目录
问题1、某人在以太坊发布一个交易,有人收到这个交易,转账交易A->B,有没有可能这个收款人的地址从来没听说过?
问题2、状态树和交易树、收据树的区别是,状态树要包含系统中所有账户的状态(无论这些账户是否参与了当前区块的交易),那能否将状态树的设计修改成每个区块的状态树也只包含这个区块中的交易相关的那些账户的状态,与交易树和收据树一致,而且可以大幅度削减每个区块所对应的状态树的大小(因为大部分的账户状态是不会变的)?
五、思考
问题1、某人在以太坊发布一个交易,有人收到这个交易,转账交易A->B,有没有可能这个收款人的地址从来没听说过?
以太坊系统和比特币系统类似,创建账户时不需要通知其他人的,只有这个账户第一次收到钱的时候,其他的节点才会知道这个账户的存在,这个时候因为新插入了一个账户,所以要在状态树中新插入的一个节点。
问题2、状态树和交易树、收据树的区别是,状态树要包含系统中所有账户的状态(无论这些账户是否参与了当前区块的交易),那能否将状态树的设计修改成每个区块的状态树也只包含这个区块中的交易相关的那些账户的状态,与交易树和收据树一致,而且可以大幅度削减每个区块所对应的状态树的大小(因为大部分的账户状态是不会变的)?
如果这样设计,每个区块没有一颗完整的状态树(只有当前区块中包含的交易涉及到的账户的状态),这么设计会使,如果要想查找某个账户的状态就会变得不方便。假设存在一个转账交易A→B(10ETH),要检查A账户里是不是真的有10ETH,但是当前区块和最近一个区块对应的那个状态树可能没有这个账户,那么需要往前一直找,直到找到最近的一个包含A账户的区块,才能知道A的账户余额是多少。如果A有较长的一段时间没有发生交易,可能要从后往前,扫描很多个区块,才能找到最近一次的账户状态。还有一个更大的问题,A给B转账,要知道A账户的状态,才能知道A是不是有足够的钱转给B,也要知道B账户的状态,余额是多少(因为要往B账户余额里加10ETH),但B账户有可能是个新建的账户,这时候需要从当前区块一直扫描到创世纪块,发现这个账户没有,才知道原来是个新建的账户。
六、代码中的具体体现
1.交易树和收据树的创建过程
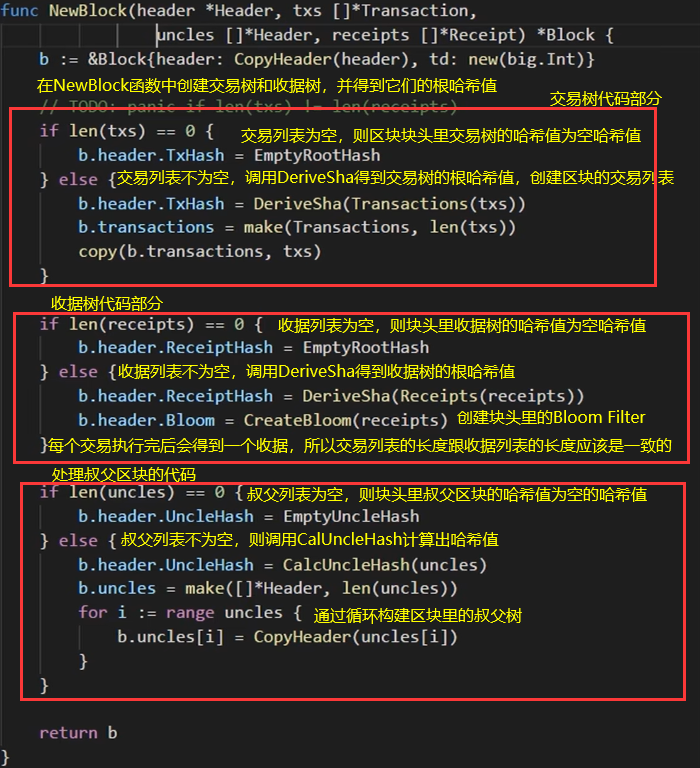
func NewBlock(header *Header,txs []*Transaction,
uncles []*Header,receipts []*Receipt)*Block {
b := &Block{header: CopyHeader(header),td: new(big.Int)}
//TODO: panic if len(txs)!= len(receipts)
if len(txs)==0 {
b.header.TxHash = EmptyRootHash
} else {
b.header.TxHash = DeriveSha(Transactions(txs))
b.transactions = make(Transactions,len(txs))
copy(b.transactions,txs)
}
if len(receipts) ==0 {
b.header.ReceiptHash = EmptyRootHash
} else {
b.header.ReceiptHash = DeriveSha(Receipts(receipts))
b.header.Bloom = CreateBloom(receipts)
}
if len(uncles) ==0 {
b.header.UncleHash = EmptyUncleHash
} else {
b.header.UncleHash = CalcUncleHash(uncles)
b.uncles = make([]*Header,len(uncles))
for i := range uncles {
b.uncles[i]= CopyHeader(uncles[i])
}
}
return b
}2.DeriveSha函数
NewBlock函数创建交易树和收据树的时候用到的都是这个函数,这里创建的数据结构是一棵Trie,而Trie的数据结构是MPT。
func DeriveSha(list DerivableList) common.Hash {
keybuf := new(bytes.Buffer)
trie := new(trie.Trie)//创建的数据结构是一个Trie
for i := 0; i < list.Len(); i++ {
keybuf.Reset()
rlp.Encode(keybuf, uint(i))
trie.Update(keybuf.Bytes(),list.GetRlp(i))
}
return trie.Hash()
}
//Trie is a Merkle Patricia Trie.Trie是一棵MPT
// The zero value is an empty trie with no database.
// Use New to create a trie that sits on top of a database.l /
// Trie is not safe for concurrent use.
type Trie struct {
db *Database
root node
originalRoot common. Hash
// Cache generation values.
// cachegen increases by one with each commit operation.
// new nodes are tagged with the current generation and unloaded
// when their generation is older than than cachegen-cachelimit.
cachegen,cachelimit uint16
}
3.Receipt的数据结构

