1. 网络架构
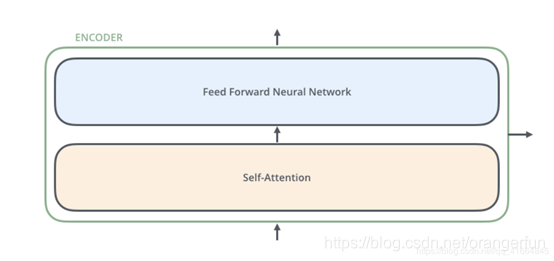
整个网络由2个部分组成,一个Encoders和一个Decoders,每个Encoders中分别由6个Encoder组成,而每个Decoders中同样也是由6个Decoder组成,如下图所示

对于Encoders中的每一个Encoder,他们结构都是相同的,但是并不会共享权值。每层Encoder有2个部分组成,如图1.2所示。每个Encoder的输入首先会通过一个self-attention层,通过self-attention层帮助Endcoder在编码单词的过程中查看输入序列中的其他单词;Self-attention的输出会被传入一个全连接的前馈神经网络,每个encoder的前馈神经网络参数个数都是相同的,但是他们的作用是独立的。
每个Decoder也同样具有这样的层级结构,但是在这之间除了有self-attention还有另外一个Attention层,帮助当前节点获取到当前需要关注的重点内容(类似与seq2seq models的结构)
2. 数据流动
首先还是NLP的常规做法,先做一个词嵌入,将每个单词编码为一个512维度的向量,我们用图2.1所示这张简短的图形来表示这些向量;词嵌入的过程只发生在最底层的Encoder。但是对于所有的Encoder来说,你都可以按下图来理解。输入(一个向量的列表,每个向量的维度为512维,在最底层Encoder作用是词嵌入,其他层就是其前一层的output)。另外这个列表的大小和词向量维度的大小都是可以设置的超参数。一般情况下,它是我们训练数据集中最长的句子的长度。
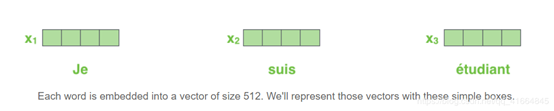
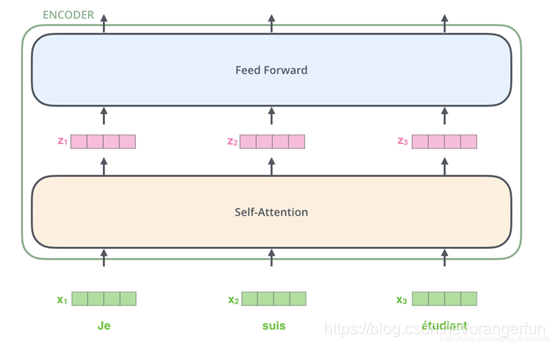
图2.2介绍了一个Transformer的关键点,在每个单词进入Self-Attention层后都会有一个对应的输出。Self-Attention层中的输入和输出是存在依赖关系的,而前馈层则没有依赖,所以在前馈层,我们可以用到并行化来提升速率。
2.1 Encoding
Transformer中的每个Encoder接收一个512维度的向量的列表作为输入,然后将这些向量传递到‘self-attention’层,self-attention层产生一个等量512维向量列表,然后进入前馈神经网络,前馈神经网络的输出也为一个512维度的列表,然后将输出向上传递到下一个encoder,如图2.2.1所示,每个位置的单词首先会经过一个self attention层,然后每个单词都通过一个独立的前馈神经网络(这些神经网络结构完全相同)。
2.2 self - attention
什么是self-Attention?
