Transformer就是一个,Sequence-to-sequence的model,他的缩写,我们会写做Seq2seq,那Sequence-to-sequence的model,又是什麼呢
我们之前在讲input a sequence的,case的时候,我们说input是一个sequence,那output有几种可能
- 一种是input跟output的长度一样
- 我们不知道应该要output多长,由机器自己决定output的长度,即Seq2seq
- 举例来说,Seq2seq一个很好的应用就是 语音辨识
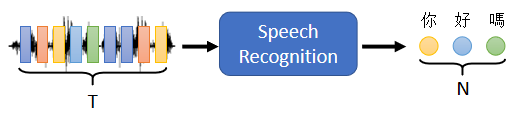
在做语音辨识的时候,输入是声音讯号,声音讯号其实就是一串的vector,输出是语音辨识的结果,也就是输出的这段 声音讯号,所对应的文字
我们这边用圈圈来代表文字,每一个圈圈就代表,比如说中文裡面的一个方块子,今天输入跟输出的长度,当然是有一些关係,但是却没有绝对的关係,输入的声音讯号,他的长度是大T,我们并没有办法知道说,根据大T输出的这个长度N一定是多少。
输出的长度由机器自己决定,由机器自己去听这段声音讯号的内容,自己决定他应该要输出几个文字,他输出的语音辨识结果,输出的句子裡面应该包含几个字,由机器自己来决定,这个是语音辨识
- 还有很多其他的例子,比如说机器翻译

语音翻译就是,你对机器说一句话,比如说machine learning,他输出的不是英文,他直接把他听到的英文的声音讯号翻译成中文文字
你对他说machine learning,他输出的是机器学习
机器听到的声音是这样子的
- 你的身体撑不住(台语),那机器输出是什麼呢,它的输出是 你的身体撑不住,这个声音讯号是你的身体撑不住(台语),但机器并不是输出无勘,而是它就输出撑不住
- 或者是机器听到的,是这样的声音讯号,没事你為什麼要请假(台语),没事你為什麼要请假,机器听到没事(台语),它并不是输出 没代没誌,它是输出 没事,这样听到四个音节没代没誌(台语),但它知道说台语的没代没誌(台语),翻成中文 也许应该输出 没事,所以机器的输出是,没事你為什麼要请假
- 但机器其实也是蛮容易犯错的,底下特别找机个犯错的例子,给你听一下,你听听这一段声音讯号,不会腻吗(台语),他说不会腻吗(台语),我自己听到的时候我觉得,我跟机器的答案是一样的,就是说要生了吗,但其实这句话,正确的答案就是,不会腻吗(台语),不会腻吗
- 当然机器在倒装,你知道有时候你从台语,转成中文句子需要倒装,在倒装的部分感觉就没有太学起来,举例来说它听到这样的句子,我有跟厂长拜託(台语),他说我有跟厂长拜託(台语),那机器的输出是,我有帮厂长拜託,但是你知道说这句话,其实是倒装,我有跟厂长拜託(台语),是我拜託厂长,但机器对於它来说,如果台语跟中文的关係需要倒装的话,看起来学习起来还是有一点困难
- 这个例子想要告诉你说,直接台语声音讯号转繁体中文,不是没有可能,是有可能可以做得到的,那其实台湾有很多人都在做,台语的语音辨识,如果你想要知道更多有关,台语语音辨识的事情的话,可以看一下下面这个网站

Text-to-Speech (TTS) Synthesis : 语音合成
Seq2seq for Chatbot : 聊天机器人

- 假设你今天想做的是翻译,那机器读的文章就是一个英文句子,问题就是这个句子的德文翻译是什麼,然后输出的答案就是德文
- 或者是你想要叫机器自动作摘要,摘要就是给机器读一篇长的文章,叫他把长的文章的重点节录出来,那你就是给机器一段文字,问题是这段文字的摘要是什麼,然后期待他答案可以输出一个摘要
- 或者是你想要叫机器做Sentiment analysis,Sentiment analysis就是机器要自动判断一个句子,是正面的还是负面的;假设你有做了一个產品,然后上线以后,你想要知道网友的评价,但是你又不可能一直找人家ptt上面,把每一篇文章都读过,所以就做一个Sentiment analysis model,看到有一篇文章裡面,有提到你的產品,然后就把这篇文章丢到,你的model裡面,去判断这篇文章,是正面还是负面。你就给机器要判断正面还负面的文章,问题就是这个句子,是正面还是负面的,然后希望机器可以告诉你答案
所以各式各样的NLP的问题,往往都可以看作是QA的问题,而QA的问题,就可以用Seq2Seq model来解
Seq2Seq model只要是输入一段文字,输出一段文字,只要是输入一个Sequence,输出一个Sequence就可以解,所以你可以把QA的问题,硬是用Seq2Seq model解,叫它读一篇文章读一个问题,然后就直接输出答案,所以各式各样NLP的任务,其实都有机会使用Seq2Seq model

