
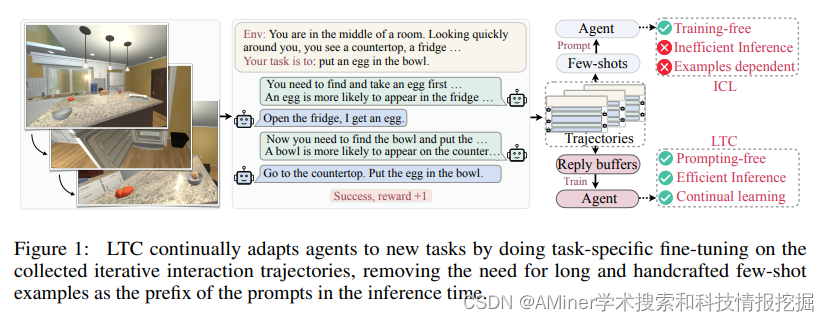
链接:https://www.aminer.cn/pub/651ccb373fda6d7f06635257/?f=cs
25. Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization
本文提出了一个通过学习回顾模型,来增强LLM-based agent的框架,它能够自动地根据环境反馈,用策略梯度调节agent的语言提示(prompt)。
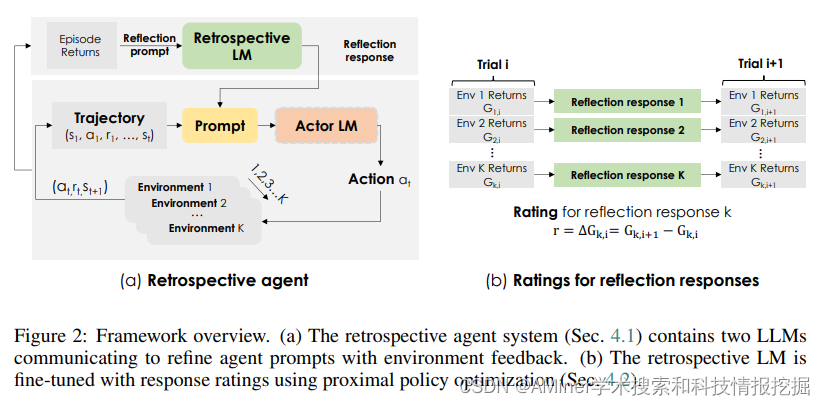
链接:https://www.aminer.cn/pub/64d074bf3fda6d7f06ce92a0/?f=cs
26. Formally Specifying the High-Level Behavior of LLM-Based Agents
本文提出了一个最小化(minimalistic)、高层次(high-level)的生成框架,来简化设计和实现新智能体的复杂过程。
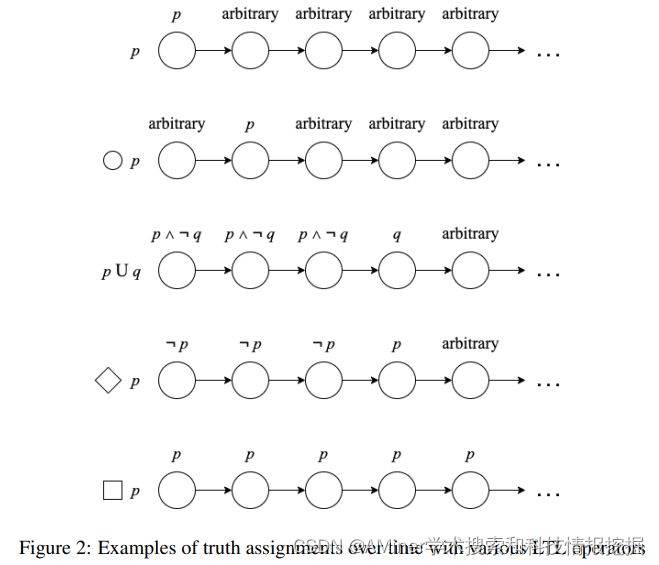
链接:https://www.aminer.cn/pub/6528a864939a5f408257a10f/?f=cs
