《区块链技术与应用》北大肖臻老师——课程笔记【13-18】
提示:以下内容只是个人在学习过程中记录的笔记,图片均是肖老师课程的截图,可供参考。如有错误或不足之处,请大家指正。
一、BTC-思考
1、哈希指针
指针保存的本地内存的地址,只是在本地计算机才有意义,发送到其他的计算机上没有意义,在发布区块时,哈希指针是如何通过网络进行传输?
哈希指针只是一种形象的说法,实际应用中只有哈希,没有指针。在块头的数据结构中,hashPrevBlock就是指向前一个区块的哈希,没有指针,块头里只有哈希值,没有指针。全节点一般把这些区块存储在(key, value )数据库中,key就是区块哈希,value就是区块内容。
一个常用的(key, value )数据库是levelDB,所谓的区块链链表结构,实际上是在levelDB里,用哈希值串起来,只要掌握了最后一个哈希值,根据key就可以把最后一个区块的内容找出来,区块块头又有指向前一个区块的哈希,再根据key又可以找到前一个区块的内容,以此类推,最终能把整个区块链找出来。在实际系统中,所谓的哈希指针是只有哈希,没有指针,或者可以认为哈希值本身就是指针。
有些节点没有完整保存区块链信息,只保存了最近的几千个区块,如果需要用到其他节点信息,可以问其他全节点要。
哈希指针的性质保证了整个区块链的内容是不可篡改的。

2、区块恋
之前七夕有情侣两个人合伙买比特币,把私钥分为两部分,各自保存一部分,将来如果两人继续发展,那么两个人私钥合在一起可以把钱取出来,将来如果分手了,那么两个人的币就会永久的锁在区块链里,谁也取不出来了。区块恋用区块链的不可篡改性作为两个人爱情的见证。
存在的问题:
问题一:如果要推广,N个人的账户要把私钥分成N份,要用的时候再拼在一起。如果其中有任何一个的的私钥部分丢失了,这个钱将无法取出来。
这种截断私钥的做法还会降低账户的安全性。比特币账户的安全性和私钥的长度相关,256位的私钥用暴力破解的方法不可行,但是如果从中截断,假设有上面例子的情侣中有一个人想私自把钱取出来,他已经知道一部分私钥,把另一部分私钥猜出来就可以取出来了。
把私钥截取一半,不等同于破解的难度也会降低一半。256位的私钥有2的256次方可能性,截取一半有2的128次方可能性,难度差距很大,说明对于多个人的共享账户,不要用截断私钥的方法,可以用多重签名的方法。
多重签名中用到的每一个私钥都是独立产生的,还提供其他灵活性,如N个人中任意给出M个人的签名即可。
问题二:如果上面例子情侣两个人分手了,他们的币就会永久的保存在UTXO里,这样对矿工不友好。早期很多人图新鲜挖矿,保存在硬盘里,丢失了私钥,这些丢失私钥的输出被永久的保存在UTXO中,造成集合的膨胀。
3、分布式共识
学术界有很多分布式共识的不可能结论,从理论上证明分布式系统中共识是不可能的,那么实际中是如何变得可能?(比特币如何取得共识?/为什么比特币系统能绕过分布式共识中那些不可能结论?)
严格的说,比特币并没有取得真正意义上的共识,因为取得的共识随时都有可能被推翻,如分叉攻击,本来以为已经达成了某一个共识,出现了分叉攻击后,系统会回滚到到前一个状态,从理论上说,甚至可能一直回滚到创世纪块。
按照分布式系统理论的要求,共识一旦达成后,就不应该再修改,所以从这个意义上说,比特币并没有绕过分布式共识中那些不可能结论,因为比特币并没有达到真正意义上的共识。
理论和实际往往是有距离的,很多理论上的不可能结论,对于实际当中是不适用的,因为这个不可能结论对某种特定的模型下是不可能的,实际中把模型稍微修改,这个不可能结论就不成立了。
例:
在异步的环境中,不可能区分某台远程的服务器是垮掉了还是运行缓慢,分布式系统的理论体系中有这个不可能结论。
这个不可能结论是很显然的,所谓的异步环境,是说通讯传输的延迟是没有上限的,如果远程服务器连不上,有可能是服务器本身死掉了,也有可能是通讯延迟太长,也许下一秒就能连上,这就是为什么说这两种情况无法区分开。
做法:手动重启或用远程控制卡,或是给远程服务器加一根电话线,用于拨号上网(大概十几年前的做法)。所以理论上的不可能又变成了实际中的可能。
启示:知识改变命运,但是对知识的一知半解,有可能会使命运变得更差。不要被学术界的思维限制了头脑,不要被程序员的思维限制了想象力。
4、比特币的稀缺性
任何一个新发行的加密货币,都有一个能启动的问题,早期不是很流行,给早期矿工更多的收益,就能吸引更多人。这个是合理的,因为早期的矿工承担的风险更大。
比特币做到这一点的方面:一是早期的挖矿难度低,很容易挖到,二是早期的出块奖励高,每个区块50个奖励,现在降低了,越往后越少。
比特币这样的设计很巧妙,相对于比特币的数量是恒定的,越到后面越难挖,越来越多的人抢着挖。但其实这种总量固定的是不适合用来作为货币的,以太坊就没有出块奖励和固定的做法,有些加密货币自带通胀,每年会把货币发行量提高一定比例。
设计原因:稀缺的东西不适合用来做货币,平时大家认为通货膨胀是件坏事,但是一个好的货币,其实要有通货膨胀的功能,如果货币总量固定不适合用来做货币,如黄金,每年黄金产量增加的速度远远赶不上社会新创造财富的速度,所以假设用黄金作为货币,黄金会越来越值钱。
5、量子计算
有人产生了一种担心,像比特币这种加密货币是建立在密码学基础上,将来量子计算发展起来后,这些加密货币会不会变得不安全。这个担心是不必要的,首先量子计算技术离实用还有很长一段距离,在比特币的有生之年,不一定能产生实质性的威胁。如果将来有一天量子计算可以强大到破坏现有的加密体系,那么首先冲击的是传统金融业,如网上银行转账等,都会变得不安全,与其担心量子计算对比特币的冲击,不如担心对传统金融业的冲击,因为大多数的钱还是放在传统金融业中,加密货币的总市值只占了现代金融体系的很小一部分,而且将来还会有量子加密算法。
比特币中并没有把账户的公钥直接暴露出来,而是用公钥取哈希之后得到一个地址,比特币中用的非对称加密体系,可以用私钥推导出公钥,公钥不能推导出私钥。比特币在设计时用加了一层保护,没有用公钥本身,是用公钥哈希,如果有人想偷账户上的钱,要用这个公钥哈希地址推导出公钥,而这样即使是用量子计算也是无法做到的。
加密和取哈希是两个不同性质的操作,加密的目的是为了将来能解密,加密算法要保证信息的完整性,加密过程不能丢失信息;取哈希的过程会造成信息丢失,哈希函数是不可逆的,不能用哈希值逆推导出原来的内容。
从安全性角度看,比特币一个地址一旦用过后,就不要再用了,可以增加安全性和隐私保护。
二、ETH-以太坊概述
1、以太坊
比特币和以太坊是两种最主要的加密货币,比特币被成为区块链1.0,以太坊被称为区块链2.0,以太坊在系统设计上,针对比特币的运行过程中出现的问题进行了改进,如出块时间、mining puzzle。