假设下面的句子就是我们需要翻译的输入句:”The animal didn’t cross the street because it was too tired” 这句话中的"it"指的是什么?它指的是“animal”还是“street”?对于人来说,这其实是一个很简单的问题,但是对于一个算法来说,处理这个问题其实并不容易。self attention的出现就是为了解决这个问题,通过self attention,我们能将“it”与“animal”联系起来。当模型处理单词的时候,self attention层可以通过当前单词去查看其输入序列中的其他单词,以此来寻找编码这个单词更好的线索。
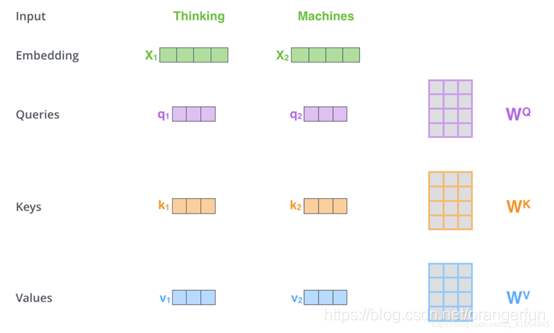
计算self attention的第一步是从每个Encoder的输入向量上创建3个向量(在这个情况下,对每个单词做词嵌入)。所以,对于每个单词,我们创建一个Query向量,一个Key向量和一个Value向量。这些向量是通过词嵌入乘以我们训练过程中创建的3个训练矩阵而产生的(这三训练矩阵是随机初始化的)。
注意这些新向量的维度比嵌入向量小。我们知道嵌入向量的维度为512,而这里的新向量的维度只有64维。新向量并不是必须小一些,这是网络架构上的选择使得Multi-Headed Attention(大部分)的计算不变。
如图2.2.1所示,我们将
乘以
的权重矩阵得到新向量
,
就是“query”的向量。同理,最终我们可以对输入句子的每个单词创建“query”,“key”,“value”的新向量表示形式。
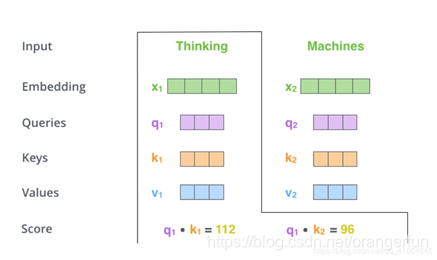
计算self attention的第二步是计算得分。以上图为例,假设我们在计算第一个单词“thinking”的self attention。我们需要根据这个单词对输入句子的每个单词进行评分。当我们在某个位置编码单词时,分数决定了对输入句子的其他单词的关照程度。