必须要强调一下,对多数NLP的任务,或对多数的语音相关的任务而言,往往為这些任务客製化模型,你会得到更好的结果
Seq2seq for Syntactic Parsing :文法剖析
在语音还有自然语言处理上的应用,其实有很多应用,你不觉得他是一个Seq2Seq model的问题,但你都可以硬用Seq2Seq model的问题硬解他

机器要做的事情是產生,一个文法的剖析树 告诉我们,deep加learning合起来,是一个名词片语,very加powerful合起来,是一个形容词片语,形容词片语加is以后会变成,一个动词片语,动词片语加名词片语合起来,是一个句子
那今天文法剖析要做的事情,就是產生这样子的一个Syntactic tree,所以在文法剖析的任务裡面,假设你想要deep learning解的话,输入是一段文字,他是一个Sequence,但输出看起来不像是一个Sequence,输出是一个树状的结构,但事实上一个树状的结构,可以硬是把他看作是一个Sequence
这个树状结构可以对应到一个,这样子的Sequence,从这个Sequence裡面,你也可以看出
- 这个树状的结构有一个S,有一个左括号,有一个右括号
- S裡面有一个noun phrase,有一个左括号跟右括号
- NP裡面有一个左括号跟右括号,NP裡面有is
- 然后有这个形容词片语,他有一个左括号右括号

multi-label classification :
还有一些任务可以用seq2seq’s model,举例来说 multi-label的classification
multi-class的classification,跟multi-label的classification,听起来名字很像,但他们其实是不一样的事情,multi-class的classification意思是说,我们有不只一个class机器要做的事情,是从数个class裡面,选择某一个class出来
但是multi-label的classification,意思是说同一个东西,它可以属於多个class,举例来说 你在做文章分类的时候

可能这篇文章 属於class 1跟3,这篇文章属於class 3 9 17等等,你可能会说,这种multi-label classification的问题,能不能直接把它当作一个multi-class classification的问题来解
举例来说,我把这些文章丢到一个classifier裡面
本来classifier只会输出一个答案,输出分数最高的那个答案
我现在就输出分数最高的前三名,看看能不能解,multi-label的classification的问题
但这种方法可能是行不通的,因為每一篇文章对应的class的数目,根本不一样 有些东西 有些文章,对应的class的数目,是两个 有的是一个 有的是三个
所以 如果你说 我直接取一个threshold,我直接取分数最高的前三名,class file output分数最高的前三名,来当作我的输出 显然,不一定能够得到好的结果 那怎麼办呢
这边可以用seq2seq硬做,输入一篇文章 输出就是class 就结束了,机器自己决定 它要输出几个class
我们说seq2seq model,就是由机器自己决定输出几个东西,输出的output sequence的长度是多少,既然 你没有办法决定class的数目,那就让机器帮你决定,每篇文章 要属於多少个class
Encoder-Decoder
我们现在就是要来学,怎麼做seq2seq这件事,一般的seq2seq’s model,它裡面会分成两块 一块是Encoder,另外一块是Decoder

你input一个sequence有Encoder,负责处理这个sequence,再把处理好的结果丢给Decoder,由Decoder决定,它要输出什麼样的sequence,等一下 我们都还会再细讲,Encoder跟 Decoder内部的架构

Encoder
seq2seq model Encoder要做的事情,就是给一排向量,输出另外一排向量

现在的Encoder裡面,会分成很多很多的block
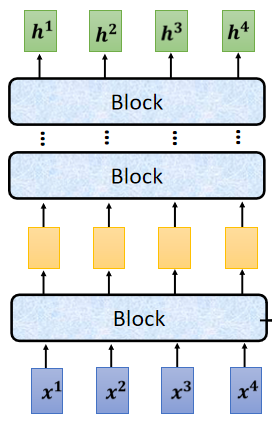
每一个block都是输入一排向量,输出一排向量,你输入一排向量 第一个block,第一个block输出另外一排向量,再输给另外一个block,到最后一个block,会输出最终的vector sequence,每一个block 其实,并不是neural network的一层
每一个block裡面做的事情,是好几个layer在做的事情,在transformer的Encoder裡面,每一个block做的事情,大概是这样子的