比特币的mining puzzle是计算密集型,比拼的是计算哈希值的算力,造成挖矿设备的专业化;以太坊的mining puzzle对内存要求很高(memory hard),在一定程度上现在了ASIC芯片的使用,叫做ASIC resistance。以太坊还会用权益证明(POS,类似股份投票决定下一个区块如何产生)来代替工作量证明(POW,挖矿)。
以太坊还增加了对智能合约(smart contract)的支持。
2、智能合约
比特币BTC实现的是去中心化的货币,比特币成功后,很多人思考如果货币可以去中心化,还有什么可以去中心化。以太坊ETH的出现一个特性就是出现了去中心化的合约的支持。以太坊中的币通俗称为以太或以太币(Ether),BTC的计量单位最小是一聪(Satoshi),ETH最小计量单位是Wei。
比特币的出现,把政府发行货币等的职能取代了,通过密码学、共识机制来维护加密货币体系的运行。
去中心化的合约也是类似的,现实社会中合约的有效性也是通过司法手段、政府来维护的,以太坊智能合约的设计目的是用技术手段把政府维护有效性的职能取代了。不是所有的合同内容都可以用编程语言实现,也不是所有的合同条款都可以量化,但是有些比较清晰简单的合同可以写成智能合约的形式。
和法币相比,去中心化货币的好处:
可以用于跨国转账,可以节省时间等。
智能合约这种去中心化的合同的好处:
如果合同签署方来自世界各地,没有一个司法管辖权,如果用司法手段维护合同的有效性很困难,用事先写好的程序代码来保证每个人都只能按规则执行可以解决这个情况。就算合同签署方都在一个地方,有同一个司法管辖权,真正想用司法手段维护合同有效性也是一个费时费力的过程。最好的方法是用技术手段保证合同参与方不可能违约。智能合约的一个好处在于代码一旦发布在区块链上,区块链的不可篡改性保证大家只能按照代码制定的规则执行。
三、ETH-账户
1、ETH账户
比特币中的账户是基于交易的模型,这种模式下显式的记录每个账户上有多少钱,要想知道有多少钱,要根据UTXO集合的信息进行推算。
这种模式的好处:隐私保护比较好,实用上比较便利;和实际日常体验不太一样,在前面交易收到的币将来花要全部花出去,不能只花一部分,不然剩下的就会变成交易费。
以太坊的账户是基于账户的模型,这种模型和日常银行类似,系统中要显式地记录每个账户中有多少个以太币。
以太坊转账检测交易是否合法,前提要确保交易发送方账户上有足够的钱。
以太坊账户模式的好处:对于双花攻击有天然的防范作用(不用查询币的来源)。发布交易时不需要说明余额,账户的余额是全节点维护的状态中保存的(状态树)。
2、Replay attack重放攻击
A发布转账交易(A转给B)到网络上,过段时间这个交易被写入区块链中,A以为交易完成了,B是恶意节点,重新广播一遍这个交易,其他节点以为是一个新的转账交易,就又扣了一遍A的钱。
重放攻击和双花攻击是对称的,双花攻击是指花钱的人不诚实,要把钱再花一遍,重放攻击是收钱的人不诚实,要别人再转一遍钱。
比特币中不可能出现重放攻击。
解决重放攻击的方法:加一个nonce,记录这个账户有史以来发布过多少个交易,转账的时候nonce要成为交易内容的一部分。系统每个节点维护A账户的状态,还要维护账户余额的状态和nonce的值。如果有节点重放,查看nonce的值,如果已经出现了这个nonce值,就不会再执行。
以太坊中有两类账户。一类是外部账户(externally owned account),类似比特币的账户,本地产生公私钥对,也叫做普通账户。外部账户的状态有账户余额和nonce,这个nonce是计数器。
第二类账户是合约账户(smart contract account)。合约账户不是通过公私钥对控制,也有nonce,一个合约可以调用另一个合约账户,但是合约账户不能主动发起一个交易。所有的交易只能由外部账户发起,外部账户发起交易可以调用合约账户,合约账户可以发送一个message调用另一个合约账户。
合约账户除了余额,nonce,还有代码code以及相关的状态storage存储,包括每个变量的取值。
3、问题
合约账户被调用的方法:
创建合约时会返回一个地址,知道合约地址就可以调用合约。调用过程中状态会发生变化,代码不变,存储会变。
为什么要设计以太坊这种新的模型?
以太坊要支持智能合约,要求参与者有比较稳定的身份,考虑了过去已有的模式的利弊得失。
现在有人提出来用智能合约出现一些衍生品,financial derivative,如期权,投资等。如果有需要隐私保护,可以创建多个账户根据情况使用不同账户进行交易。
四、ETH-状态树
状态树要完成从状态地址到账户状态的映射。
以太坊中的状态地址是160bits,也就是20个字节,一般表示40个十六进制的数。
系统中的全节点维护哈希表,来存储账户的状态。
如果用哈希表,如果需要提供Merkel proof,如证明账户余额该怎么证明?
方法一:把哈希表中的元素组成一个Merkel tree,然后计算出一个根哈希值,根哈希值保存在块头中。
但是当新账户创建并发布区块,Merkel tree会发生变化,需要重新构建一个Merkel tree。实际上发生变化的状态只是一小部分,包含的交易关联的账户会发生变化,大多数账户状态不会发生变化,重新构造一个Merkel tree代价很大。
Merkel tree除了可以提供Merkel proof证明账户余额,还可以维护各个全节点之间的一致性。这也是比特币把根哈希写在块头的原因之一。
方法一不可行,代价太大。
方法二:直接用一颗Merkel tree,把所有的账户放进去,要改直接在Merkel tree上改,而且只需要改一小部分。
这个方法的问题在Merkel tree没有提供高效的查找、更新方法,Merkel tree的排序也有问题,证明交易是否存在区块中不排序很难验证,还有问题是叶节点的顺序是乱的,最后构建的Merkel tree是乱的,没有唯一的根哈希。
BTCMerkel tree不排序为什么没有上述问题?
比特币中每个全节点收到的交易顺序不一样,获得记账权的节点决定什么顺序写入区块中,顺序是唯一的。如果以太坊中也这样做需要把账户的状态发布到区块中,发布的是账户的状态,但是重复多次发布账户状态不可行。
排序Merkel tree的问题:新增账户的地址产生的交易地址随机,会随机插入Merkel tree,还需要重新构建Merkel tree,插入代价太大。
以太坊中没有显式的删除账户的操作。
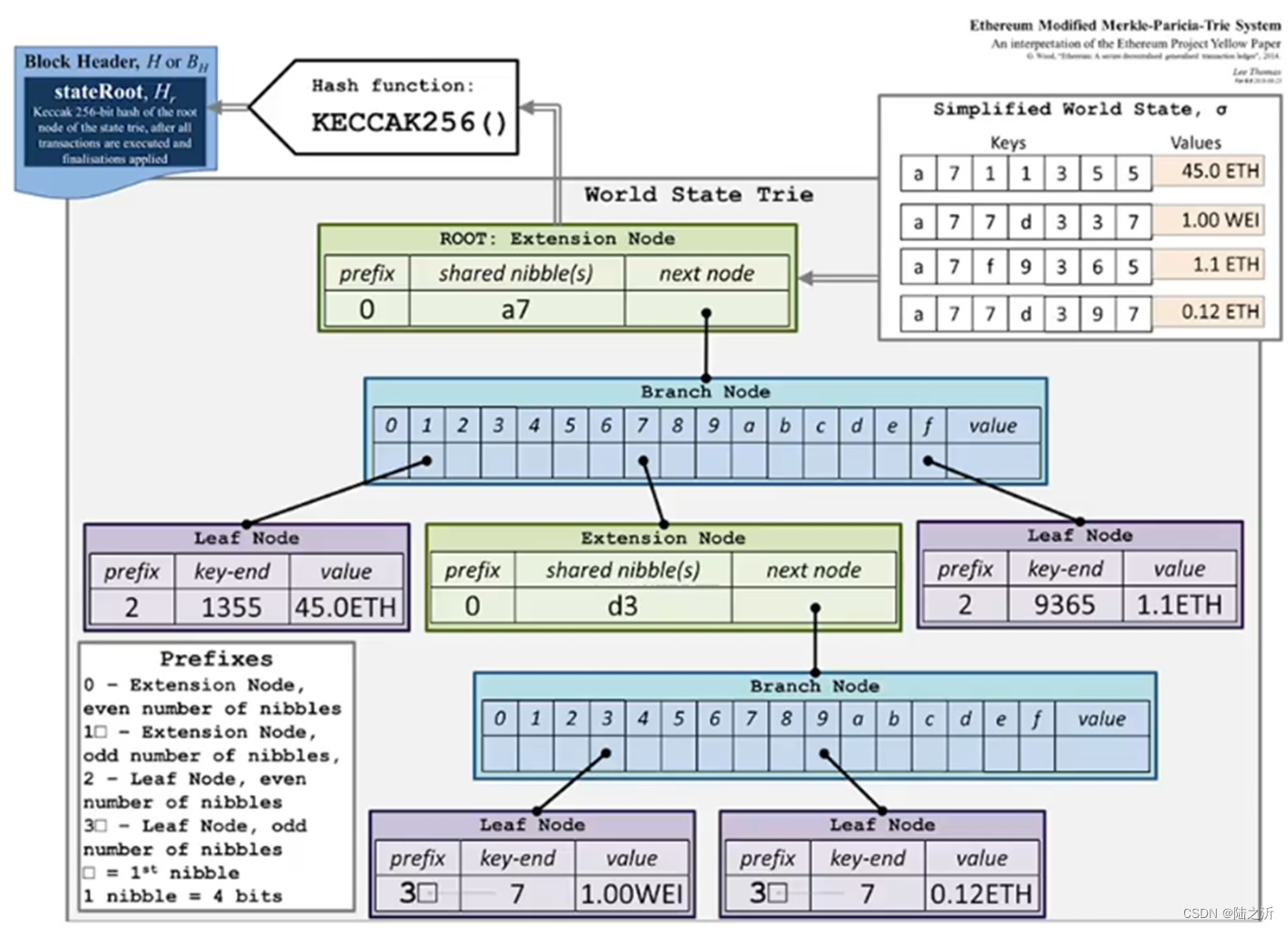
以太坊采用MTP的结构。
Trie数据结构(字典树):一种key value 的store。组织成tried的结构(只给出了key)
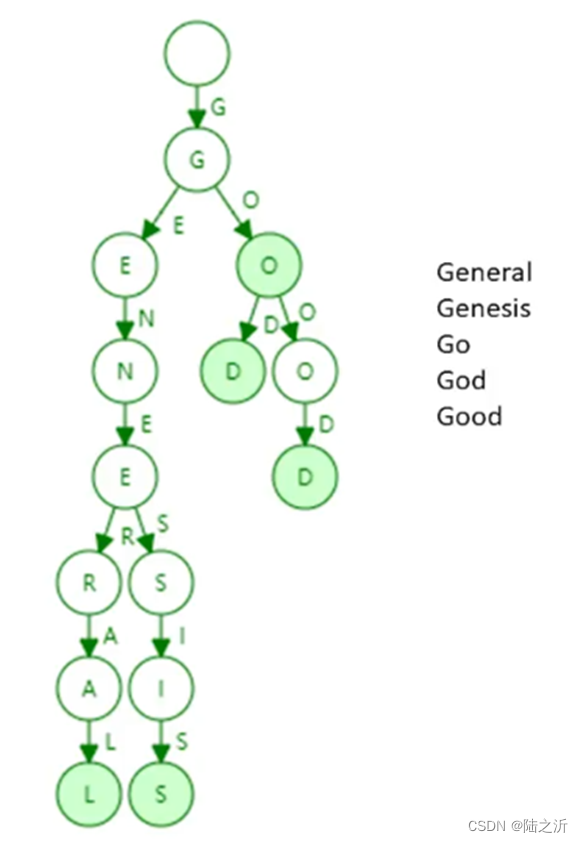
trie结构的特点:
1、每个节点的分支数目取决于key值里每个元素的取值范围。以太坊中分支数目是17.