27. CLIN: A Continually Learning Language Agent for Rapid Task Adaptation and Generalization
本文提出了CLIN模型,能够在环境中不断进行试验改进,且无需参数更新,即使环境和任务都发生变化。
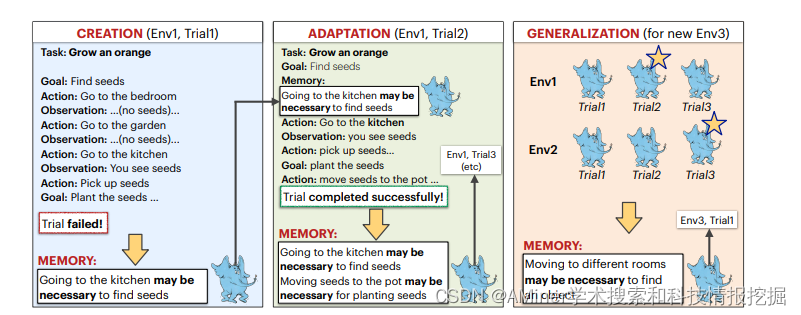
链接:https://www.aminer.cn/pub/652dee7a939a5f4082b44793/?f=cs
28. Learning to Solve New sequential decision-making Tasks with In-Context Learning
自主智能体能够通过少样本泛化到新任务上,但顺序决策设定带来了额外挑战,并且对错误的容忍度要低得多,因为环境的随机性或智能体的错误行为可能导致不可见的(有时是不可恢复的)状态。本文使用一个例子表明,基于朴素transformer的序列决策并不能实现少样本学习。

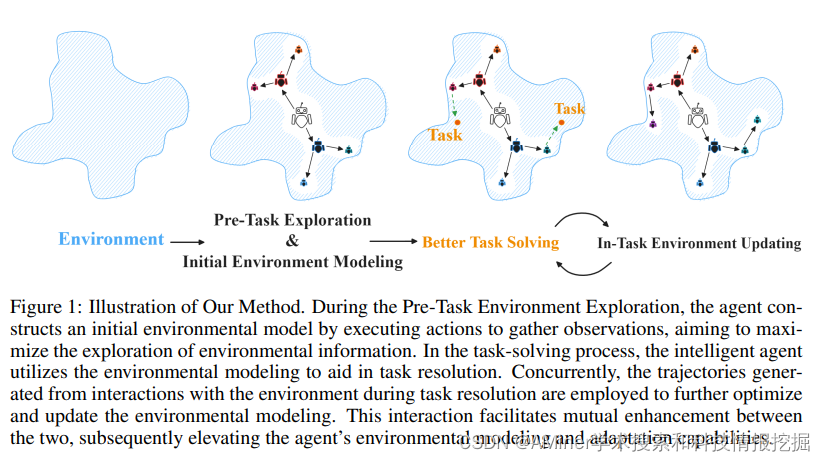
29. Adaptive Environmental Modeling for Task-Oriented Language Agents
在交互式场景和动态场景中,由于缺乏集成环境建模,agent仍面临巨大调整。本文提出了面向任务的环境适应(task-oriented environmental adaptation)方法,使agent能够自主建模新环境。