通过将query向量和key向量点击来对相应的单词打分。所以,如果我们处理开始位置的的self attention,则第一个分数为
和
的点积,第二个分数为
和
的点积。如图2.2.2
第三步和第四步的计算,是将第二部的得分除以8(
)(论文中使用key向量的维度是64维,其平方根=8,这样可以使得训练过程中具有更稳定的梯度。这个
并不是唯一值,经验所得)。然后再将得到的输出通过softmax函数标准化,使得最后的列表和为1。如图2.2.3
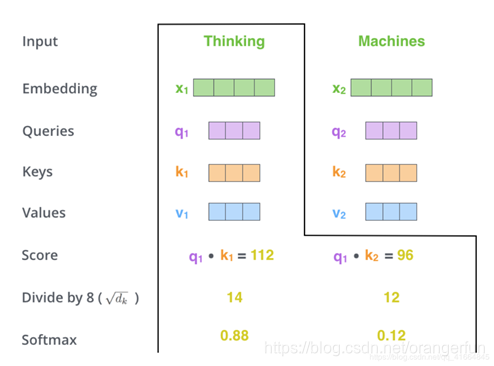
这个softmax的分数决定了当前单词与句子中每个位置的单词的相关程度。很明显,当前单词对应句子中此单词所在位置的softmax的分数最高,但是,有时候attention机制也能关注到此单词外的其他单词,这很有用。
第五步是将每个Value向量乘以softmax后的得分。这里实际上的意义在于保存对当前词的关注度不变的情况下,降低对不相关词的关注。
第六步是 累加加权值的向量。 这会在此位置产生self-attention层的输出(对于第一个单词),如图2.2.4
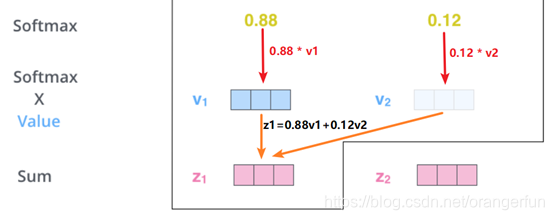
总结self-attention的计算过程,就是将每个单词的“词嵌入”相互点积得到每个单词之间的“相似度”,这个相似度其实就是上面提到的得分,将这些得分softmax后就成为每个单词的权重,最后利用这个权重对所有的“词向量”加权和,这样一个单词中就融合其他单词(也就是上下文)含义,如果某个单词V的得分高,那么它的权重就会更大,从而当前单词对词V就更加关注。在(单词级别)就是得到一个我们可以放到前馈神经网络的矢量。 然而在实际的实现过程中,该计算会以矩阵的形式完成,以便更快地处理。下面我们来看看Self-Attention的矩阵计算方式。
2.3 self-attention 矩阵计算
第一步是去计算Query,Key和Value矩阵。我们将词嵌入转化成矩阵X中,并将其乘以我们训练的权值矩阵