2、查找效率取决于key的长度,键值越长,查找访问次数越多。比特币和以太坊地址不通用。
3、不会出现碰撞
4、给定一组输入,无论输入怎么打乱插入,构成的trie是同一颗树。
5、更新的局部性很好,只需要更新那个分支,不用更新整棵树
缺点:
存储空间有些浪费。
经过路径压缩的前缀树 Patricia tree/trie:
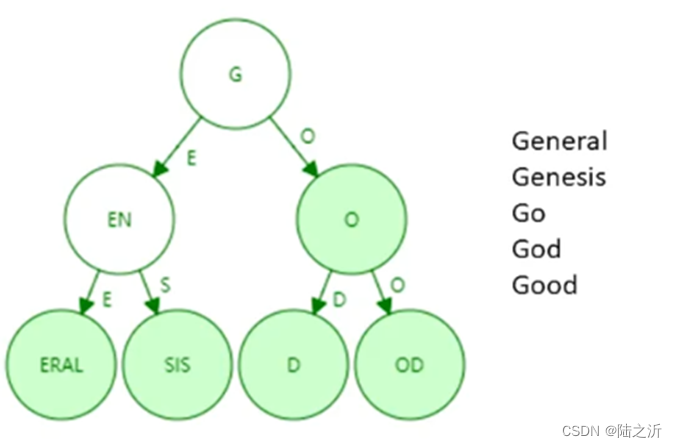
路径压缩的好处:访问内存次数减少,效率提高。
如果新插入一个,原来压缩的路径可能需要扩展开来。
路径压缩在什么情况下效果比较好?
树中插入的键值的分布比较稀疏的情况下,压缩效果较好。
压缩前:
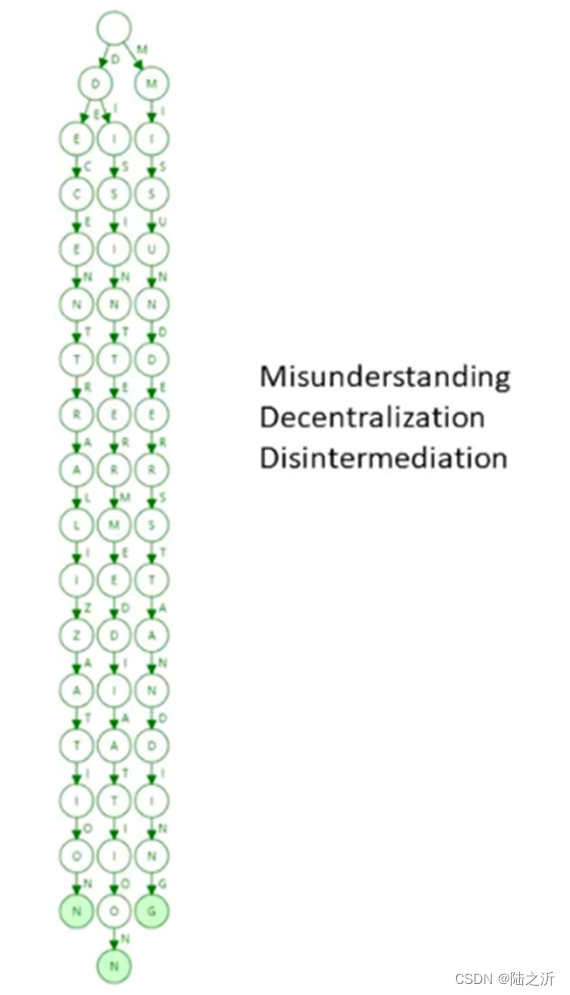
压缩后:
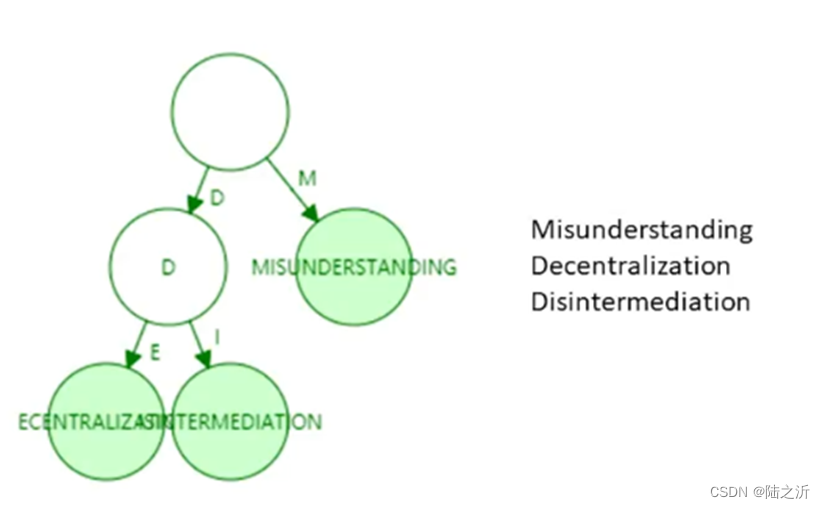
地址键值很稀疏,产生碰撞的可能性很小。
MTP(merkle patricia tree):
MTP和patricia tree的区别:
MTP把普通指针换成了哈希指针
MTP作用:
1、防止篡改
2、证明账户余额
3、证明MTP中某个键值不存在
以太坊运用的是修改的MTP。
以太坊的MTP结构
树中节点分为三种leaf node,extension node ,branch node。
根节点取哈希后哈希值要存在块头里。
发布新区块,这个数有些节点的状态会发生改变,不是在原地改,而是新建一个分支,原来状态被保留下来。
合约账户的存储也是用MTP形式保存下来。以太坊结构是个大的MTP,包含很多小的MTP。
系统中需要维护的不是一个MTP,而是每次发布区块都有新建一个MTP。
