要弄清楚Decoder的输入输出,关键在于图示三个箭头的位置:

以翻译为例:
- 输入:我爱中国
- 输出: I Love China
因为输入(“我爱中国”)在Encoder中进行了编码,这里我们具体讨论Decoder的操作,也就是如何得到输出(“L Love China”)的过程。
训练过程中是Decoder初始输入是输入对应的真实输出
推理过程中是Decoder初始输入是输入经过decoder后的预测输出
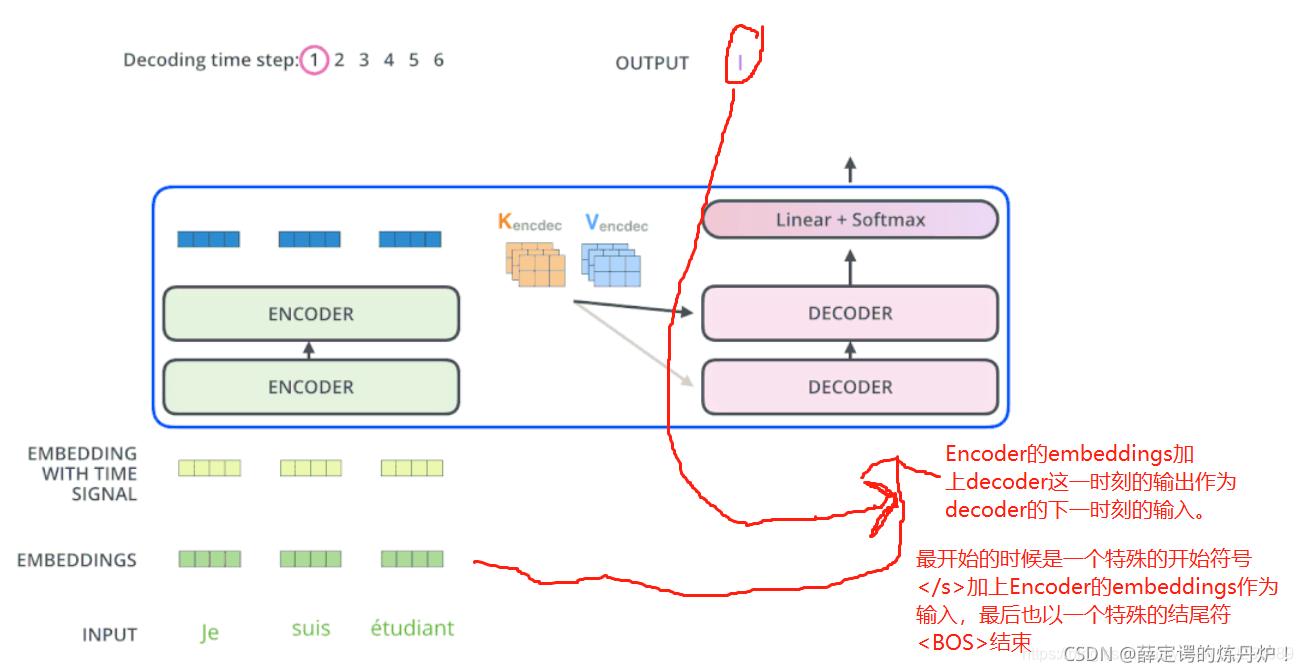
Decoder执行步骤(推理过程)
Time Step 1
-
- 初始输入: 起始符</s> + Positional Encoding(位置编码)
- 中间输入: 整个Encoder Embedding【也就是“我爱中国”的Embedding】
- 最终输出:产生预测“I”
Time Step 2
-
- 初始输入:起始符</s> + “I”+ Positonal Encoding
- 中间输入:整个Encoder Embedding【也就是“我爱中国”的Embedding】
- 最终输出:产生预测“Love”
Time Step 3
-
- 初始输入:起始符</s> + “I”+ “Love”+ Positonal Encoding
- 中间输入:整个Encoder Embedding【也就是“我爱中国”的Embedding】
- 最终输出:产生预测“China”

为什么整体右移一位(Shifted Right)
回答:在输出(Decoder的输入)前添加起始符,方便预测第一个Token

细心的同学会发现论文在Decoder的输入上,对Outputs有Shifted Right操作。
Shifted Right 实质上是给输出(Decoder的输入)添加起始符/结束符,方便预测第一个Token/结束预测过程。
正常的输出序列位置关系如下:
- 0-"I"
- 1-"Love"
- 2-"China"
但在执行的过程中,我们在初始输出(Decoder的输入)中添加了起始符</s>,相当于将输出整体右移一位(Shifted Right),所以输出序列变成如下情况:
- 0-</s>【起始符】
- 1-“I”
- 2-“Love”
- 3-“China”
这样我们就可以通过起始符</s>预测“I”,也就是通过起始符预测实际的第一个输出。
(预测时候Decoder是怎么输入?)transformer 模型的decoder部分 带gif动图_decoder动态图_薛定谔的炼丹炉!的博客-CSDN博客