,如图2.2.3.1所示
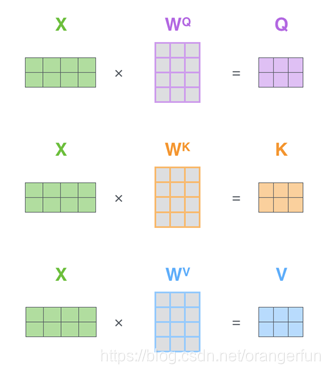
X矩阵中的每一行对应于输入句子中的一个单词。 我们看到的X每一行的方框数实际上是词嵌入的维度,图中所示的和论文中是有差距的。X(图中的4个方框论文中为512个)和q / k / v向量(图中的3个方框论文中为64个)
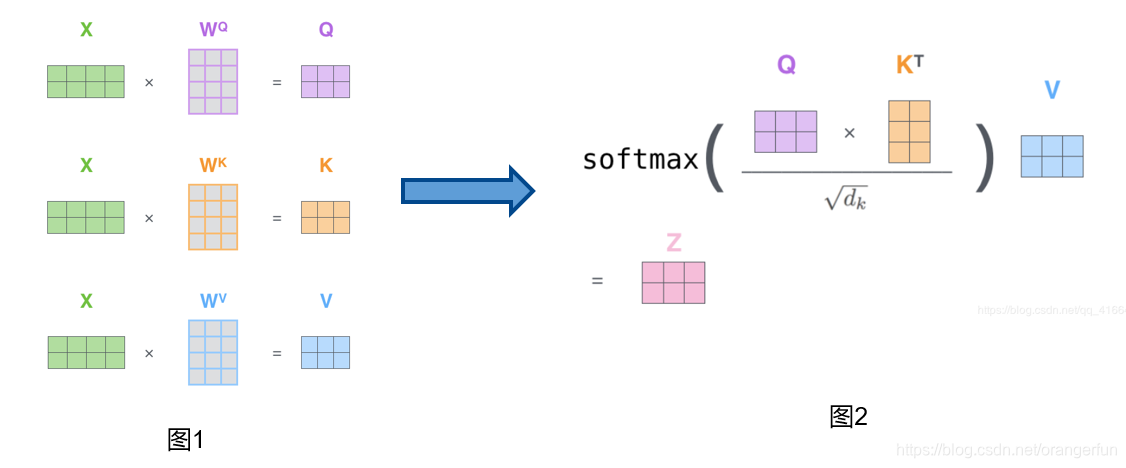
最后,由于我们正在处理矩阵,我们可以在一个公式中浓缩前面步骤2到6来计算self attention层的输出。如图2.2.3.2所示
2.4 Multi-head
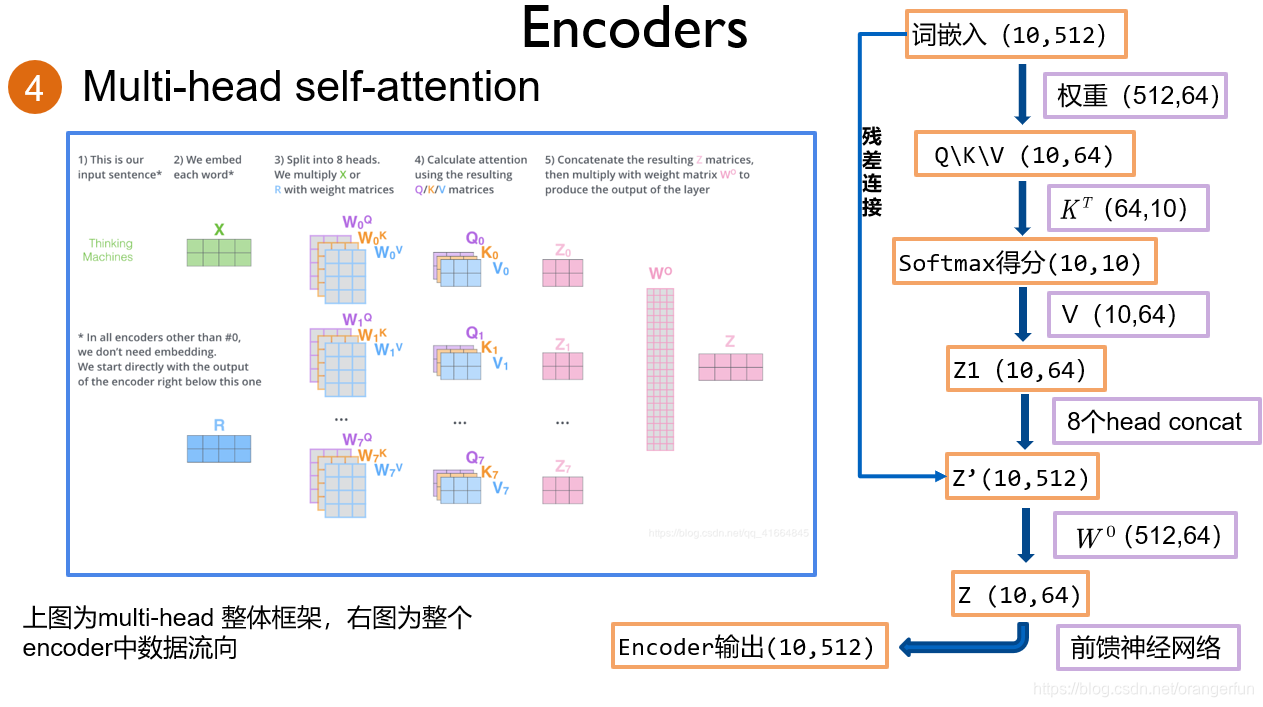
使用“Multi-headed”的机制来进一步完善self attention层。“Multi-headed”主要通过下面2种方式改善了attention层的性能:
(1). 它拓展了模型关注不同位置的能力。在上面例子中可以看出,The animal didn’t cross the street because it was too tired,我们的attention机制计算出it指代的为animal,这在对语言的理解过程中是很有用的。
(2).它为attention层提供了多个“representation subspaces”。由图2.4.1可以看到,在self attention中,我们有多个Query / Key / Value权重矩阵(Transformer使用8个attention heads)。这些集合中的每个矩阵都是随机初始化生成的。然后通过训练,用于将词嵌入(或者来自较低Encoder/Decoder的矢量)投影到不同的“representation subspaces(表示子空间)”中。
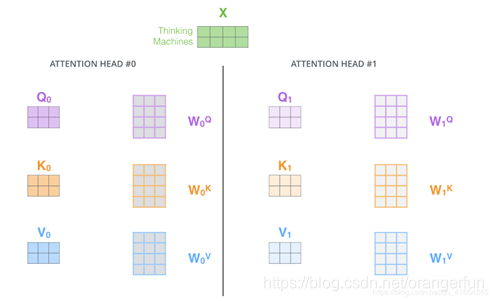