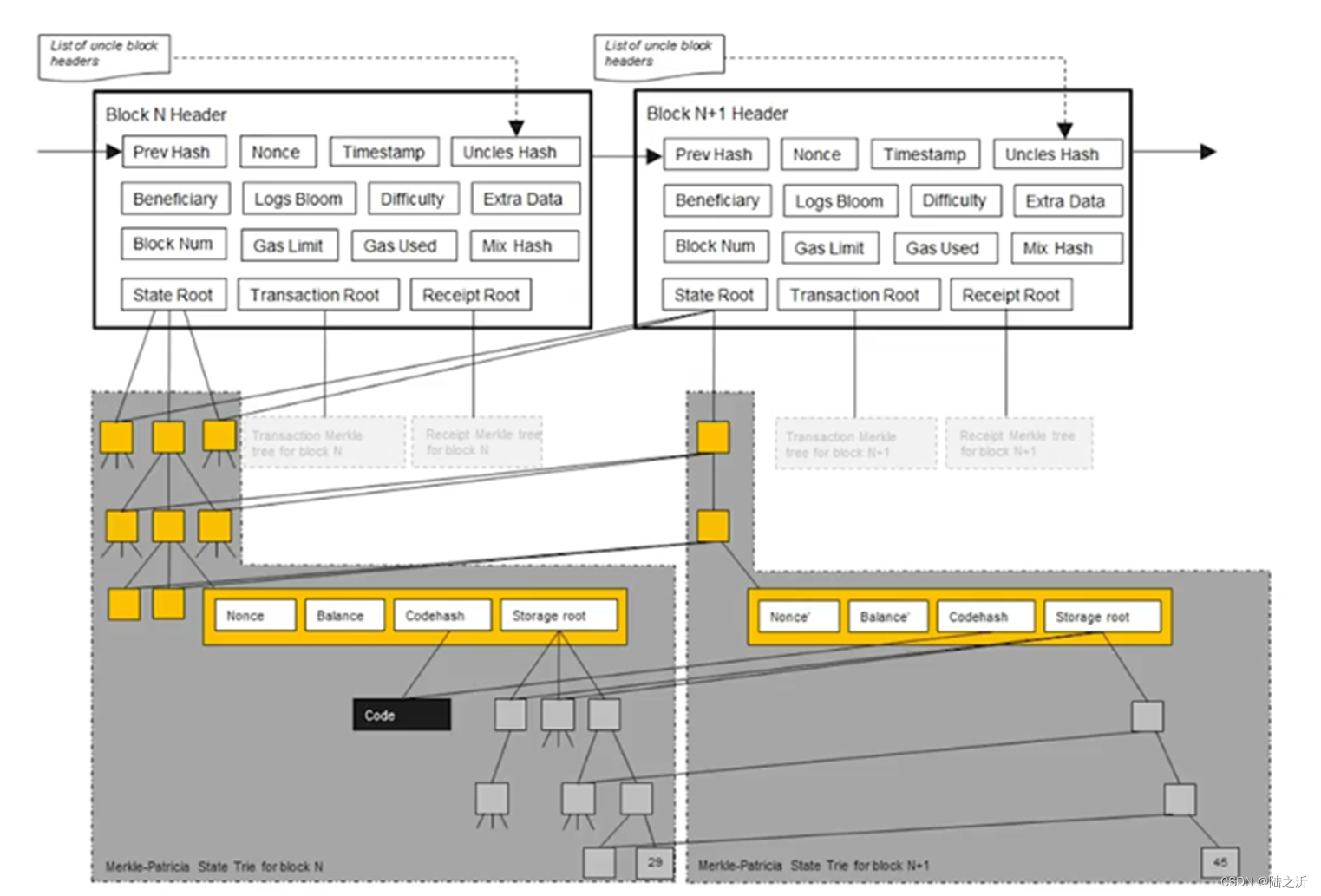
MTP保留原始状态的原因:出现分叉时支持回滚。
以太坊的智能合约是图灵完备的,如果不保存以前的历史状态,智能合约执行完后就无法推出以前的状态。

以太坊代码中的数据结构
以太坊中有三棵树:
1、状态树根哈希:root
2、交易树:TxHash
3、收据树:ReceiptHash
Bloom和收据树相关,提供一种高效的查询的符合某种条件的执行结果。
Nonce挖矿随机数
代码中的区块结构

区块发布的内容

账户状态如何存储在状态树上?
账户状态需要经过一个序列化的过程RLP,用编码做序列化,再存储。
特点是简单,越简单越好。
Protocal buffer做序列化的库
五、ETH-交易树和收据树
每次发布区块时,区块中的交易会组织成一个交易树。
每个交易执行完会形成一个收据,记录交易的相关信息。交易数和收据的节点一一对应。
从数据结构上说,交易数和收据树都是MTP。以太坊中的三棵树都用同样的数据结构,代码统一,方便管理,支持查找操作,对于状态树来说,查找的键值就是账户的地址,对于交易树和收据树来说查找的键值就是发布区块的序号。
状态树、交易树、收据树的重要区别:
交易树和收据树都只把当前发布的区块的交易组织起来,状态树是把系统中所有的状态包含进去。
从数据结构上来说,多个区块的状态树是共享节点的,交易树和收据树是同一个地址,不会共享节点。
交易树和收据树的作用:
1、提供merkel proof,证明交易的执行结果
2、提供过去交易和合约的相关记录、发行新币的时间等复杂操作
