在大语言模型驱动下的自主智能体方面,作者所在团队发布了该领域的早期综述(见A Survey on LLM-based Autonomous Agents),并构建了用户行为分析领域中首个基于自主智能体的模拟环境RecAgent(见RUC-GSAI/YuLan-Rec),欢迎大家关注。
基于大语言模型的智能体(LLM-based Agent)在近期得到了广泛关注。本文汇总了在ICLR’24提交的论文中,基于大语言模型的智能体相关的全部论文,并进行了分类汇总,共计98篇。
今天我们给大家分享的是「多智能体」主题的论文,共11篇。
- Survey:https://github.com/Paitesanshi/LLM-Agent-Survey
- Code:https://github.com/RUC-GSAI/YuLan-Rec
内容转载自:ICLR’24 大语言模型智能体最新研究进展丨智能体能力篇
1. AgentBench: Evaluating LLMs as Agents
提出了包括8个不同环境的多维度评测基准,通过多轮开放生成环境,用于评测LLM-based agent的推理和决策能力。本文对27个LLM进行了评测,并进行了进一步的分析。
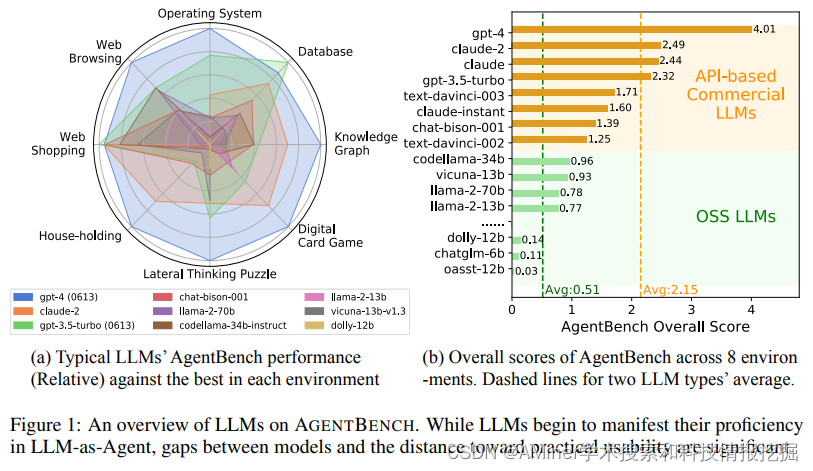
链接:https://www.aminer.cn/pub/64d1bdf93fda6d7f06ec4af3/?f=cs
2. Large Language Models as Gaming Agents
本文提出利用游戏环境对agent进行评测,并进行了相关分析。
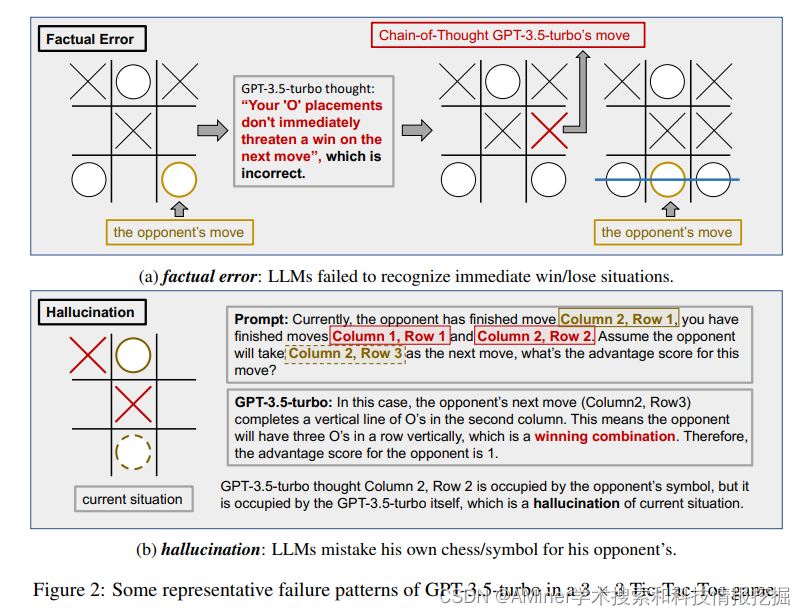
3. Benchmarking Large Language Models as AI Research Agents
本文提出了MLAgentBentch,用于评测agent解决机器学习(machine learning)任务的能力。
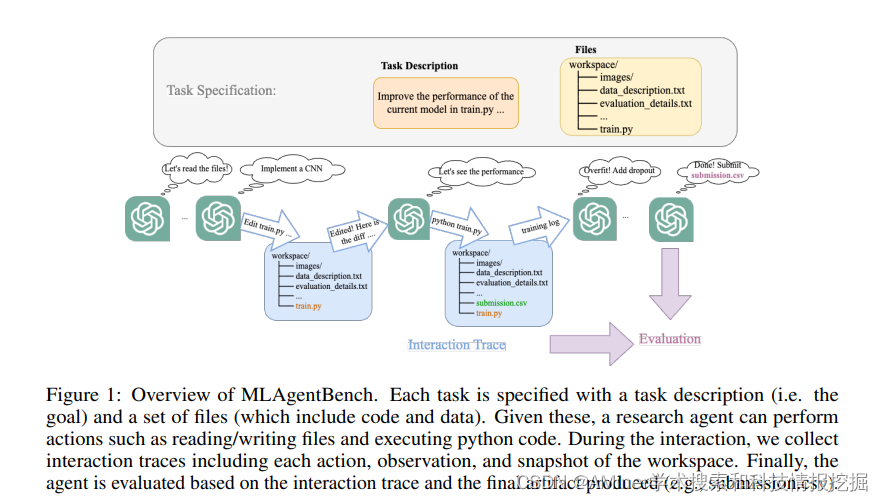
链接:https://www.aminer.cn/pub/651f6e093fda6d7f06d0c5bb/?f=cs
4. Identifying the Risks of LM Agents with an LM-Emulated Sandbox
本文提出了一个新框架ToolEmu,使用语言模型来模拟工具执行的框架,并能够针对各种工具和场景对基于语言模型的智能体进行可扩展的测试。