通过multi-headed attention,我们为每个header都独立维护一套Q/K/V的权值矩阵。然后我们还是如之前单词级别的计算过程一样处理这些数据。如果对上面的例子做同样的self attention计算,而因为我们有8头attention,所以我们会在八个时间点去计算这些不同的权值矩阵,但最后结束时,我们会得到8个不同的Z矩阵。如图2.4.2所示
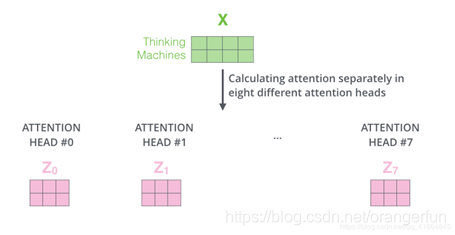
在self-attention后面紧跟着的是前馈神经网络,而前馈神经网络接受的是单个矩阵向量,而不是8个矩阵。所以我们需要一种办法,把这8个矩阵压缩成一个矩阵。我们将这8个矩阵连接在一起然后再与一个矩阵
相乘。步骤如图2.4.3所示,
也是随机初始化
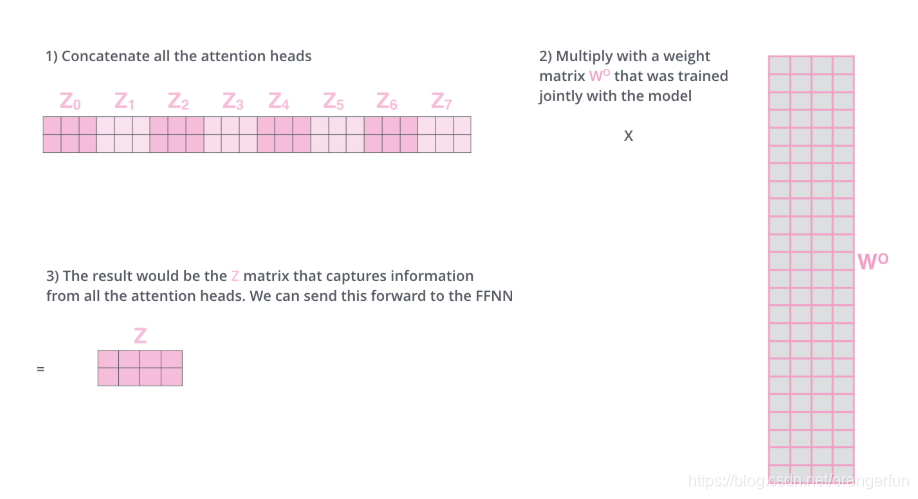
图2.4.4是一个整体的框图来表示一下计算的过程
2. 位置编码
考虑输入句子中单词顺序问题,transformer给每个输入单词的词嵌入上添加了一个新向量——位置向量,如图2.1所示,然后与Q/K/V向量点击,获得的attention就有了距离的信息了。
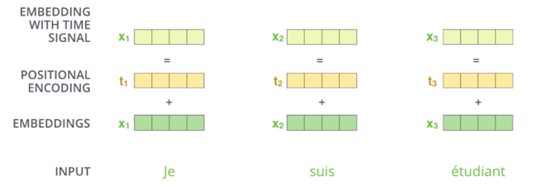
Positional Encoding,维度和embedding的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。这个位置向量的具体计算方法如下:
其中pos是指当前词在句子中的位置,i是指向量中每个值的index,贴个代码更容易理解:
position_encoding = np.array(
[[pos / np.power(10000, 2.0 * (j // 2) / d_model) for j in range(d_model)] for pos in range(max_seq_len)])
位置编码也还有其他方式,此处不在讲解
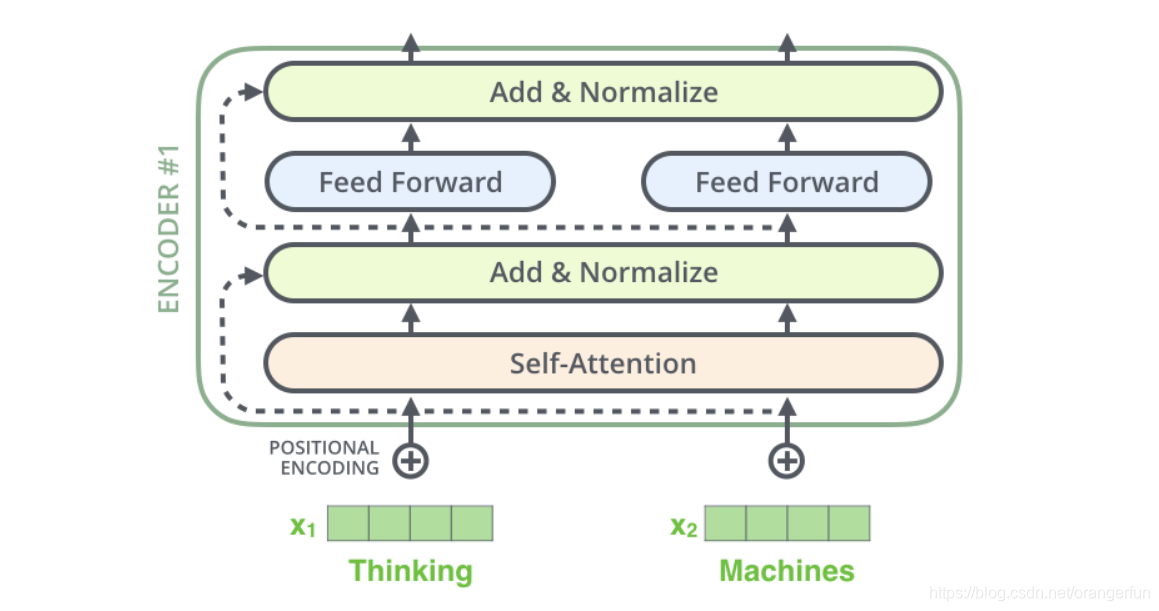