以太坊中引入了bloom filter数据结构,支持查找某个元素是不是存在某个比较大的数据结构中。bloom filter给大集合计算出比较紧凑的摘要,一个128位的向量。bloom filter有可能出现碰撞的误报,但不会漏报。
bloom filter删除其中元素的操作:
不支持删除操作,如果要进行删除,要修改成计数器,记住有多少个元素映射过
来,还要考虑计数器会不会溢出。
以太坊中bloom filter的作用:
可以通过bloom filter的结构快速过滤掉无关的区块,更加快速查找信息。
以太坊的运行过程可以看成是一个交易驱动的状态机。状态机的状态就是所有账户的状态。
比特币也可以看做是个状态机,状态是UTXO。
共同的:状态转移都得是确定的。所有的矿工节点都要进行状态转移,所以状态转移要是确定的。
以太坊中,有没有可能节点监听转账交易时,收款人的地址从来没有听过?
有可能,创建账户后,第一次收到钱其他节点才会知道这个账户的存在,这个时候要在状态树中新插入一个节点。
能不能把每个区块的状态树改成只包含和这个区块的交易相关的账户状态?(这样可以和交易树数据树一致,还可以大幅度削减每个区块状态树的大小。)
不可以。每个区块没有一颗完整的状态树,只有所包含交易涉及的状态,如果要想查找某个交易的状态就不方便,如果要查找的账户很长时间没有发生过交易,可能要找到创世纪块才能找到要找的内容。
代码中具体的数据结构:
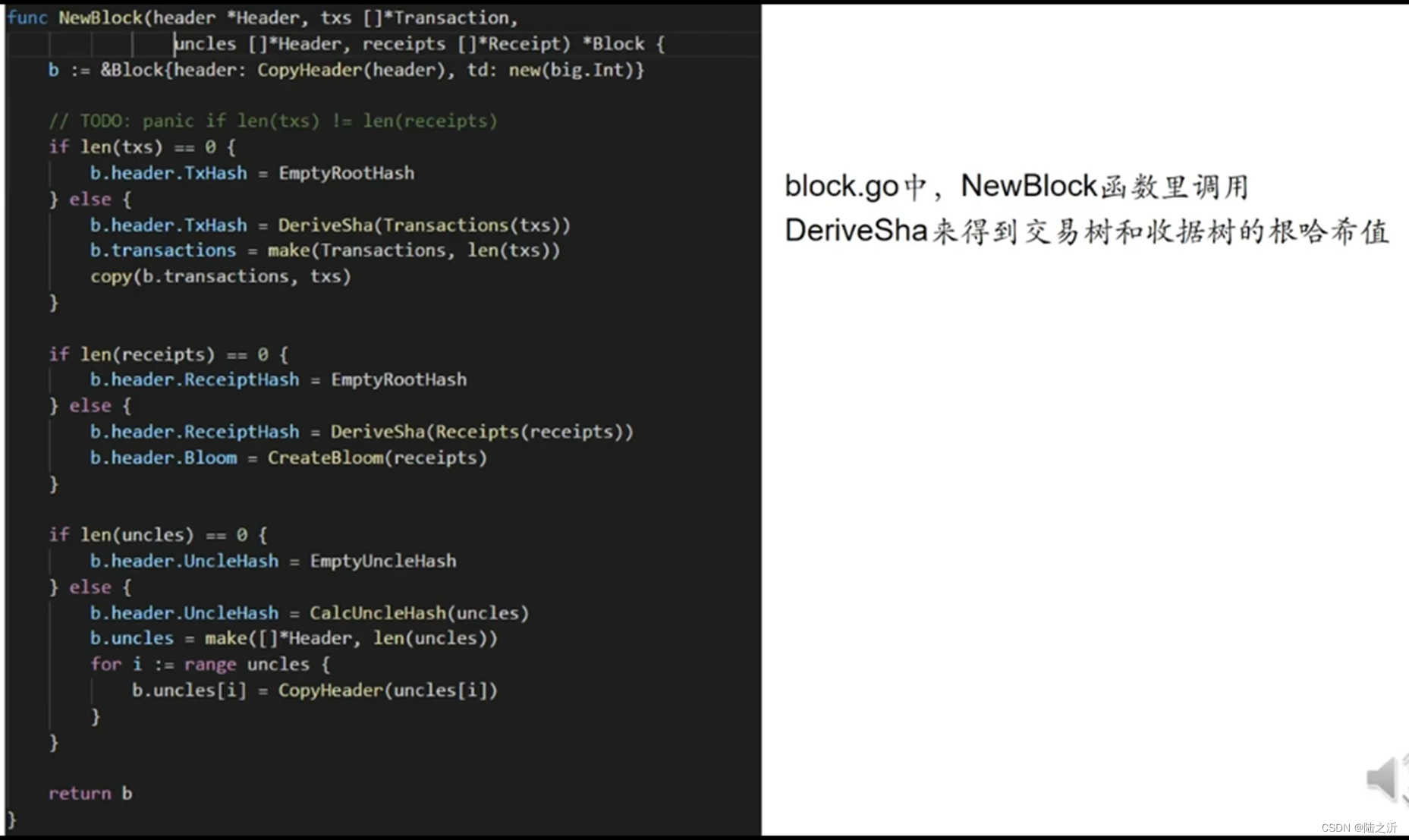
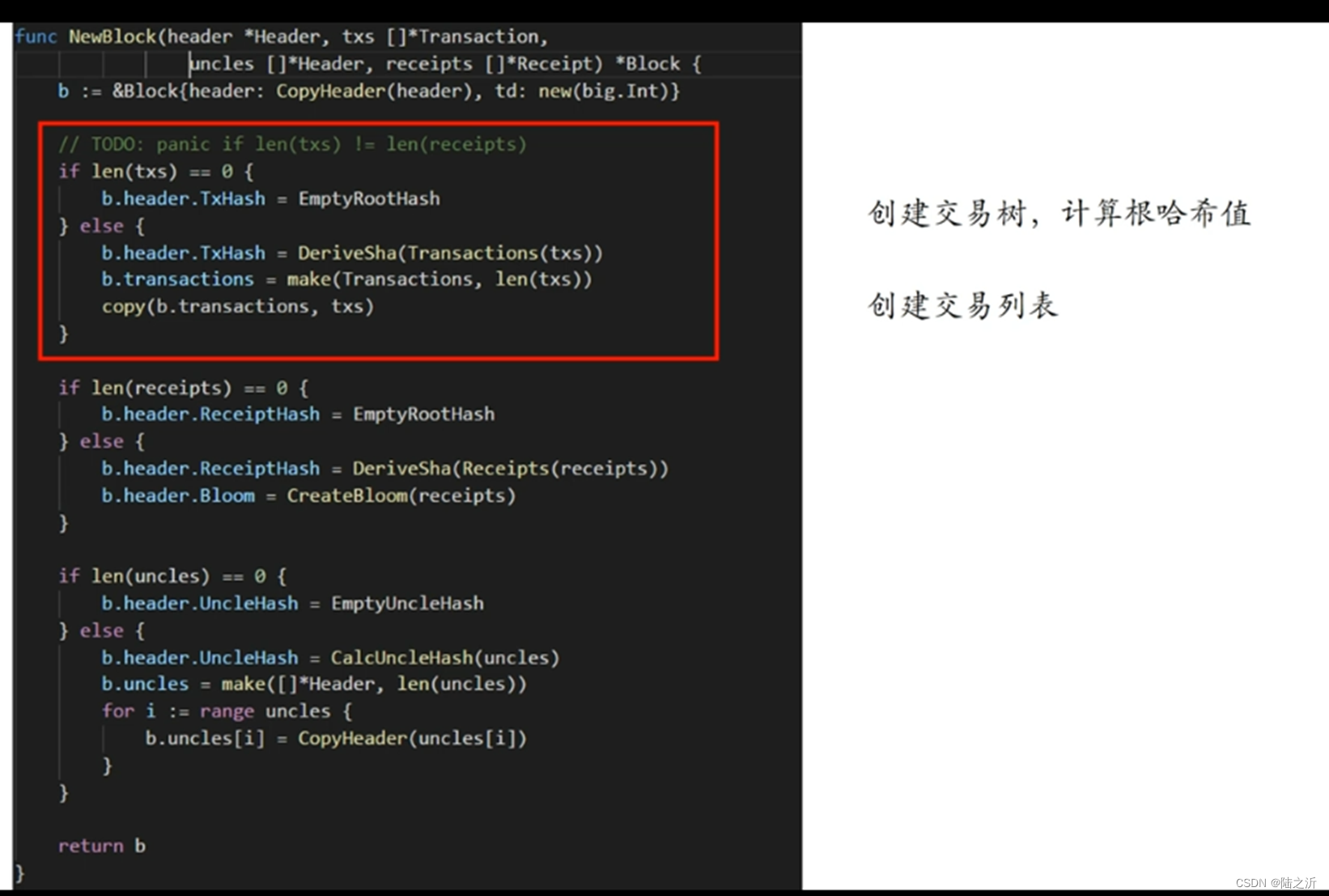
先看交易列表是否为空,不为空则通过调用DeriveSha函数得到交易树的根哈希值,来创建交易列表:
先判断收据列表是否为空,不为空则通过DeriveSha函数获得收据树得到根哈希值来创建:
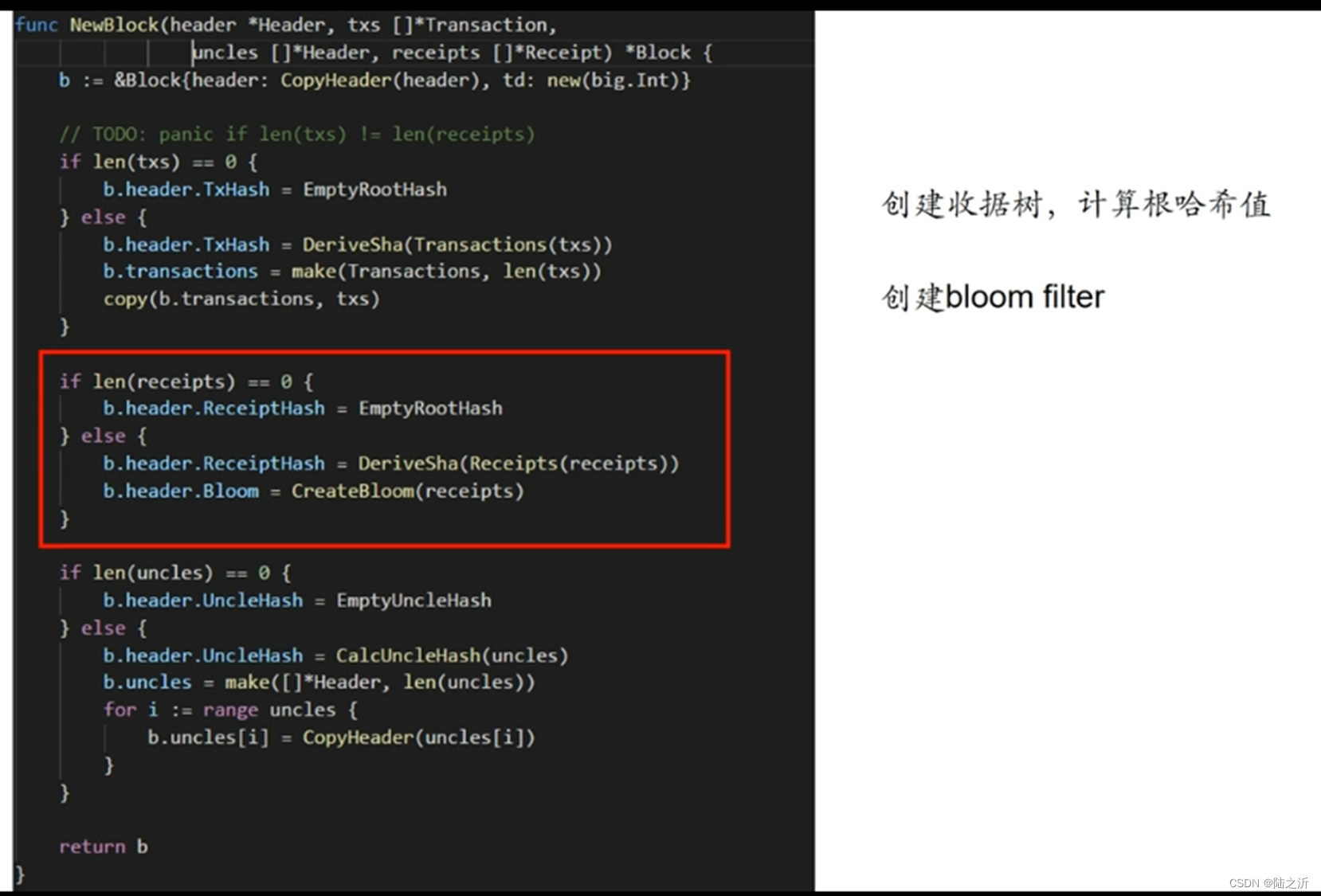
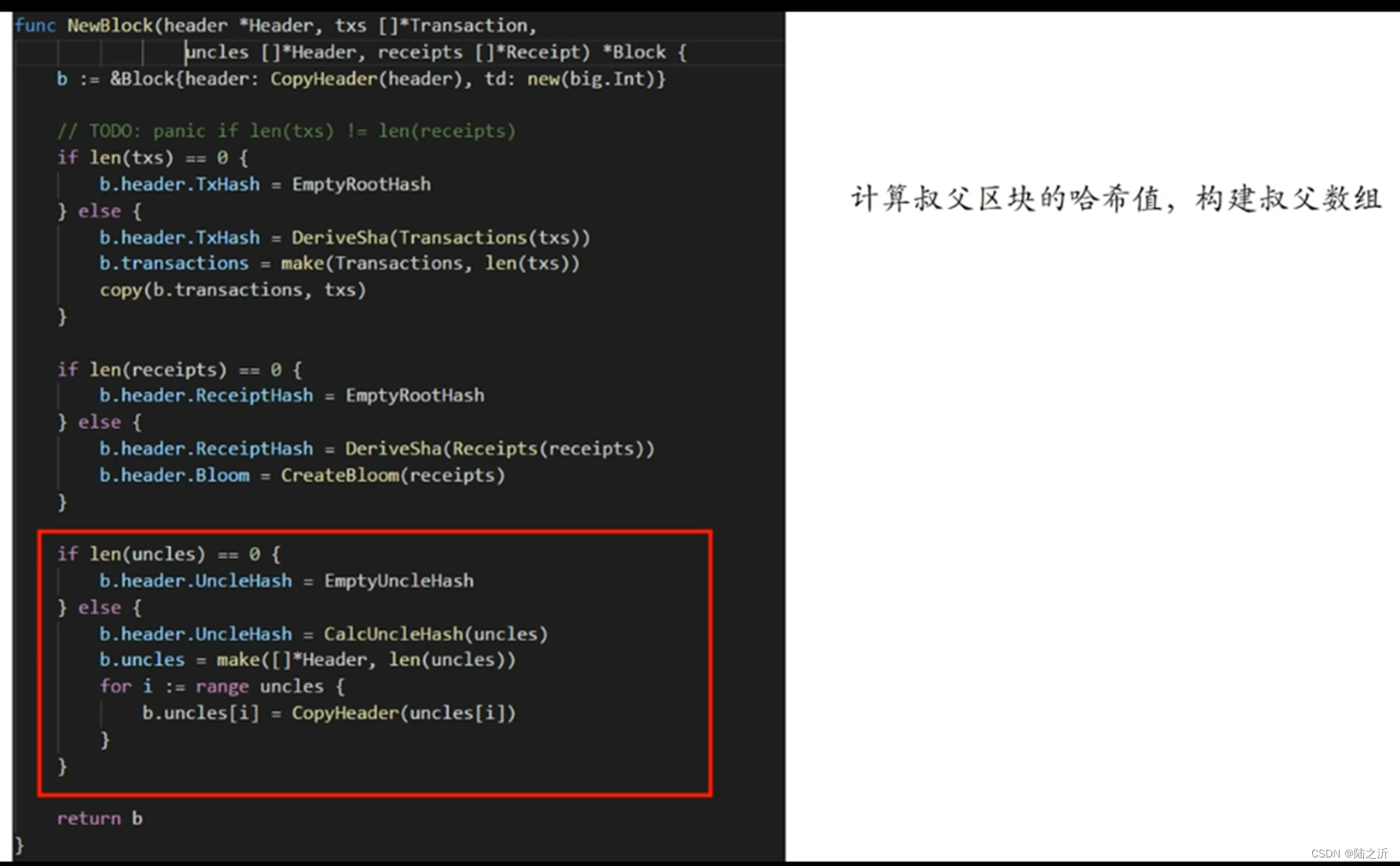
首先判断叔父列表是否为空,不为空则调用CalcUncleHash函数计算出哈希值,然后通过循环构建出叔父数组:

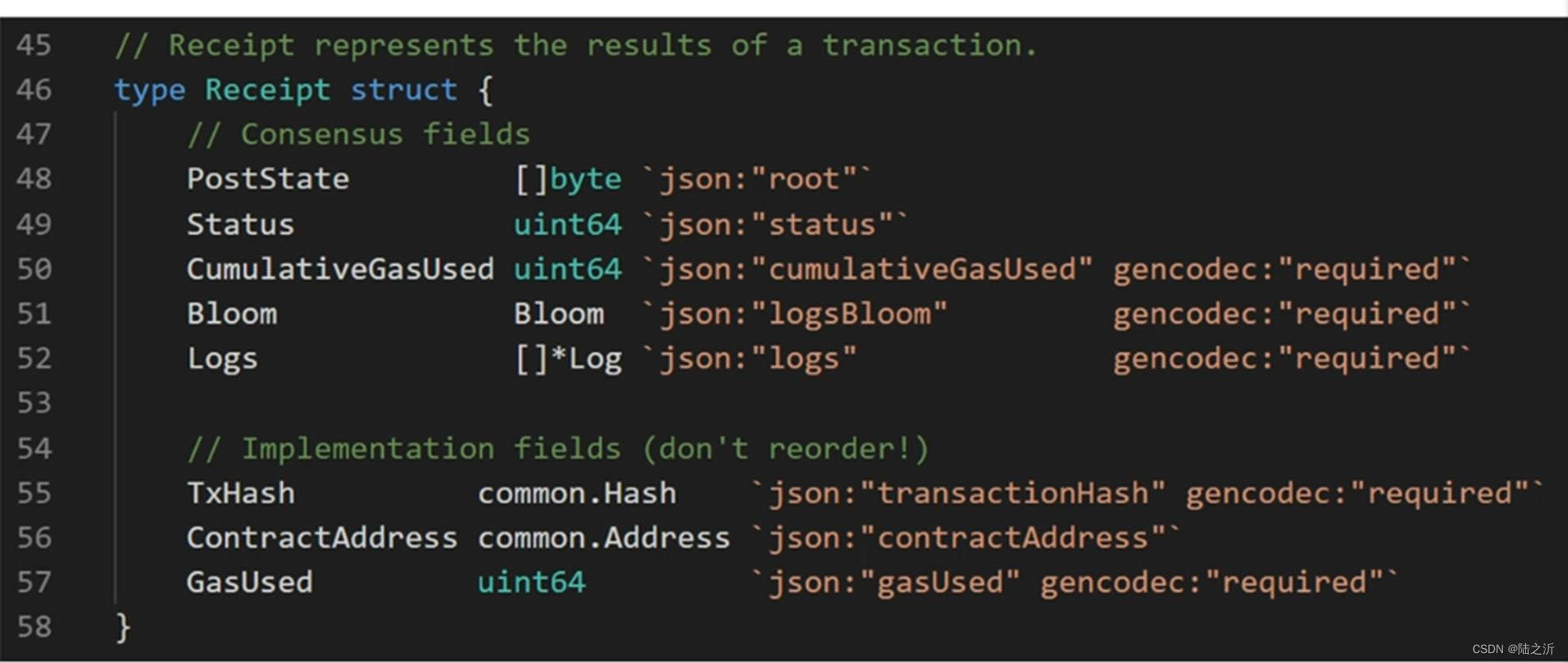
收据树的数据结构,每个交易执行完后形成一个收据,记录了这个交易的执行结果。
Logs是个数组,可以包含多个。
区块块头的数据结构,这里的bloom是由每个收据的bloom合在一起得到的。
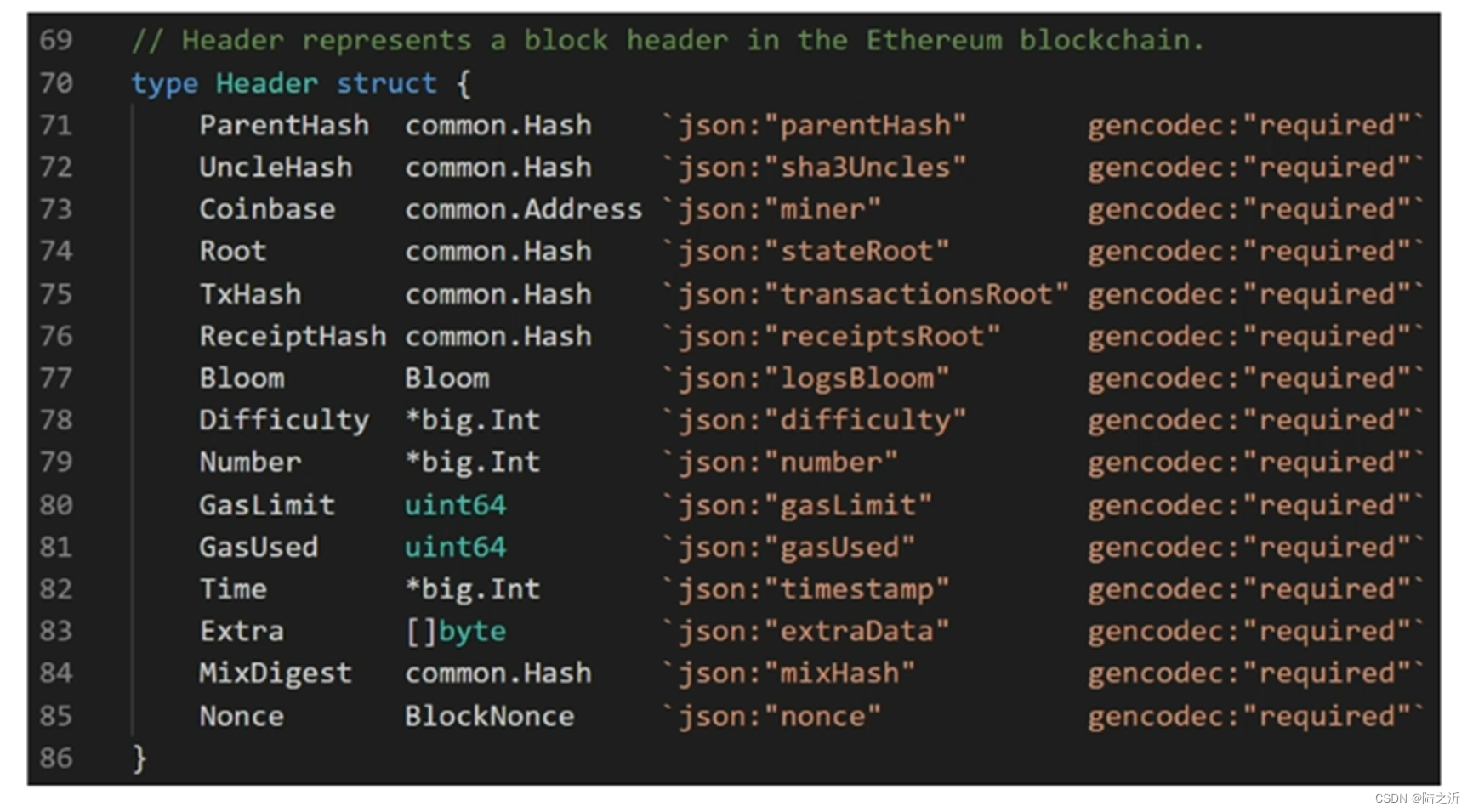
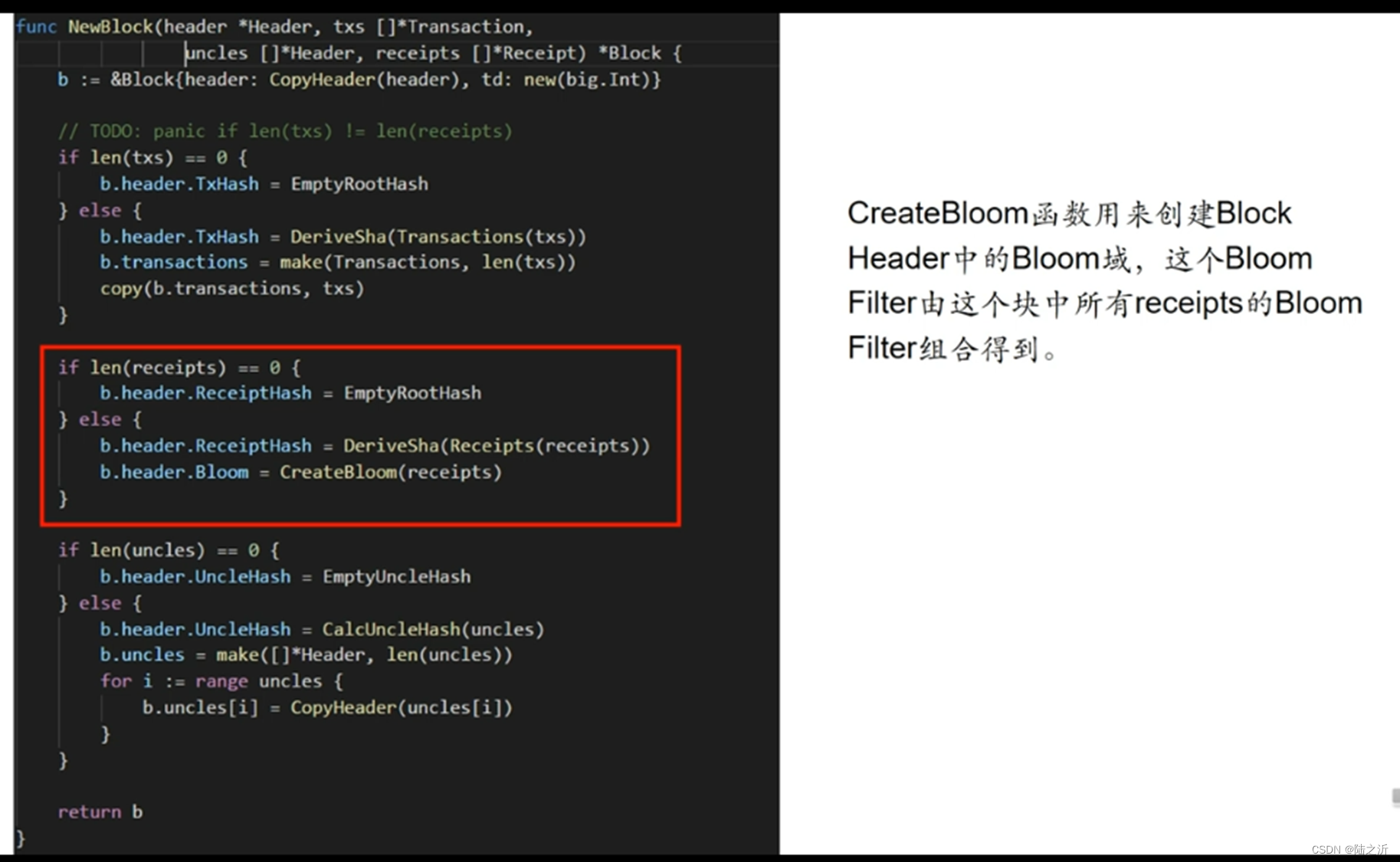
三个函数的代码实现。createBloom的参数是所有的收据,最后生成整个区块的bloom;logsBloom是用来生成每个收据的bloom filter,bloom9是用来bloom filter中使用的哈希函数。
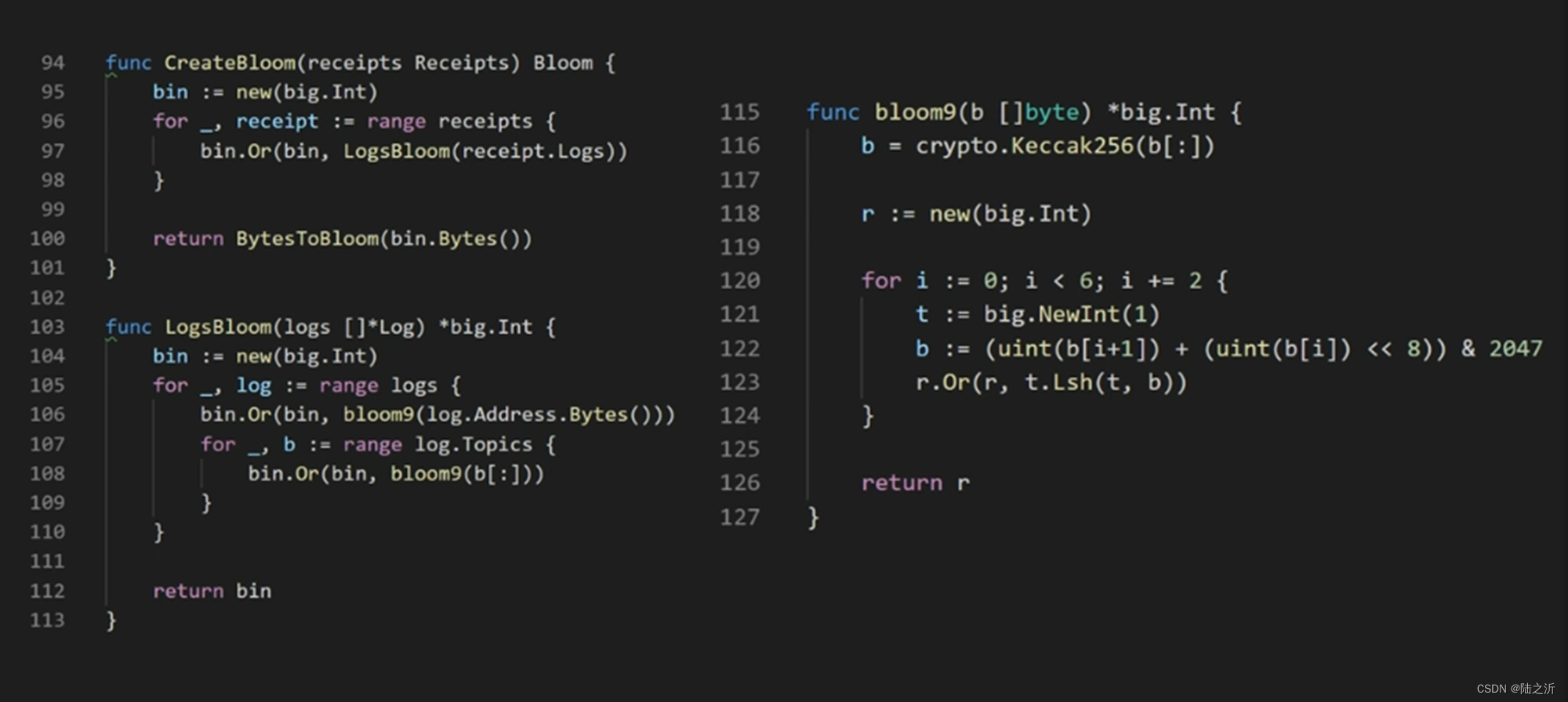
bloomLookup是查找对应的数据是否在bloom过滤器里。
六、ETH-GHOST协议
以太坊的出块时间和比特币的相比,大幅度降低出块时间后也带来了些新的问题。
比特币和以太坊都是运行在应用层的共识协议,底层是一个P2P的网络,这个网络本身的传输时间是比较长的,因为它的拓扑协议没有考虑实际的拓扑结构。这就带来一个问题,发布区块后,区块在网络上传输到其他节点可能需要十几秒时间,对于比特币来说时间足够,但仍有可能有两个矿工同时发布区块,会产生临时性分叉,但是对于以太坊,这种临时性分叉就会变成常态,而且分叉数目也会更多。