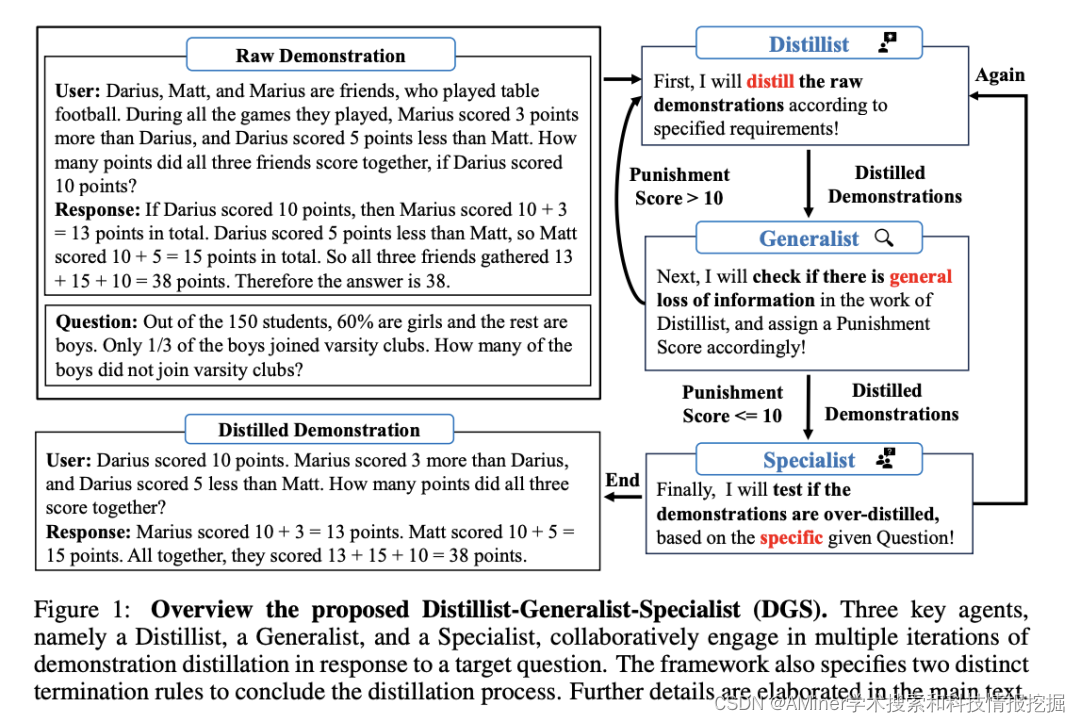
30. Demonstration Distillation for Efficient In-Context Learning
本文提出一个蒸馏框架DGS (Distillist-Generalist-Specialist),在三个LLM agents的辅助下,DGS迭代地消除无用信息,同时保持有效信息。
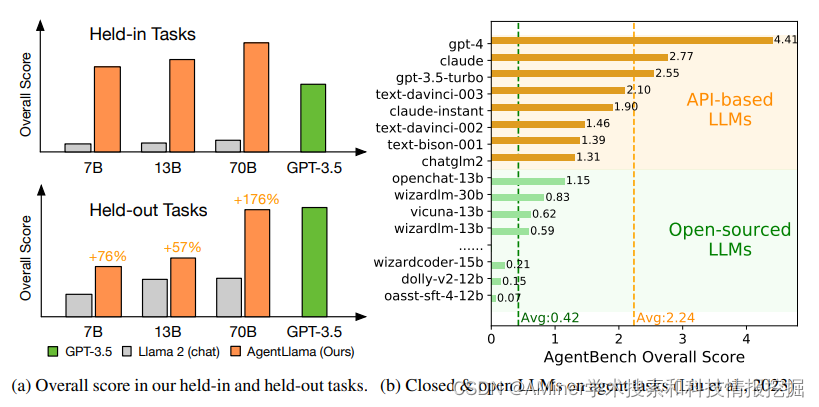
31. AgentTuning: Enabling Generalized Agent Abilities for LLMs
许多方法通过设计prompt来提高agent在特定任务(particular agent tasks)上的性能,但当前研究没有关注在提高agent在特定性能的同时,仍然需要保持其通用性能(general abilities)。本文提出了AgentTuning的通用方法,使其既能提高LLM的agent的能力,还能保持其通用能力;本文还构建了AgentDataset数据集来进行指令微调;本文在Llama2上进行指令微调,得到AgentLlama。
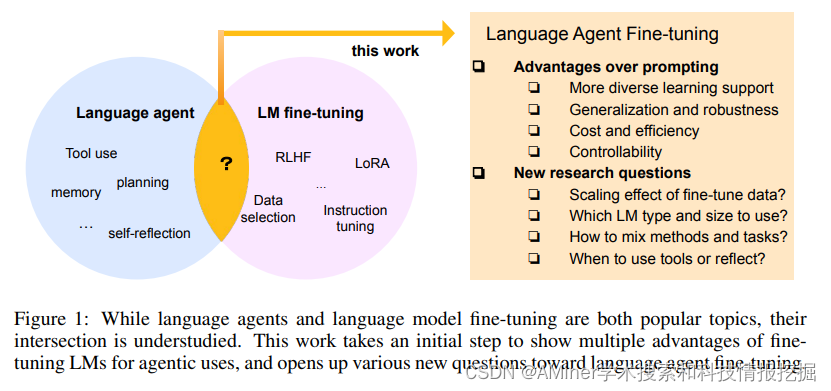