3. 残差连接 & Normalization
在transformer中,每一个子层(self-attetion,ffnn)之后都会接一个残缺模块,并且有一个Layer normalization如图3.1所示。Normalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0方差为1的数据。我们在把数据送入激活函数之前进行normalization(归一化),因为我们不希望输入数据落在激活函数的饱和区。两者的作用都是防止梯度消失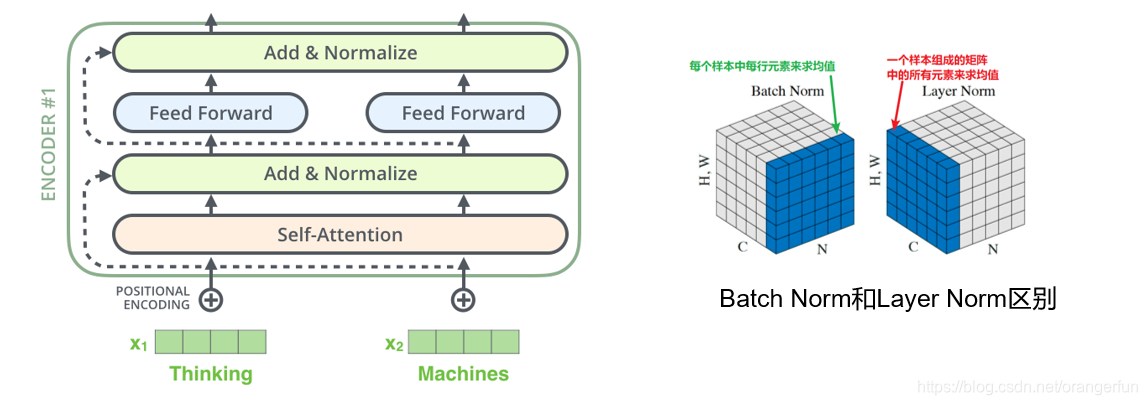
假设我们的输入是一个minibatch的数据,我们再假设每一个数据都是一个向量,则输入是一个矩阵,每一行是一个训练数据,每一列都是一个特征。BatchNorm是对每个特征进行Normalization,而LayerNorm是对每个样本的不同特征进行Normalization,因此LayerNorm的输入可以是一行(一个样本)。
如下图所示,输入是(3,6)的矩阵,minibatch的大小是3,每个样本有6个特征。BatchNorm会对6个特征维度分别计算出6个均值和方差,然后用这两个均值和方差来分别对6个特征进行Normalization,计算公式如下:

而LayerNorm是分别对3个样本的6个特征求均值和方差,因此可以得到3个均值和方差,然后用这3个均值和方差对3个样本来做Normalization,计算公式如下:

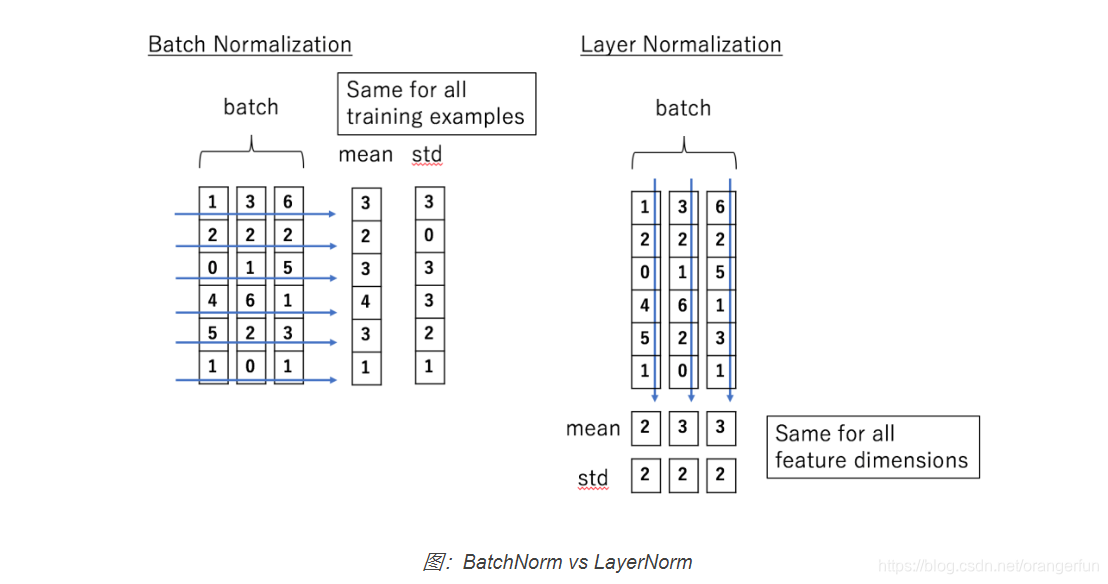
因为LayerNorm的每个样本都是独立计算的,因此minibatch可以很小甚至可以是1。实验证明LayerNorm不仅在普通的神经网络中有效,而且对于RNN也非常有效。
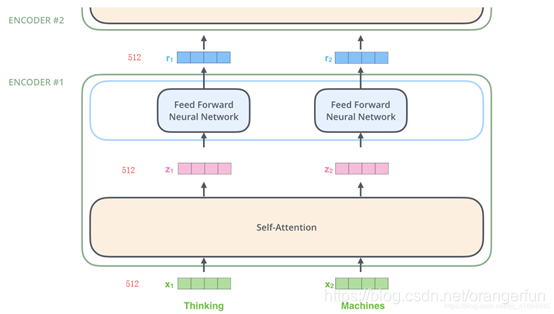
每个Self-Attention层都会加一个残差连接,然后是一个LayerNorm层,如下图所示。