- 先做一个self-attention,input一排vector以后,做self-attention,考虑整个sequence的资讯,Output另外一排vector.
- 接下来这一排vector,会再丢到fully connected的feed forward network裡面,再output另外一排vector,这一排vector就是block的输出
事实上在原来的transformer裡面,它做的事情是更复杂的
在之前self-attention的时候,我们说 输入一排vector,就输出一排vector,这边的每一个vector,它是考虑了 所有的input以后,所得到的结果

在transformer裡面,它加入了一个设计,我们不只是输出这个vector,我们还要把这个vector加上它的input,它要把input拉过来 直接加给输出,得到新的output
也就是说,这边假设这个vector叫做a,这个vector叫做b 你要把a+b当作是新的输出
这样子的network架构,叫做residual connection,那其实这种residual connection,在deep learning的领域用的是非常的广泛,之后如果我们有时间的话,再来详细介绍,為什麼要用residual connection
那你现在就先知道说,有一种network设计的架构,叫做residual connection,它会把input直接跟output加起来,得到新的vector
得到residual的结果以后,再把它做一件事情叫做normalization,这边用的不是batch normalization,这边用的叫做layer normalization

layer normalization做的事情,比bacth normalization更简单一点
输入一个向量 输出另外一个向量,不需要考虑batch,它会把输入的这个向量,计算它的mean跟standard deviation
但是要注意一下,batch normalization是对不同example,不同feature的同一个dimension,去计算mean跟standard deviation
但layer normalization,它是对同一个feature,同一个example裡面,不同的dimension,去计算mean跟standard deviation
计算出mean,跟standard deviation以后,就可以做一个normalize,我们把input 这个vector裡面每一个,dimension减掉mean,再除以standard deviation以后得到x’,就是layer normalization的输出
x i ’ = x i − m σ x_i^’ = \frac{ { {x_i} - m}}{\sigma } xi’=σxi−m
得到layer normalization的输出以后,它的这个输出 才是FC network的输入

而FC network这边,也有residual的架构,所以 我们会把FC network的input,跟它的output加起来 做一下residual,得到新的输出
这个FC network做完residual以后,还不是结束 你要把residual的结果**,再做一次layer normalization**,得到的输出,才是residual network裡面,一个block的输出,所以这个是挺复杂的
所以我们这边讲的 这一个图,其实就是我们刚才讲的那件事情

- 首先 你有self-attention,其实在input的地方,还有加上positional encoding,我们之前已经有讲过,如果你只光用self-attention,你没有位置的资讯,所以你需要加上positional的information,然后在这个图上,有特别画出positional的information
- Multi-Head Attention,这个就是self-attention的block,这边有特别强调说,它是Multi-Head的self-attention
- Add&norm,就是residual加layer normalization,我们刚才有说self-attention,有加上residual的connection,加下来还要过layer normalization,这边这个图上的Add&norm,就是residual加layer norm的意思
- 接下来,要过feed forward network
fc的feed forward network以后再做一次Add&norm,再做一次residual加layer norm,才是一个block的输出, - 然后这个block会重复n次,这个复杂的block,其实在之后会讲到的,一个非常重要的模型BERT裡面,会再用到 BERT,它其实就是transformer的encoder
To Learn more
讲到这边 你心裡一定充满了问号,就是為什麼 transformer的encoder,要这样设计 不这样设计行不行?
行 不一定要这样设计,这个encoder的network架构,现在设计的方式,本文是按照原始的论文讲给你听的,但原始论文的设计 不代表它是最好的,最optimal的设计

- 有一篇文章叫,on layer normalization in the transformer architecture,它问的问题就是 為什麼,layer normalization是放在那个地方呢,為什麼我们是先做,residual再做layer normalization,能不能够把layer normalization,放到每一个block的input,也就是说 你做residual以后,再做layer normalization,再加进去 你可以看到说左边这个图,是原始的transformer,右边这个图是稍微把block,更换一下顺序以后的transformer,更换一下顺序以后 结果是会比较好的,这就代表说,原始的transformer 的架构,并不是一个最optimal的设计,你永远可以思考看看,有没有更好的设计方式
- 再来还有一个问题就是,為什麼是layer norm 為什麼是别的,不是别的,為什麼不做batch normalization,也许这篇paper可以回答你的问题,这篇paper是Power Norm:,Rethinking Batch Normalization In Transformers,它首先告诉你说 為什麼,batch normalization不如,layer normalization,在Transformers裡面為什麼,batch normalization不如,layer normalization,接下来在说,它提出来一个power normalization,一听就是很power的意思,都可以比layer normalization,还要performance差不多或甚至好一点