32. FireAct: Toward Language Agent Finetuning
本文对LLM到LLM-based agent的微调进行了研究。
33. Aligning Agents like Large Language Models
本文研究了是否可以使用目前大语言模型的训练方法,来对齐一个大规模的模仿学习智能体。
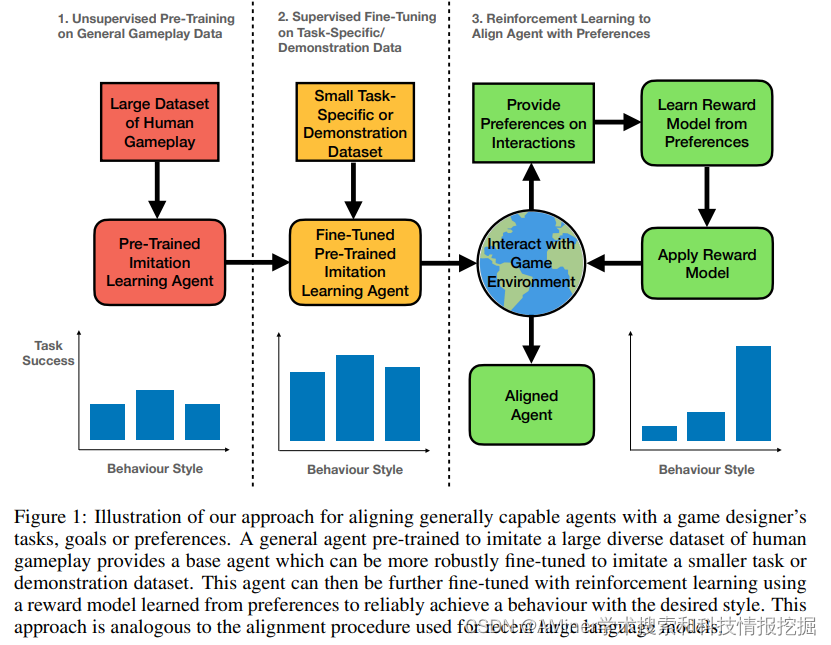
34. SALMON: Self-Alignment with Principle-Following Reward Models
本文提出了一种新的对齐范式SALMON(Self-ALignMent with principle-fOllowiNg reward models),只需一组人工定义的规则就可以实现良好的对齐效果。

链接:https://www.aminer.cn/pub/65252d8c939a5f40827e9156/?f=cs
35. Making Large Language Models Better Reasoners with Alignment
本文提出了AFT(Alignment Fine-Tuning)范式,通过Constrained Alignment Loss解决LLM对齐过程中的评估偏差问题,从而提升模型推理能力。
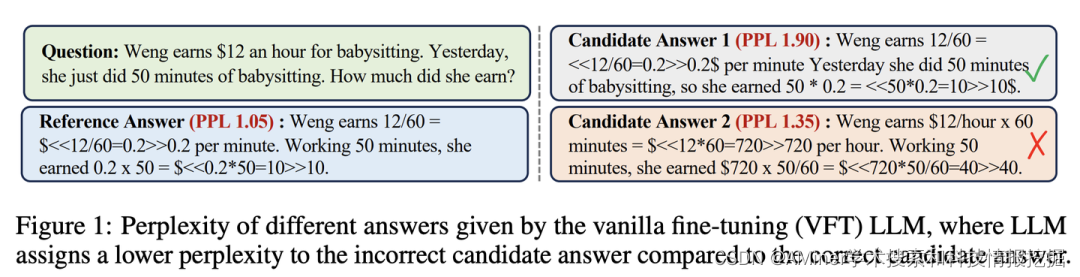