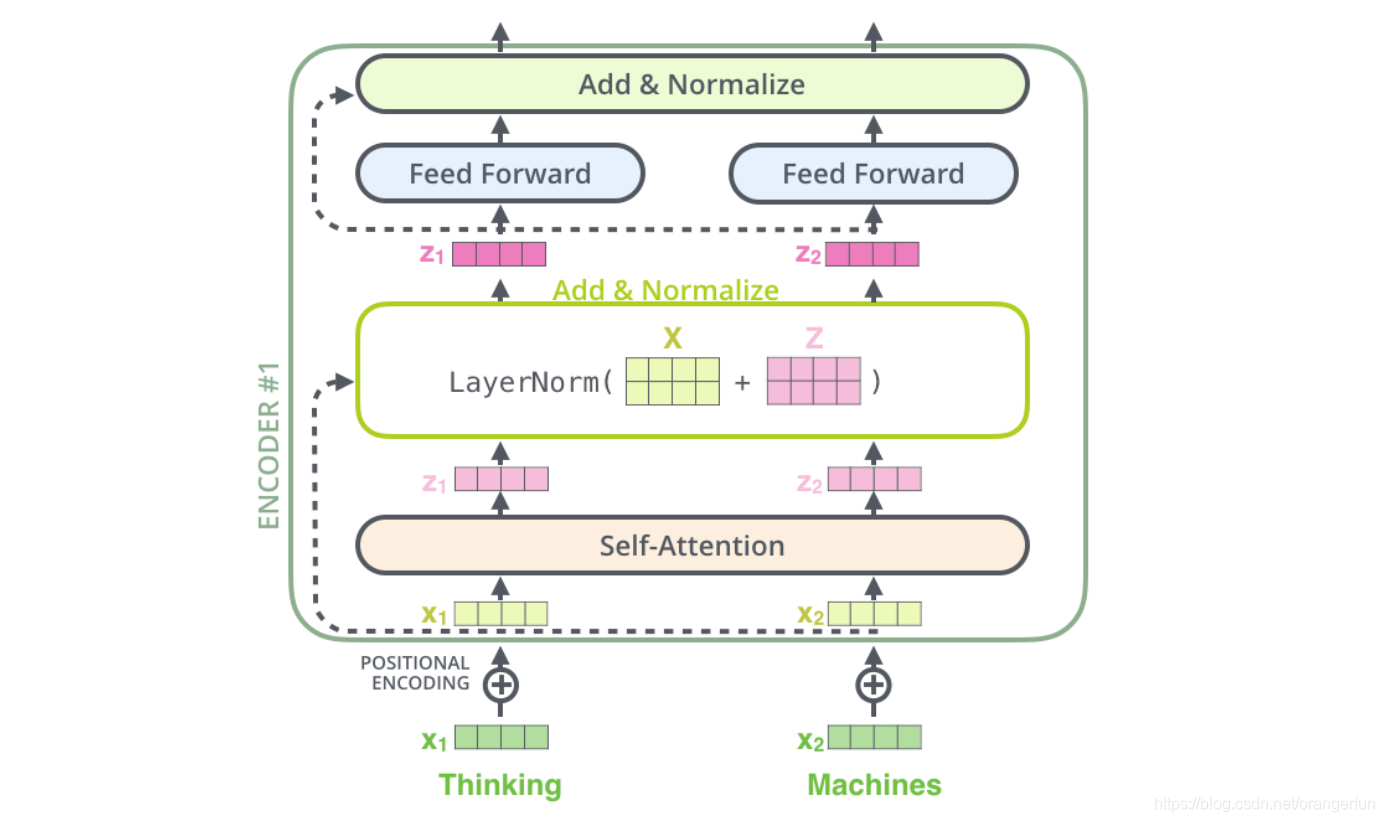
下图展示了更多细节:输入
,
经self-attention层之后变成
,
,然后和残差连接的输入
,
加起来,然后经过LayerNorm层输出给全连接层。全连接层也是有一个残差连接和一个LayerNorm层,最后再输出给上一层。
4. MASK
mask表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer模型里面涉及两种mask,分别是padding mask和sequence mask。其中,padding mask在所有的scaled dot-product attention里面都需要用到,而sequence mask只有在decoder的self-attention里面用到。
(1)padding mask
由于每个批次输入序列长度是不一样的,因此需要对输入序列进行对齐。即给较短的序列后面填充0,截取较长序列左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,可以在这些位置上加一个非常大的负数(负无穷),这样的话,经过softmax,这些位置的概率就会接近0。padding mask实际上是一个张量,每个值都是一个Boolean,值为false的地方就是我们要进行处理的地方。
(2)sequence mask
sequence mask是为了使得 decoder时不能看见未来的信息。也就是对于一个序列,在time_step为t的时刻,我们的解码输出应该只能依赖于t时刻之前的输出,而不能依赖t之后的输出。因此我们需要想一个办法,把t之后的信息给隐藏起来。具体做法是产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
对于decoder的self-attention,里面使用到的scaled dot-product attention,同时需要padding mask和sequence mask作为attn_mask,具体实现就是两个mask相加作为attn_mask。其他情况,attn_mask一律等于 padding mask