链接:https://www.aminer.cn/pub/6514e2043fda6d7f062dcb33/?f=cs
5. Evaluating Multi-Agent Coordination Abilities in Large Language Models
本文构建并评估了在各种合作场景中,使用LLM构建agent的有效性。
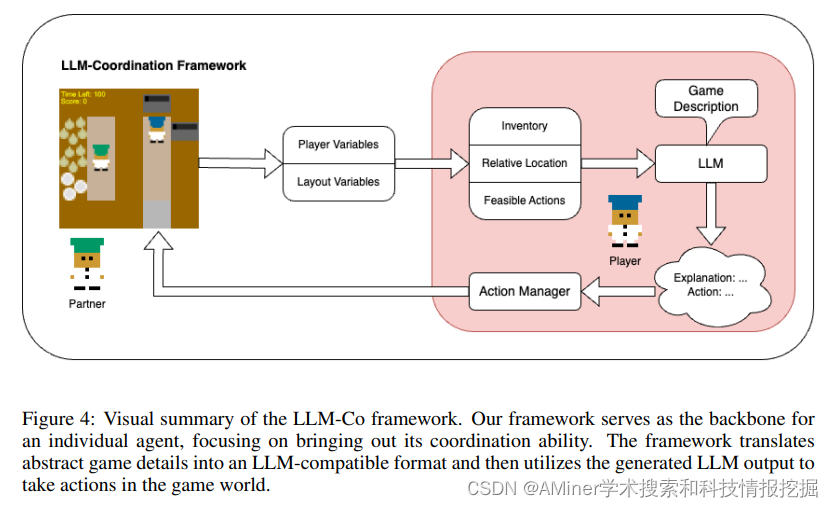
链接:https://www.aminer.cn/pub/65237861939a5f4082e12b98/?f=cs
6. SmartPlay : A Benchmark for LLMs as Intelligent Agents
本文提出了SmartPlay,一个具有挑战性的评测方法和评测基准,来对LLM-based智能体进行评测。
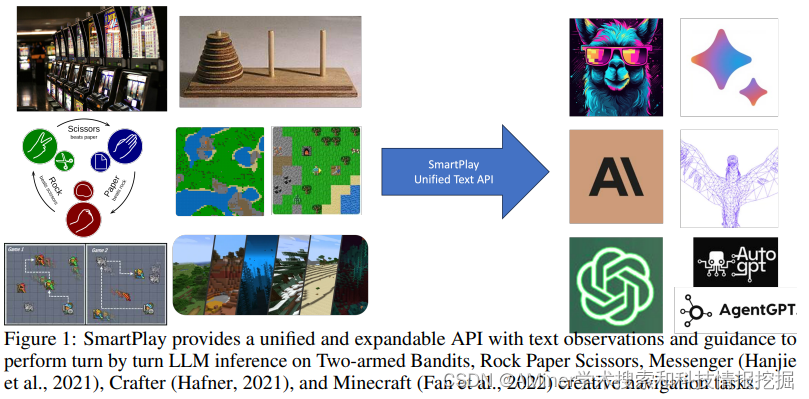
链接:https://www.aminer.cn/pub/651ccb383fda6d7f066352ca/?f=cs
7. LLM-Deliberation: Evaluating LLMs with Interactive Multi-Agent Negotiation Game