链接:https://www.aminer.cn/pub/64f7fb943fda6d7f06f3c469/?f=cs
36. Confronting Reward Model Overoptimization with Constrained RLHF
LLM-based agent通常通过优化适合人类反馈的奖励模型(RM)来与人类偏好保持一致,本文实验探究了复合RM中过度优化的问题,并提出了解决方案。
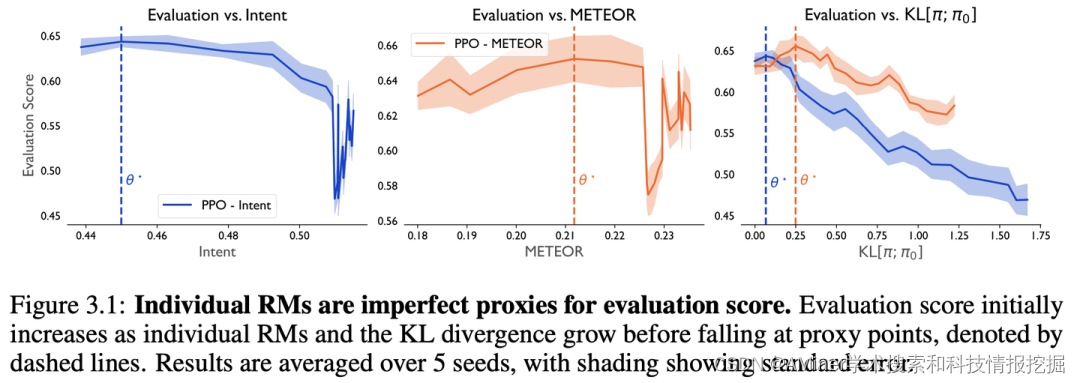
链接:https://www.aminer.cn/pub/652379c3939a5f4082e1c106/?f=cs
37. True Knowledge Comes from Practice: Aligning Large Language Models with Embodied Environments via Reinforcement Learning
本文提出一个新的通用在线框架TWOSOM,利用RL与具体环境进行有效的交互和协调,将LLM agent与实体环境对齐,而不需要任何准备好的数据集或环境的先验知识。
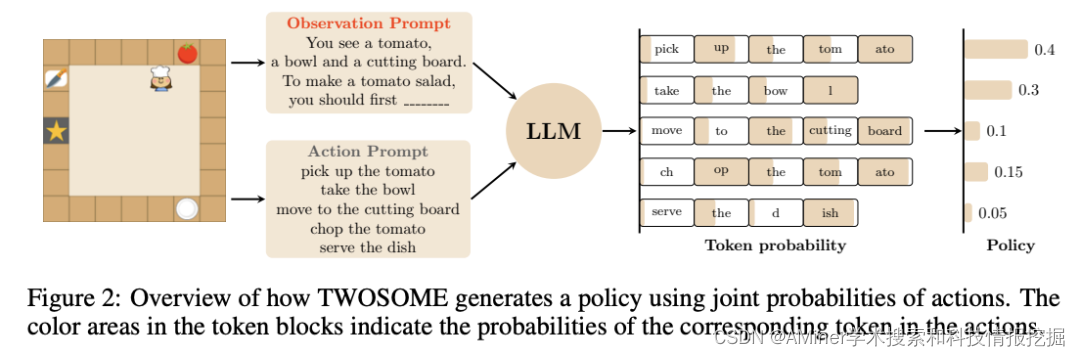
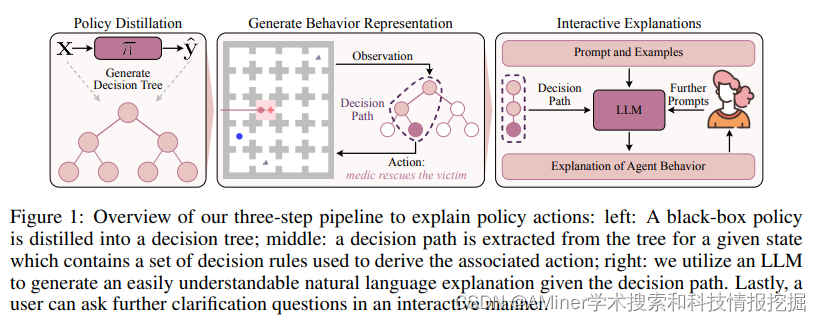