6. decoder
Decoders的结构和Encoder的结构大致都相同,就是比Encoders中多了一个Encoder-Decoder Attention子层

decoder中包含以下几部分:
(1)self-attention
Decoder中self-Attention和Encoder中的结构一样,首先还是将Y进行词嵌入,然后进行self-Attention
Decoder中的self attention与Encoder的self attention略有不同; 在Decoder中,self attention只关注输出序列中的较早的位置。这是在self attention计算时softmax步骤之前屏蔽了特征位置(设置为 -inf)来完成的
(2)encoder-decoder attention
Encoder-Decoder Attention 过程和self-Attention基本相同,唯一区别是queries矩阵是上一个self-attention子层的输出,keys,value矩阵是encoders的输出,因此Encoder-Decoder Attention能够帮助当前节点获取到当前需要关注的重点内容,类似于Seq2Seq中的Attention
(3)训练和预测时decoder的输入
在训练时英文对应的Label(中文)作为Decoder的输入
在预测时,第一次是将特殊标志符< s >作为输入表示开始解码,之后每次都将前一次的预测输出作为后面的输入
7. 输出层
当decoder层全部执行完毕后,需要在结尾再添加一个全连接层和softmax层,假如我们的词典是1w个词,那最终softmax会输出1w个词的概率,概率值最大的对应的词就是我们最终的结果。

8.参考
[1]. Transformer图解
[2]. Attention Is All You Need