上述对于共识协议的挑战:
比特币系统中,不是在最长合法链上挖到的区块是会作废;在以太坊系统中,这样会意味着矿工挖到的区块很大概率白挖了,对挖到矿的矿工不是很公平,特别是个体矿工。
以太坊沿用比特币的共识机制会有一定问题。调整出块难度是为了稳定出块时间,不是越短越好。
以太坊采用了一个基于GHOST协议的共识机制,这个GHOST不是以太坊发明的,是对它进行了一些修改,这个协议的核心思想是对挖到矿后没有得到认可的区块,系统给矿工一些出块奖励安慰,被作废的区块叫做uncle block。
Uncle block相当于最长合法链的叔父区块,最长合法链的区块在发布时可以把叔父区块包含进来,这样叔父区块可以得到八分之七的出块奖励。对最长合法链的区块如果包含了叔父区块,可以额外得到32分之一的出块奖励,本身挖到也有出块奖励,一个区块最多可以包含两个叔父区块,包含一个得一份32分之一,两个就有两份。
这样设计有利于鼓励系统中出现分叉后及时进行合并。
这个是最初版本的GHOST协议
如何确认是uncle block:
当多个区块A,B,C同时发布,A区块监听到B区块发布了,A继续挖下一个区块,可以把B认为是uncle block,在挖下一区块时监听到C区块也发布了,可以修改块头,把C添加进uncle block,再进行挖矿。
最长合法链把区块作为叔父区块的前提是已经监听到了新区块的存在。如果区块不包含叔父区块就会没有那些奖励了,对叔父区块损失较大,可能会有恶意节点这样做。