// Receipt represents the results of a transaction.
type Receipt struct {
// Consensus fields
PostState []byte `json:"root"`
Status uint64 `json:"status"
CumulativeGasUsed uint64 `json:"cumulativeGasUsed" gencodec:"required"`
Bloom Bloom `json:"logsBloom" gencodec:"required"`
Logs []*Log `json:"logs" gencodec:"required"`
//Implementation fields (don 't reorder !)
TxHash common.Hash `json:"transactionHash" gencodec: "required"
ContractAddress common.Address `json:"contractAddress"
GasUsed uint64 `json: "gasUsed" gencodec : "required"
}
4.Bloom Filter
如图6-3所示是之前学习过的区块块头的数据结构,里面的Bloom域就是整个区块的bloom filter,这个是由刚才看到的每个收据的Bloom Filter合在一起得到的。

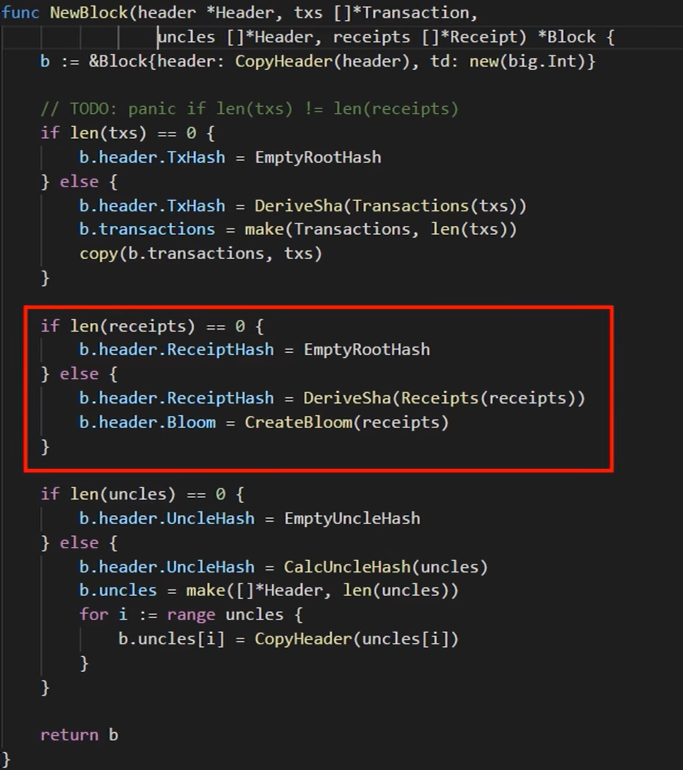
下图6-4所示,NewBlock函数中的红框里的代码就是创建块头里的bloom filter,通过调用CreateBloom这个函数。
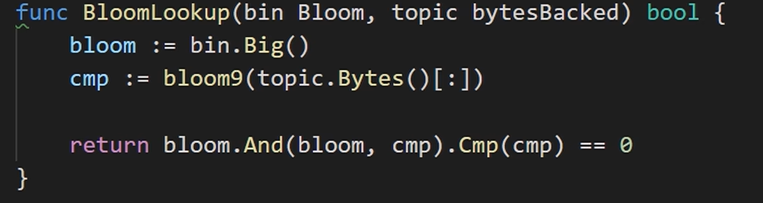
CreateBloom、LogsBloom、bloom哈希函数的代码实现如下图6-5所示。

查询某个Bloom Filter里面是否包含了某感兴趣的topic就用到图6-6所示的BloomLookup函数。查一下bin的bloom filter里有没有包含要找的第二个参数topic,首先用刚才讲的bloom9函数把topic转化成一个bytesBacked,然后把他跟Bloom Filter取and操作,看看得到的结果是不是和bytesBacked相等。注意,Bloom Filter里面可能包含除了我们要查找的topic之外其他的topic,所以要做一个and,然后再跟他自身比较,相当于判断一下我们要查找的这个topic在Bloom Filter中对应的位置是不是都是1。