4.0交易树和收据树
每次发布一个区块时,区块中的交易会形成一颗Merkle Tree,即交易树。此外,以太坊还添加了一个收据树,每个交易执行完之后形成一个收据,记录交易相关信息。也就是说,交易树和收据树上的节点是一一对应的。 由于以太坊智能合约执行较为复杂,通过增加收据树,便于快速查询执行结果。
交易树和收据树都是MPT(Merkle Patricia tree),而BTC中都采用普通的MT(Merkle Tree)。可能就仅仅是为了三棵树代码比较统一,便于管理,不一定非要有其他的原因。
MPT的好处是支持查找操作,通过键值沿着树进行查找即可。对于状态树,查找键值为账户地址;对于交易树和收据树,查找键值为交易在发布的区块中的序号,交易的排列顺序是由发布交易的那个节点决定的。
交易树和收据树只将当前区块中的交易组织起来,而状态树将所有账户的状态都包含进去,无论这些账户是否与当前区块中交易有关系。多个区块的状态树是共享节点,只有改变状态的那个节点需要新建分支,而交易树和收据树依照区块独立。
交易树和收据树的用途:
-
向轻节点提供Merkle Proof。
-
更加复杂的查找操作(例如:查找过去十天所有跟某个智能合约相关的交易;过去十天的众筹事件等)
Bloom filter(布隆过滤器)
支持较为高效查找某个元素是否在某个集合中。 最笨的方法:元素遍历,复杂度为O(n),而且需要存储整个交易列表——轻节点不能用 改进的方法:给一个大的集合,计算出一个紧凑的“摘要”。
例:如下图,给定一个数据集,其中含义元素a、b、c,通过一个哈希函数H()对其进行计算,将其映射到一个其初始全为0的128位的向量的某个位置,将该位置置为1。将所有元素处理完,就可以得到一个向量,则称该向量为原集合的“摘要”。可见该“摘要”比原集合是要小很多的。 假定想要查询一个元素d是否在集合中,假设H(d)映射到向量中的位置处为0,说明d一定不在集合中;假设H(d)映射到向量中的位置处为1,有可能集合中确实有d,也有可能因为哈希碰撞产生误报。

Bloom filter特点:有可能出现误报,但不会出现漏报。 Bloom filter变种:不是采用一个哈希函数,是采用一组哈希函数进行向量映射,如果出现哈希碰撞,不会所有的哈希函数都出现碰撞。
如果集合中删除元素该怎么操作? 无法操作。也就是说,简单的Bloom filter不支持删除操作。如果想要支持删除操作,需要将记录数不能为0和1,需要修改为一个计数器(需要考虑计数器是否会溢出)。就变复杂了,与设计初衷相违背。
4.1 以太坊中的Bloom filter的作用
每个交易完成后会产生一个收据,收据包含一个Bloom filter来记录交易类型、地址等信息。在区块block header中也包含一个总的Bloom filter,其为该区块中所有交易的Bloom filter的一个并集。
那如何查过去十天与这个智能合约相关的所有交易呢?
先查一下哪个区块的块头中有我需要的交易的Bloom filter,如果块头中的Bloom filter中有的话,再去查找这个区块里面包含的交易,所对应的收据树里面的每个收据的Bloom filter,也可能都没有,则发生了误报;如果有的话,我们再找到相对应的交易直接再进行确认。 好处是通过Bloom filter这样一个结构,快速大量过滤掉大量无关区块,从而提高了查找效率。
4.2 补充
以太坊的运行过程,可以视为交易驱动的状态机,通过执行当前区块中包含的交易,驱动系统从当前状态转移到下一状态。当然,BTC我们也可以视为交易驱动的状态机,其状态为UTXO。对于给定的当前状态和给定一组交易,可以确定性的转移到下一状态(保证系统一致性)。
问题1:A转账到B,有没有可能收款账户不包含再状态树中? 可能。因为以太坊中账户可以节点自己产生,只有在产生交易时才会被系统知道。 问题2:可否将每个区块中状态树更改为只包含和区块中交易相关的账户状态?(大幅削减状态树大小,且和交易树、收据树保持一致) 不能。这样设计要查找账户状态很不方便,如果A要转账10个ETH,那系统首先要查A有没有10个ETH,就需要一直往前找,找到最近的一个包含A的区块才能转账。如果要向一个新创建账户转账,因为需要知道收款账户的状态,才能给其添加金额,但由于其是新创建的账户,所有需要一直找到创世纪块才能知道该账户为新建账户。
4.3 从代码中看具体的数据结构
-
交易树和收据树的创建过程