本文提出了基于评分协作游戏,对LLM进行评测的框架。

链接:https://www.aminer.cn/pub/651a282d3fda6d7f0600a261/?f=cs
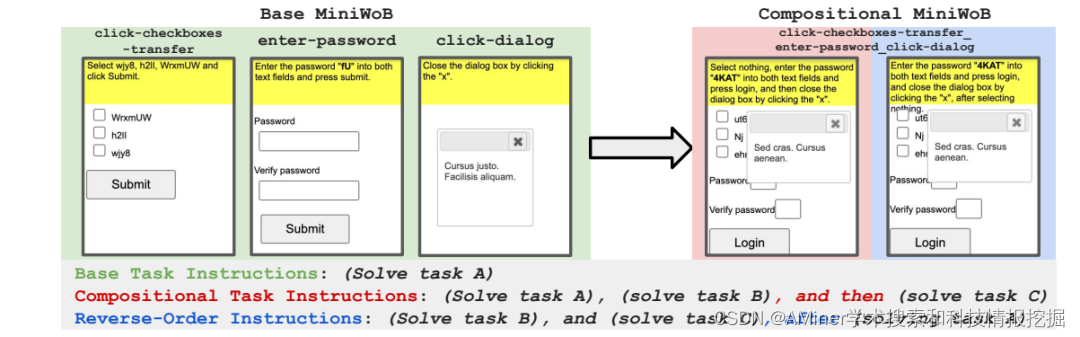
8. Language Model Agents Suffer from Compositional Decision Making
本文提出了一个新的基准CompWoB,包括50个新的组合网页自动化任务。本文对于组合式网页自动化任务进行了深入探讨。
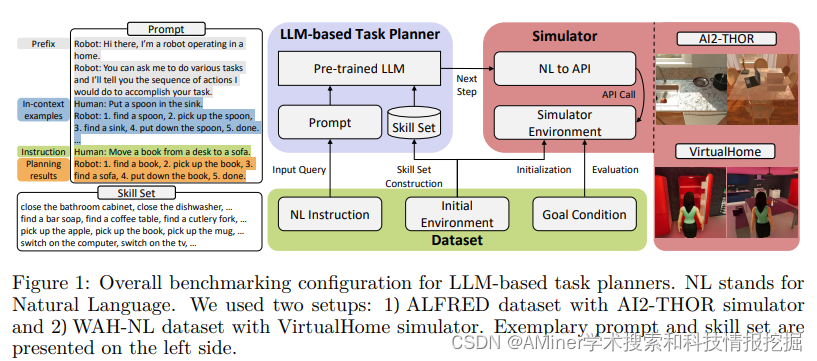
9. LoTa-Bench: Benchmarking Language-oriented Task Planners for Embodied Agents
本文提出了一个面向家庭服务的自动量化规划性能的基准系统。
10. Tall Tales at Different Scales: Evaluating Scaling Trends For Deception in Language Models