38. Understanding Your Agent: Leveraging Large Language Models for Behavior Explanation
本文提出了一种方法,基于状态和动作的观测,为智能体的行为生成自然语言的解释,该方法独立于底层模型的表示。
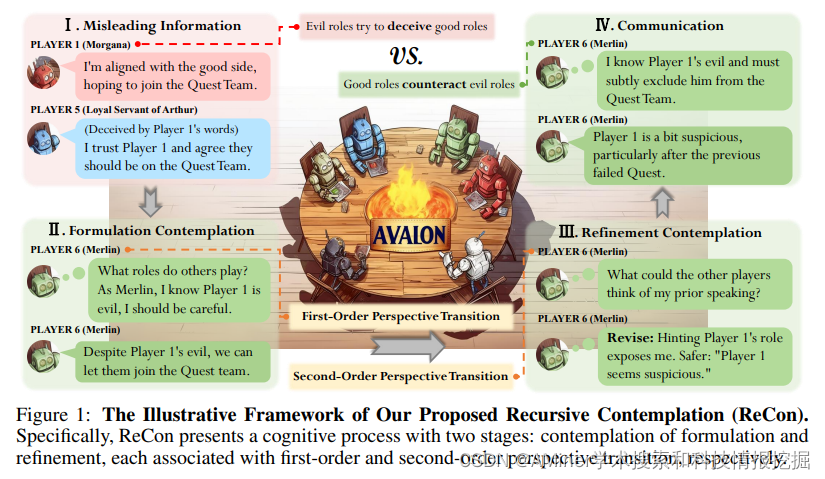
39. Avalon’s Game of Thoughts: Battle Against Deception through Recursive Contemplation
本文提出了一个框架ReCon,它能够提升LLM的识别和低效欺诈信息的能力,并使用含有欺骗元素的Avalon游戏作为测试。
链接:https://www.aminer.cn/pub/651b7dfd3fda6d7f0630b799/?f=cs
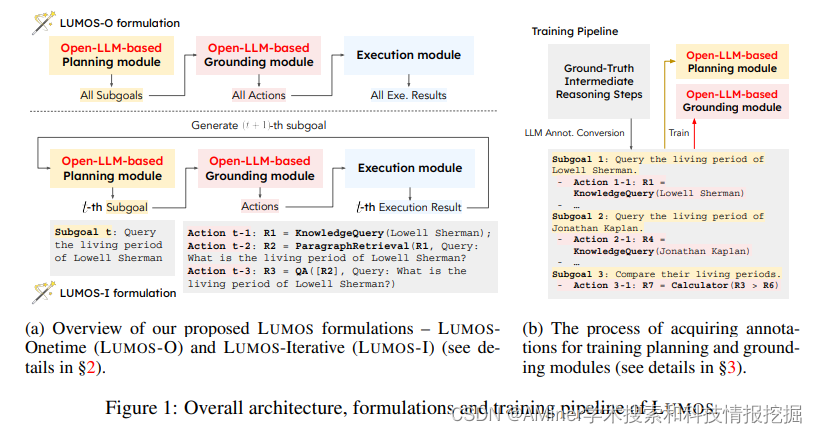
40. LUMOS: Towards Language Agents that are Unified, Modular, and Open Source
本文提出了一个统一格式的、模块化设计的、开源的大语言模型智能体。
内容转载自公众号RUC AI Box:https://mp.weixin.qq.com/s/GGRWQJ-eBvHerB9H9JPCjg