DeriveSha 来得到交易树和收据树的根哈希值。
CalcUncleHash 得到哈希值。
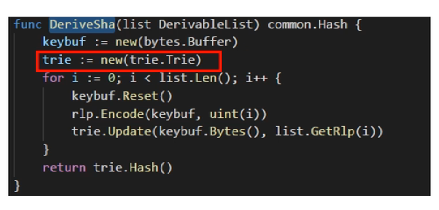
derive_sha.go中,DeriveSha函数把Transactions和Receipts建为trie。
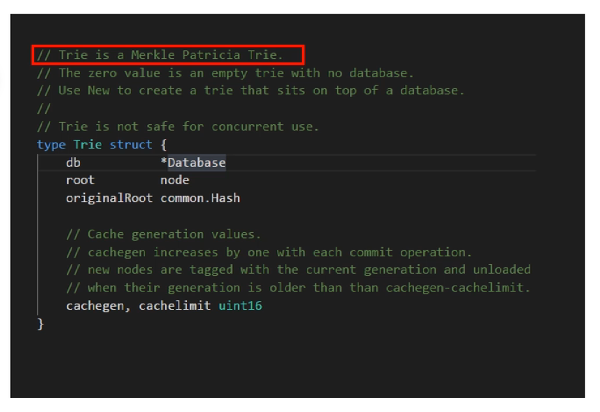
而trie的数据结构是MPT
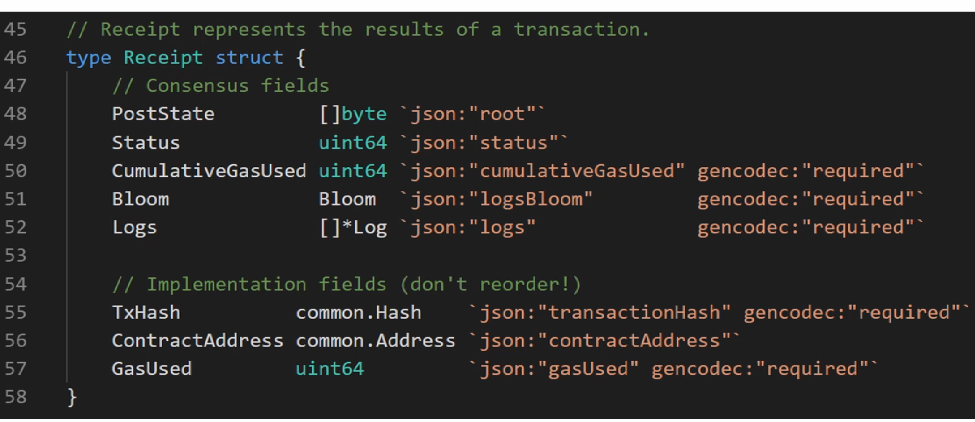
这是Receipt的数据结构,每个交易执行完成后形成一个收据,记录了这个交易的执行结果。
这个Bloom域就是指Bloom filter,log域是个数组,每个收据可以包含多个log。这些收据的Bloom filter就是根据这些log产生出来的。

这是区块块头的数据结构。这里的Bloom就是每个区块的Bloom filter,是由每个区块中所有收据的Bloom filter合并出来的。

再来看第一张图,CreateBloom函数用来创建BlockHeader中的Bloom域,这个Bloom Filter由这个块中所有receipts的Bloom Filter组合得到。

CreateBloom函数的参数是这个区块的所有收据,for循环是遍历所有的收据,并对每个收据调用LogsBloom函数获得这个收据的Bloom filter,用Or操作合并起来。得到整个区块的Bloom filter。
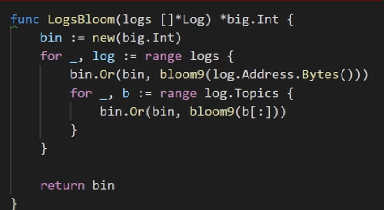
LogsBloom的作用是生成每个收据的Bloom filter,参数是这个收据的Logs数组,这个函数有两层for循环,外层for循环对Logs数组中每个log进行处理,首先对这个log的地址取哈希后加入到Bloom filter里面,这里的bloom9是Bloom filter用的哈希函数。然后内层循环把这个log中包含的每个Topics加入到Bloom filter里面,这样就得到了这个收据的Bloom filter。

bloom9是Bloom filter中使用的哈希函数,这里的bloom9函数是把输入映射到digest的三个位置,也就是说把三个位置都置为1,b为32个字节的哈希值,循环中把32个字节的哈希值取前6个字节,每两个字节组成一组,&2047意味着对2048取余。因为以太坊中Bloom filter的长度为2048位。最后一行,把1左移这么多位,通过Or运算,合并到上一轮得到的bloom filter里面,这样经过3轮循环把3个位置置为1后返回所创建的bloom filter。

BloomLookup为查询bloom filter里是否包含了我们感兴趣的topic,先使用Bloom9函数把topic转化为big.Int,然后把它和bloom filter取and操作,因为bloom filter一定会包含其他topic的Bloom filter,取and就是把这个cmp“提取出来”,再与自身的big.Int比较是否相等。