说明:部分来源于网络教程,如有侵权请联系本人删除相关内容
教程连接:2.2输入部分实现-part1_哔哩哔哩_bilibili
输入部分包含:
1.源文本嵌入层以及位置编码器
2.目标文本嵌入层以及位置编码器
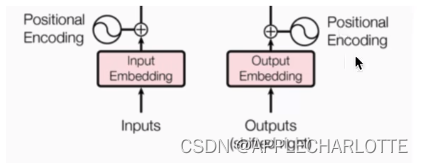
嵌入层作用:其实也是一个编码器,将词汇编码为一个向量(典型算法:独热向量onehot)
嵌入层代码实现:
首先需要了解nn.Embedding模块:
torch.nn.Embedding(num_embeddings,embedding_dim,padding_idx=None,
max_norm=None,norm_type=2.0,scale_grad_by_freq=False,
sparse=False,_weight=None)
参数解释:(来自简书:top_小酱油)
num_embeddings (python:int) – 词典的大小尺寸,比如总共出现1000个词,那就输入1000。
embedding_dim (python:int) – 嵌入向量的维度,即用多少维来表示一个符号。
padding_idx (python:int, optional) – 填充id,比如,输入长度为100,但是每次的句子长度并不一样,后面就需要用统一的数字填充,而这里就是指定这个数字,这样,网络在遇到填充id时,就不会计算其与其它符号的相关性。(初始化为0)
max_norm (python:float, optional) – 最大范数,如果嵌入向量的范数超过了这个界限,就要进行再归一化。
norm_type (python:float, optional) – 指定利用什么范数计算,并用于对比max_norm,默认为2范数。
scale_grad_by_freq (boolean, optional) – 根据单词在mini-batch中出现的频率,对梯度进行放缩。默认为False.
sparse (bool, optional) – 若为True,则与权重矩阵相关的梯度转变为稀疏张量。
嵌入层代码实现:
import torch
import torch.nn as nn
import math
from torch.autograd import Variable
#定义Embeddings类来实现文本嵌入层
class Embeddings(nn.Module):
def __init__(self,d_model,vocab):
#两个参数:d_model指词嵌入的维度,vocab:指词表的大小
super(Embeddings,self).__init__()
self.lut = nn.Embedding(vocab,d_model)
self.d_model = d_model
def forward(self,x):
#参数x:代表输入给模型的文本通过词汇映射后的张量
return self.lut(x) * math.sqrt(self.d_model)下面看位置编码器:
因为在Transformer的编码器结构中没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器。
位置编码器代码:
#定义位置编码器类
class PositionalEncoding(nn.Module):
def __init__(self,dims,dropout,max_len=5000):
# dims:单词的维度;max_len:句子的最大长度
super(PositionalEncoding,self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 初始化位置编码矩阵
pe = torch.zeros(max_len,dims)
# 定义一个绝对位置矩阵,形状为(max_len,1),unsqueeze的作用是扩展维度
position = torch.arange(0,max_len).unsqueeze(1)
# 将绝对位置矩阵信息加入到位置编码矩阵中,需要一个1xdims形状的变换矩阵
div_term = torch.exp(torch.arange(0,dims,2) * -(math.log(10000.0)/dims))
pe[:,0::2] = torch.sin(position * div_term)
pe[:,1::2] = torch.cos(position * div_term)
# 这样我们得到了位置编码矩阵pe,但是想要和embedding输出结合就必须扩展一个维度
pe = pe.unsqueeze(0)
# 最后把pe位置编码矩阵注册成模型的buffer,buffer也就是:对模型效果有帮助,但是不是模型结构的超参数或者参数,不需要随着优化步骤更新
# 注册之后可以在模型保存后重加载时和模型结构与参数一同被加载
self.register_buffer('pe',pe)
def forward(self,x):
# x表示文本序列的词嵌入表示
x = x + Variable(self.pe[:,:x.size(1)],requires_grad=False)
return self.dropout(x)经过嵌入层和位置编码器之后,最终输出为一个加入了位置编码信息的词嵌入张量。
位置编码器的优点:保证同一词汇随着所在位置不同它对应的位置嵌入向量会发生变化
正弦波和余弦波的值域范围都是1到-1,控制了嵌入数值的大小,有助于梯度快速计算