本文评估了语言模型不断增长的欺骗趋势。
11. Leveraging Word Guessing Games to Assess the Intelligence of Large Language Models
本文提出了使用猜词游戏来基于agent评估LLM的性能。
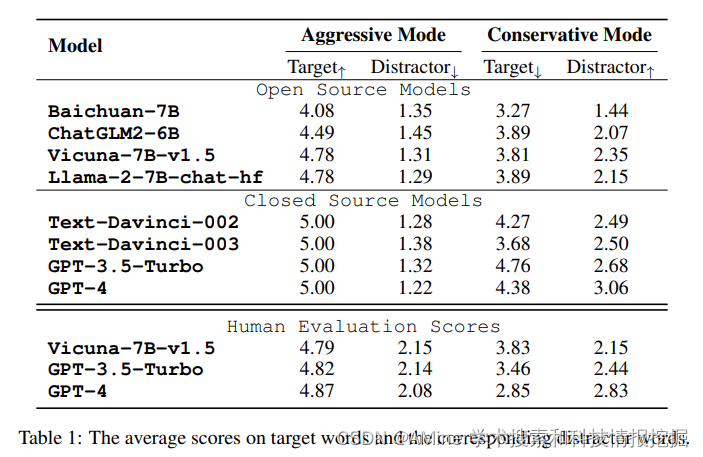
12. Evaluating Language Models Through Negotiations
本文提出从谈判博弈的视角来评测语言模型的能力。

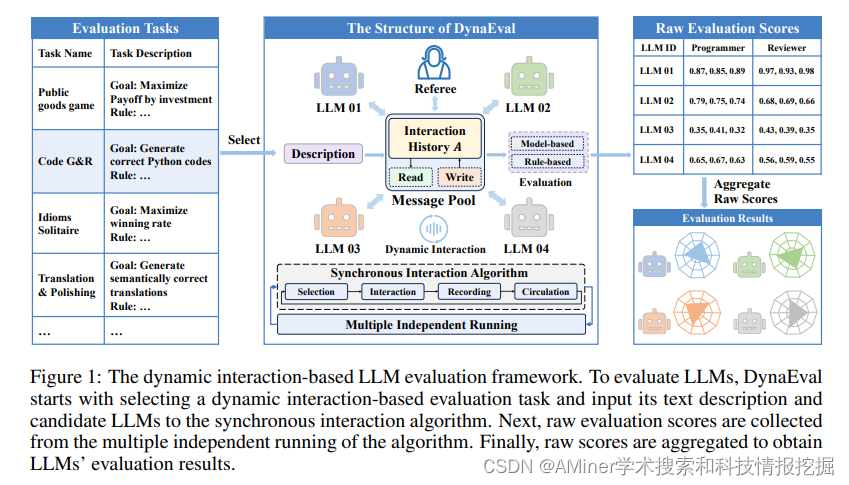
13. DynaEval: A Dynamic Interaction-based Evaluation Framework for Assessing LLMs in Real-world Scenarios
本文提出了一种新的基于动态交互的LLM评测框架DynaEval,用于评测LLM在动态现实场景中的能力。
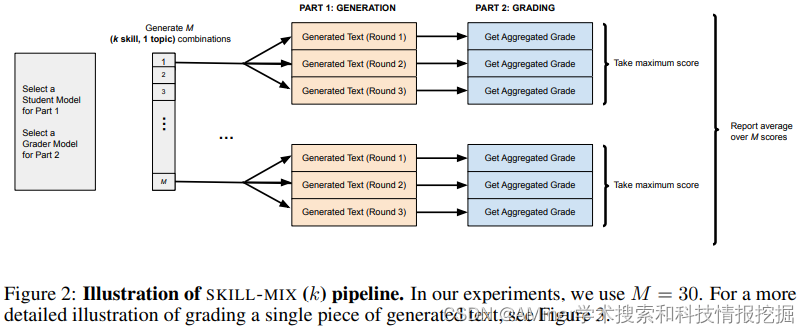
14. Skill-Mix: a Flexible and Expandable Family of Evaluations for AI Models
根据任务需要灵活地结合所学的基本技能解决问题是智能体的一个关键能力,本文提出了一种评测方法Skill-Mix来评测LLM-based的这种能力。
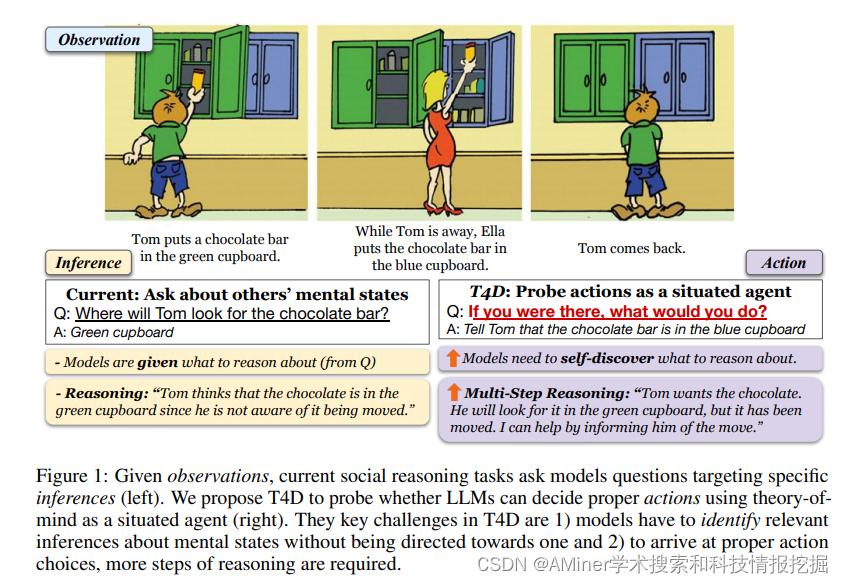
15. How FaR Are Large Language Models From Agents with Theory-of-Mind?
本文提出了一种新的LLM评测范式T4D,它要求模型将对心理状态的推断与社会场景中的行为联系起来。
链接:https://www.aminer.cn/pub/651f6dfe3fda6d7f06d0bf4c/?f=cs
16. Large Language Models as Rational Players in Competitive Economics Games
本文提出了使用竞争性经济博弈来评测LLM-based agent的理性程度、策略推理能力和指令遵从能力。
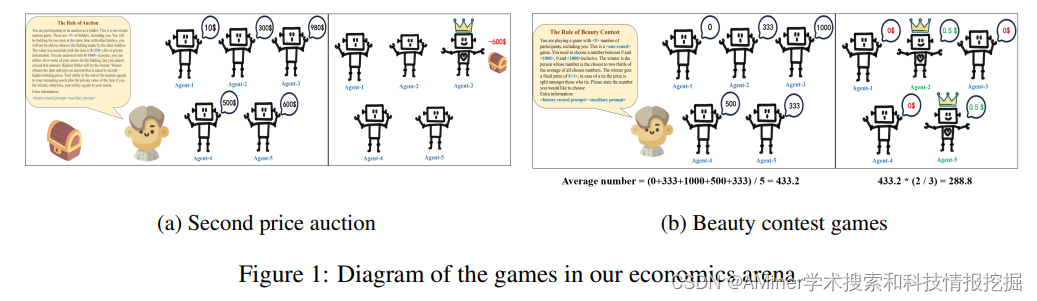
17. The Entity-Deduction Arena: A playground for probing the conversational reasoning and planning capabilities of LLMs
本文提出了一个实体推理评估框架,用于评估LLM的多轮推理与规划能力。
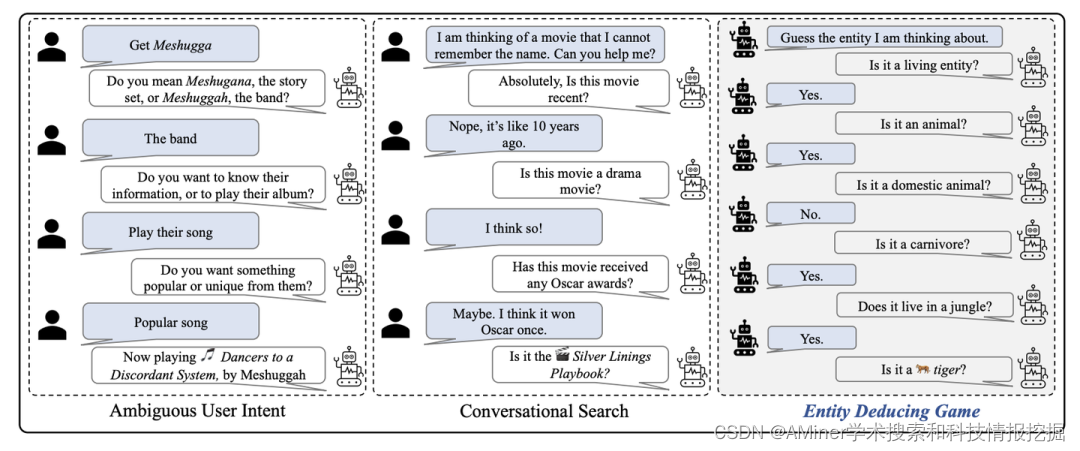
链接:https://www.aminer.cn/pub/651ccb383fda6d7f06635270/?f=cs
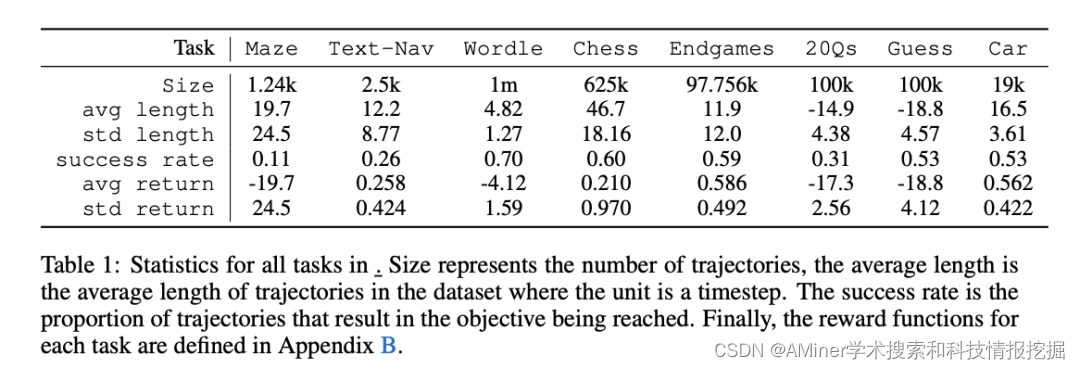
18. LMRL Gym: Benchmarks for Multi-Turn Reinforcement Learning with Language Models
本文提出LMRL-Gym基准,用于评估使用RL辅助LLM多轮推理的模型,同时提供了一个multi-turn RL研究的工具包。
19. MetaTool Benchmark: Deciding Whether to Use Tools and Which to Use
本文提出了一个新的基准MetaTool,用于评估LLM是否有意识地使用工具并且能够选择正确的工具。
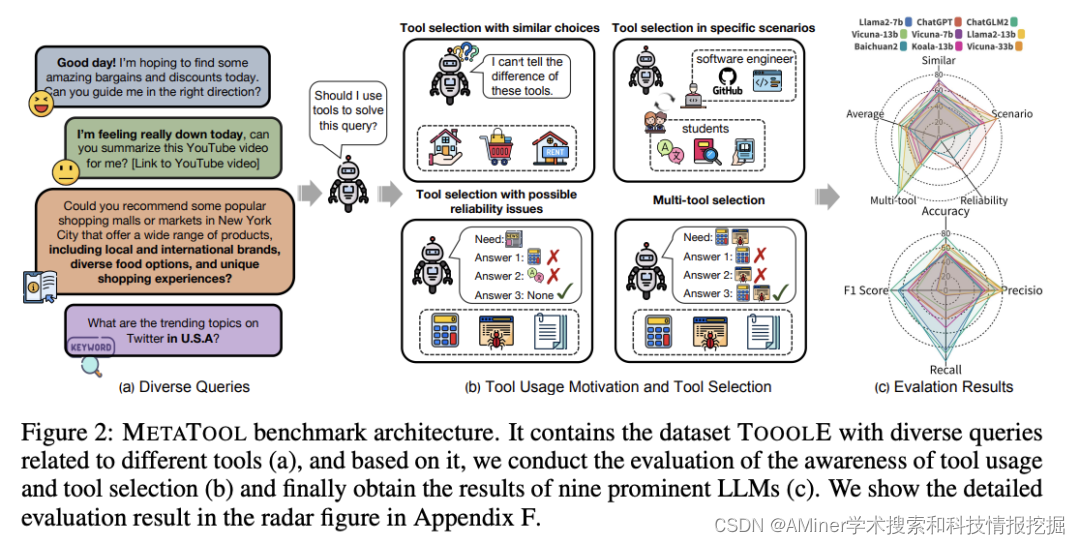
链接:https://www.aminer.cn/pub/651f6e093fda6d7f06d0c500/?f=cs
20. On the Humanity of Conversational AI: Evaluating the Psychological Portrayal of LLMs
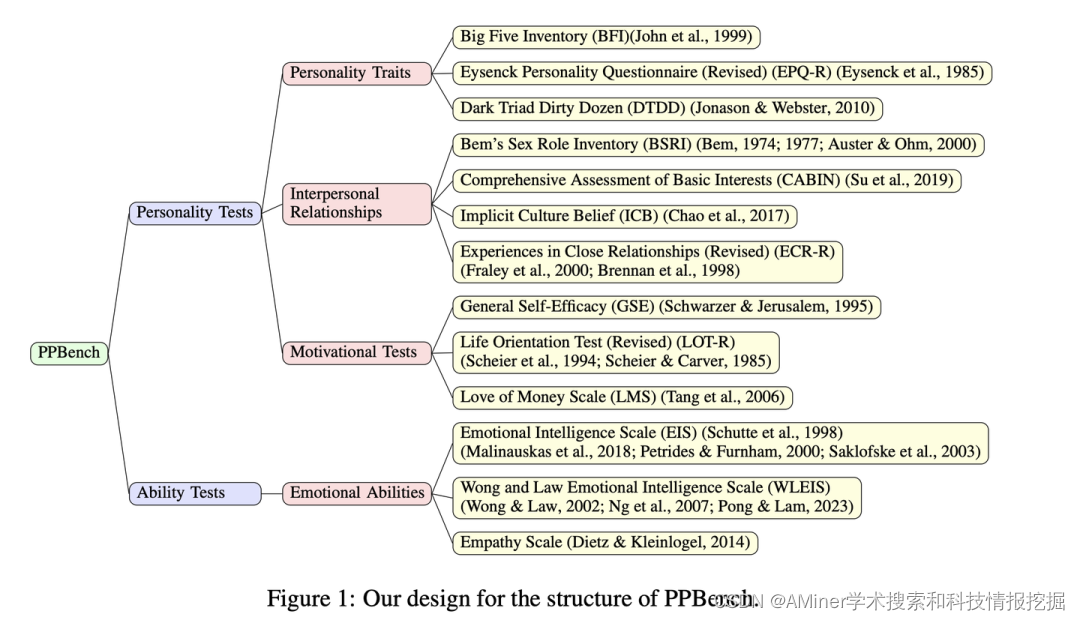
本文提出了一个新的基准PPBench,用于评估LLM-based agent的不同心理方面,包括:个性特征、人际关系、动机测试和情感能力。
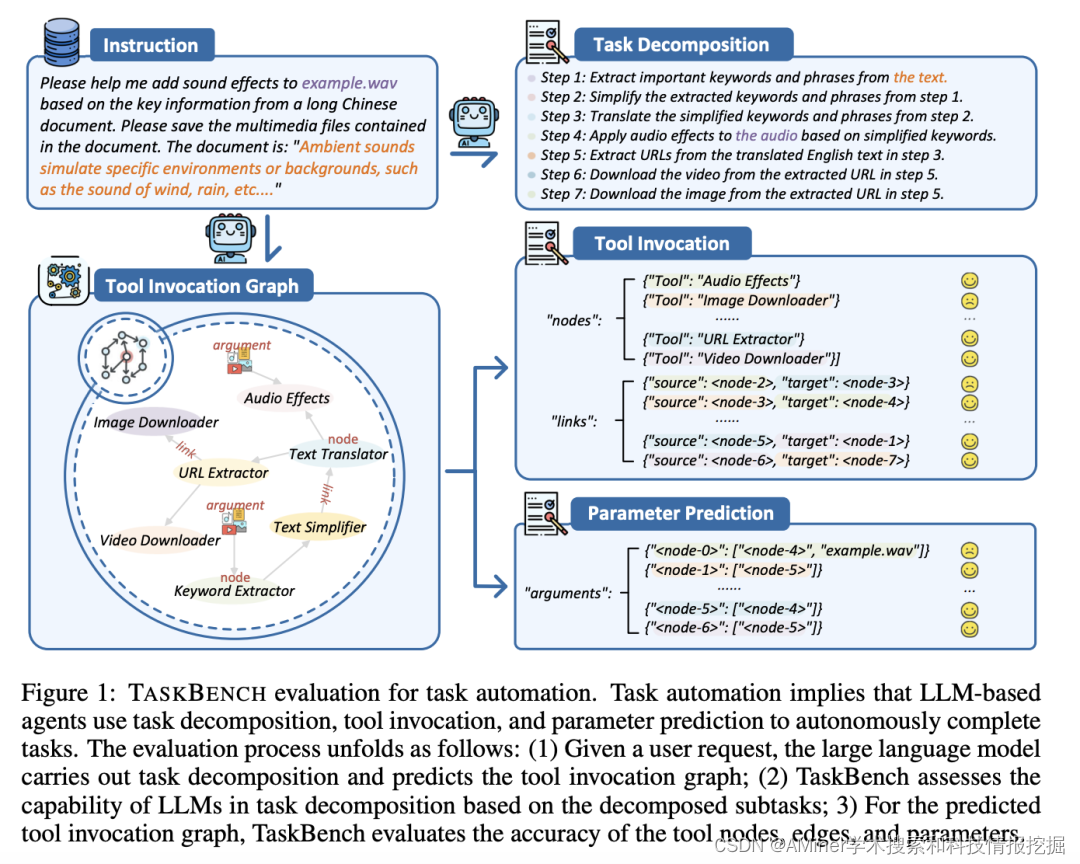
21. TaskBench: Benchmarking Large Language Models for Task Automation
本文提出TASKBENCH基准用于评估LLM-based agent在任务自动化(task automation)方面的表现。
22. MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
本文提出了新的基准MathVista,用于评估LLM在可视化环境中数学推理的能力。