叔父可以拓展,不一定要当代叔父可以被包含。叔父区块必须和当前区块在七代以内有共同的祖先才算。合法的叔父只有六个辈份。
如果不限制叔父的辈分,对于全节点要维护的状态就会太多,有利于鼓励尽早进行合并分叉。
叔父区块的奖励是uncle reward,当前区块得到的奖励都是32分之一。
**设计GHOST协议主要目的是解决系统中的临时性分叉。**规定最长合法链是为了防止篡改,也是为了解决临时性分叉。如果分叉是别的原因造成的,那么这种协议解决不了。
比特币发布区块得到两部分奖励,一部分是block reward(静态),另一部分是tx fee ;以太坊也是,一部分是block reward ,另一部分是gas****Fee(执行智能合约)。
叔父区块得不到gas fee。
Gas fee 所占比例很小,占很小一部分。
以太坊中没有规定定期把出块奖励减半,比特币这么规定是认为制造稀缺性。
以太坊减少区块奖励和调整出块难度有关。
把叔父区块包含进最长合法链区块中,叔父区块中的交易要不要执行?
不用。叔父区块和最长合法区块包含的区块可能有冲突,如果执行了叔父区块,可能再执行其他区块就会变成不合法的。在包含叔父区块时,最长合法链上的区块不会检查叔父区块的合法性,只检查叔父区块是不是合法发布的,是否符合挖矿难度。
如果分叉后,不是最长合法链的分叉上有一串区块,这些区块算是最长合法链的叔父区块吗?
如果也算会导致分叉攻击太便宜,分叉攻击的风险大大降低了。
以太坊真实情况:
叔父区块的几种情况:
叔父区块的序号和区块序号的差值就是叔父区块和当前区块的距离。
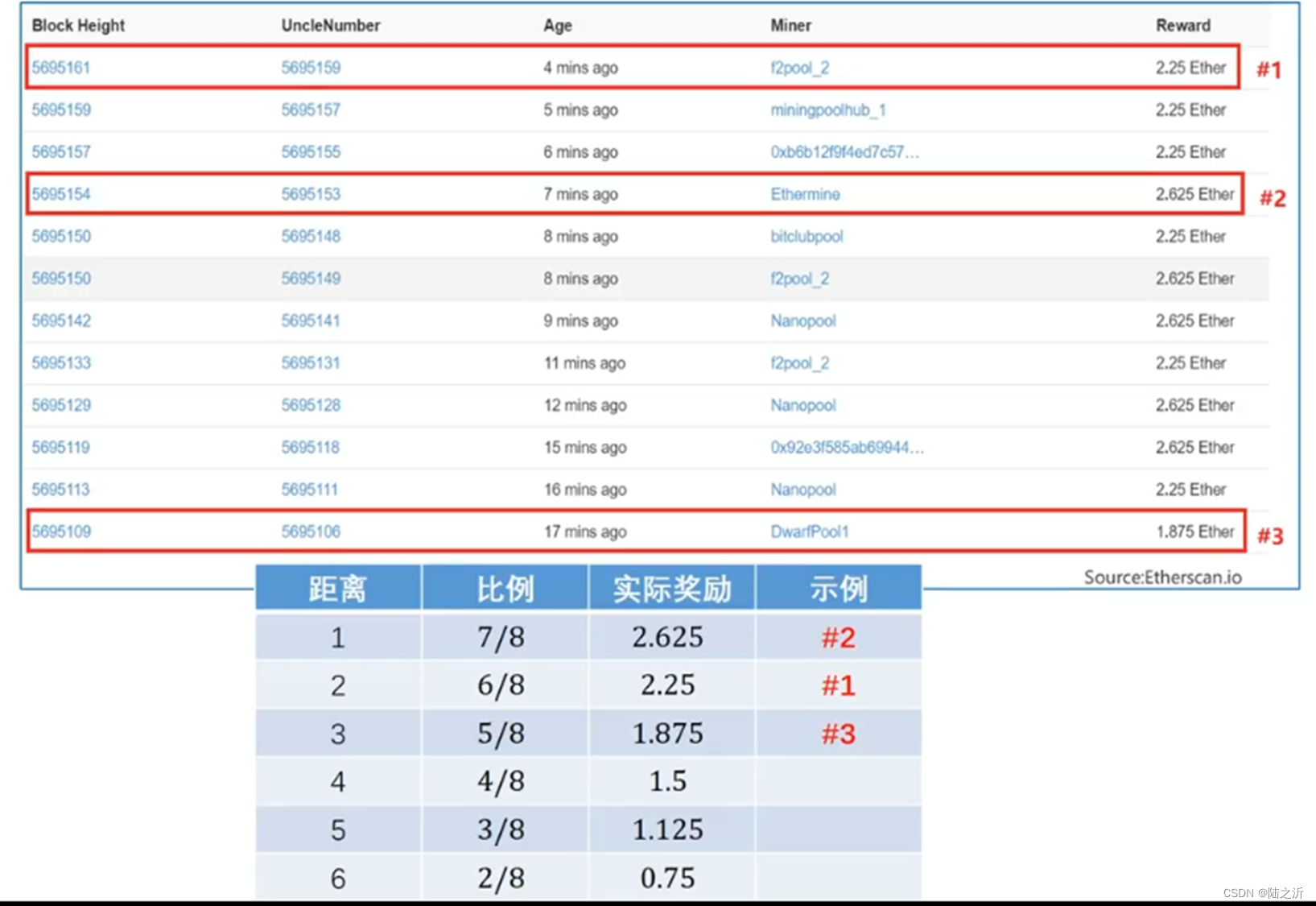
区块的具体例子:
