一、工作量证明(POW)
1.比特币系统的工作量证明
对于基于工作量证明的系统来说,Mining是保障区块链安全的重要手段(Block chain is secured by mining),比特币里面的Mining算法总的来说是比较成功的,经受了时间检验,到目前为止,没有人发现有什么大的漏洞。
Bounty(赏金),Bug Bounty:有的公司悬赏来找软件中的漏洞,如果能找到软件中的安全漏洞就可以得到一笔赏金。比特币的Mining算法是一个天然的Bug Bounty,如果你能找到里面的漏洞,或者是某一个Mining的捷径就能取得很大的利益。但是到目前为止还没有人发现有什么捷径可走,所以比特币的Mining算法总的来说是比较成功的。
2.比特币系统Mining算法的问题
比特币的Mining算法也有一些值得改进得地方,其中有一个饱受争议得问题就是Mining设备得专业化,有普通的计算机挖不倒矿,只能用专门的设备,专用的ASIC芯片来Mining,那么很多人认为这种做法与去中心化的理念是背道而驰的,也跟比特币的设计初衷相违背。中本聪最早的一篇论文,提出One CPU,one vote,理想状况下,应该让普通老百姓也能参与Mining过程,这样也更安全,因为算力分散之后,有恶意的攻击者想要聚集到51%的算力发动攻击,难度就会大得多。所以比特币之后出现的加密货币包括以太坊设计Mining Puzzle的时候,就想要做到ASIC Resistance。
3.如何设计出对ASIC芯片不友好的Mining Puzzle
一个常用的做法就是增加Mining Puzzle对内存访问的需求(memory hard mining puzzle)。ASIC芯片相对于普通计算机而言,主要优势是算力强,但是在内存访问的性能上没有那么大的优势。同样的价格买一个ASIC矿机和买一个普通的计算机,这个ASIC矿机的计算能力是普通计算机的几千倍,但是内存访问方面的性能差距远没有这么大,所以能设计出一个对内存要求很高的Puzzle,就能起到遏制ASIC芯片的作用。
4.LiteCoin
LiteCoin(莱特币),曾经是市值仅次于比特币的第二大加密货币,其Puzzle是基于Scrypt(一个对内存要求很高的哈希函数,以前用于计算机安全领域,跟密码相关)。其具体设计思想是,开一个很大的数组,然后按照顺序填充一些伪随机数,比如说有一个种子节点,seed的值通过一些运算,算出一个数来,填在第一个位置,然后后面每个位置都是前一个位置的值取哈希得到的,如图1-1所示。

伪随机数是说取哈希值后的值是不知道的,不可能真的用随机数,不然就没法验证。填充完后,里面的数有前后依赖关系,是从第一个数依次算出来的,需要求解这个puzzle的时候,按照伪随机数的顺序从数组当中读取一些数,每次读取的位置跟前一个数相关,如图1-2所示。

(1)LiteCoin的好处
如果这个数组开的足够大的时候,Miner就是Memory Hard,因为如果不保存数组,那么Mining的计算复杂度会大幅度上升,需要从头计算。所以要想高效地Mining,这个内存区域是需要保存的,有的矿工可能保存一部分内存区的内容,如,只保留数组中奇数位置的元素,这样数组可以少一半,用到偶数位置的数的话,要根据另外一半算一下,计算复杂度会提高一点,但是内存量可以减小一半,叫做time-memory trade off。
该设计的核心思想是不能像比特币那样主要进行哈希运算,要增加运算过程中对内存访问的需求,设计一个对ASIC芯片不友好的,普通计算机能参与的。设计的任务更像是普通计算机干的事情,而不是像一个Mining专用的ASIC芯片干的事情,普通计算机内存很大,就要利用这个特性,设计puzzle对资源的需求,特别像是普通计算机对资源的配备比例。
(2)LiteCoin的缺点
LiteCoin的优点是对于矿工Mining的时候是memory hard,缺点是对轻节点来说也是memory hard。设计puzzle的一个原则:difficult to solve,but easy to verify。这个问题在于验证这个puzzle需要的内存区域跟求解需要的区域几乎是一样,轻节点验证的时候也需要保存数组,否则计算复杂度也会大幅度提高。对于scrypt早期计算机的安全领域,不存在轻节点验证这个问题,但对于区块链来说是不行的。
(3)LiteCoin的实践
莱特币在真正使用的时候,这个内存区域不敢设置的太大,比如说设一个1G的数组,这对于计算机来说是不大的,但是如果是一个手机上的app,1G的内存可能就太大了。因为这个原因,实际莱特币在使用的时候,这个数组只有128Ks,连1M都不到,就是为了照顾轻节点。
当初莱特币在发行的时候,目标不仅仅是ASIC resistance,还是GPU resistance,就是Mining最好连GPU都不要用,都用普通的CPU Mining就行了。结果后来就出现GPU Mining的,再后来就出现用ASIC芯片Mining的,实践证明莱特币要求的128k内存不足以对ASIC芯片的生产和设计带来实际上的障碍。从这一点来说,莱特币的设计目标没有达到,但是早期宣传的设计目标对于解决能启动问题是很有帮助的。任何一个加密货币,都存在能启动问题,包括比特币,一开始的时候,没有人知道这个加密货币,发行一个货币,没有人参与,这是一个问题,对于基于工作量证明的加密货币来说,Mining人太少是不安全的,发动恶意攻击难度太低。
比特币早期也是不安全的,当时如果想对比特币发动恶意攻击是很容易的。比特币解决能启动的问题是一个循坏迭代的过程,中本聪宣传的多了,对比特币感兴趣的人就多了,参与Mining人就多了,变得更安全,价值也提高了;然后对比特币感兴趣的人就更多了,Mining的人也更多了,然后比特币变得更安全了,价值就更进一步提高了,形成一个良性循坏。
莱特币虽然没有达到当初的设计目标,但是他早期的宣传:更民主、让更多人参与的理念对于聚集人气来说是很重要的。所以莱特币一直到现在也是一个比较主流的加密货币,除了这个Mining Puzzle之外,莱特币跟比特币的另一个区别是来特比的出块速度是比特币的4倍,他的出块间隔是2min30s,而不是10min,除此之外,这两种加密货币基本上是一样的。
二、以太坊的工作量证明
1.Memory hard mining puzzle
以太坊也是用一种Memory hard mining puzzle,但是在设计上,跟莱特币有很大的不同。以太坊用的是两个数据集,一大一小,小的是16M cache,大的数据集是一个1G dataset,DAG,这1G的数据集是从16M的cache生成出来的,设计成一大一小的两个数据集呢,就是为了便于验证。轻节点只要保存16M cache就行了,只有需要挖矿的矿工才需要保存1G的dataset。
2.基本思想
Cache的生成方式跟LiteCoin中数组的生成方式是比较类似的,首先从一个种子节点seed,进行一些运算,算出数组的第一个元素,然后依次取哈希,第一个元素取哈希得到第二个元素,第二个元素取哈希得到第三个元素,依此类推,把这个数组从前往后,填充一些伪随机数得到一个cache。然后生成一个更大的数组DAG,大数组要比小数组大得多,DAG的每个元素都是从cache里按照伪随机数的顺序读取一些元素,方法和刚才讲的莱特币里面求解puzzle的过程类似。第一次读取A位置的元素,读取完之后,对当前的哈希值进行一些更新迭代,算出下一个要读取的位置,比如说B这个位置,然后把B位置的数再进行一些哈希值的更新,算出C这个位置,那么从这个cache里面这么来回读,一共读256次,读256个数,最后算出来一个数放在大的dataset的第一个元素,然后第二个元素也是一样的,dataset的每个元素都是从这个cache里面按照伪随机数的顺序,不断进行迭代更新,最后得到一个值存在里面,然后求解puzzle的时候,用的是大数据集中的数,这个cache是不用的,按照伪随机数的顺序在大的数据集中读取128个数,就是一开始的时候根据区块的块头,包括里面的nonce值算出一个初始的哈希,根据这个哈希,映射到大数据集里面的某个位置,把这个数读取出来,然后进行一些运算,算出下一个要读取的位置,比如说又在大数据集里面的另一个位置,又把这个数读取出来。这里有一个区别:他每次读取的时候除了计算出这个元素的位置之外,还要把相邻元素(该元素的下一个元素)也要读取出来,这个例子当中每次读取的时候是读取两个相邻元素,这样循环64次,每次读两个元素,所以一共是符合难度要求128个数。最后算出一个哈希值来,跟挖矿难度的目标域值比较是不是符合难度要求,如果不是,把Block Header 里面的Nonce替换一下,换另外一个Nonce,因为换了Nonce之后,第一次算的那个哈希值就变了,然后重复这个过程,再去比较。
3.ethash算法伪代码
(1)生成16M cache。
def mkcache(cache_size,seed):
o = [hash(seed)]
for i in range(1,che_size):
o.append(hash(o[-1]))
return 0cache中每个元素都是64个字节的哈希值,生成的方法与莱特币类似(第一个元素是Seed的哈希,后面每个元素是前一个的哈希),哈希的内容每隔3万个区块会变化一次,Seed每隔3万个区块会发生变化,然后重新生成cache中的内容,同时cache的容量要增加原始大小的1/128,也就是16M的1/128=128K。
(2)通过cache来生成dataset中的第i个元素。
def calc_ dataset item(cache,i):
cache size = cache.size
mix hash(cache[i % cache_size] ^ i)
for j in range(256):
cache_ index = get_ int_ from_item(mix)
mix = make_item(mix,cache[cache_index % cache_size])
return hash(mix)
基本思想是按照伪随机数的顺序读取cache中的256个数,每次读取的位置是由上一个位置的数值经过计算得到的,这里用的两个函数get_int_from_item和make_item,是自己定义的,源代码中是没有的,把源代码中一些相关的内容总结成了这两个函数,可以避免源代码中不是很重要的细节,get_int_from_item函数就是用当前算出来的哈希值求出下一个要读取的位置,然后make_item函数用cache中这个位置的数和当前的哈希值计算出下一个哈希值,这样迭代256轮,最后得到一个64字节的哈希值,作为大数据集中的第 i 个元素。
(3)calc_dataset是生成整个1G数据集的过程,就是不断调用前的函数来依次生成大数据集中的每个元素。
def calc_dataset(full_size, cache);
return [calc_ dataset_item(cache,i) for i in range(full_size)](4)矿工用来Mining的函数。
def hashimoto_full(header,nonce,full_size,dataset):
mix = hash(header,nonce)
for i in range(64) :
dataset_index = get_int_from item(mix) % full_size
mix = make_item(mix,dataset[dataset_index])
mix = make_item(mix, dataset[dataset_index + 1])
return hash(mix)
矿工用来Mining的函数,有四个参数,header是当前要生成的区块的块头,以太坊和比特币一样,Mining只用到块头的信息,这样设计的原因是轻节点只下载块头,就可以验证这个区块是否符合Mining的难度要求,第二个参数nonce就是当前尝试的nonce值,第三个参数full_size是大数据集中元素的个数,元素的个数每3万个区块会增加一次,增加原始大小的1/128也就是1G的1/128=8M,最后参数dataset就是前面生成的大数据集。
Mining的过程是这样的,首先根据块头的信息,和当前Nonce算出一个初始哈希值,然后要经过64轮的循环,每一轮循环读取大数据集中两个相邻的数,读取的位置是由当前哈希值计算出来的,然后再根据这个位置上的数值来更新当前的哈希值,这跟前面生成大数据集的方法是类似的,循环64次,最后返回一个哈希值,跟挖矿难度目标域值相比较。
每次读取大数据集中两个相邻位置的哈希值,这两个哈希值其实并没有什么联系,他们虽然位置相邻,但是生成的过程是独立的,每个都是由前面那个16M的cache中的256个数生成的,而且256个数的位置是按照伪随机数的顺序产生的,这个是构造大数据集的一个特点,每个元素独立生成,这才给轻节点的验证提供了方便,所以每次读取的相邻两个位置的哈希值是没有什么联系的。
(5)轻节点用来验证的函数。
def hashimoto light(header,nonce,full_size,cache):
mix = hash(header, nonce)
for i in range(64):
dataset_index = get_int _from item(mix) % full_size
mix = make_item(mix,calc_ dataset _item(cache,dataset_index))
mix = make_item(mix,calc_dataset_item(cache,dataset_index + 1))
return hash(mix)
这个函数也是有四个参数,含义跟上面那个矿工用的函数有所不同,轻节点不Mining,当他收到某个矿工发的区块的时候,这里用来验证的函数的第一个参数header是这个区块的块头,第二参数是包含在这个块头里的nonce,是发布这个区块的矿工选好的,轻节点的任务是验证这个nonce是否符合要求,验证用的是16M的cache,也就是最后的参数cache,注意,第三个参数full_size仍然是大数据集的元素个数,跟上面那个Mining的那个full_size含义是一样的,并不是cache中的元素个数,验证的过程也是64轮循环,看上去与Mining的过程类似。
特殊地,每次需要从大数据集中读取元素的时候,因为轻节点没有保留大数据集,所以要从cache中重新生成其他地方的代码逻辑是一样的,每次从当前的哈希值算出要读取的元素的位置,这个位置是指在在大数据集中的位置,但是轻节点并没有这个大数据集,所以要从cache中生成大数据集中这个位置的元素,我们前面说过大数据集中每个元素都可以独立生成出来。
(6)矿工Mining的主循环
def mine(full size,dataset,header,target):
nonce = random.randint(0,2**64)
while hashimoto_full(header,nonce,full_size,dataset) > target:
nonce = (nonce + 1) % 2**64
return nonce这个函数,其实是不断尝试nonce的过程,这里的target就是Mining的难度目标,跟比特币类似,也是可以动态调整的,nonce的可能取值是从0-2的64次方,对每个nonce用前面讲的那个函数算出一个哈希值,看看是不是小于难度目标,如果不行的话,就再试下一个nonce。
(7)函数汇总
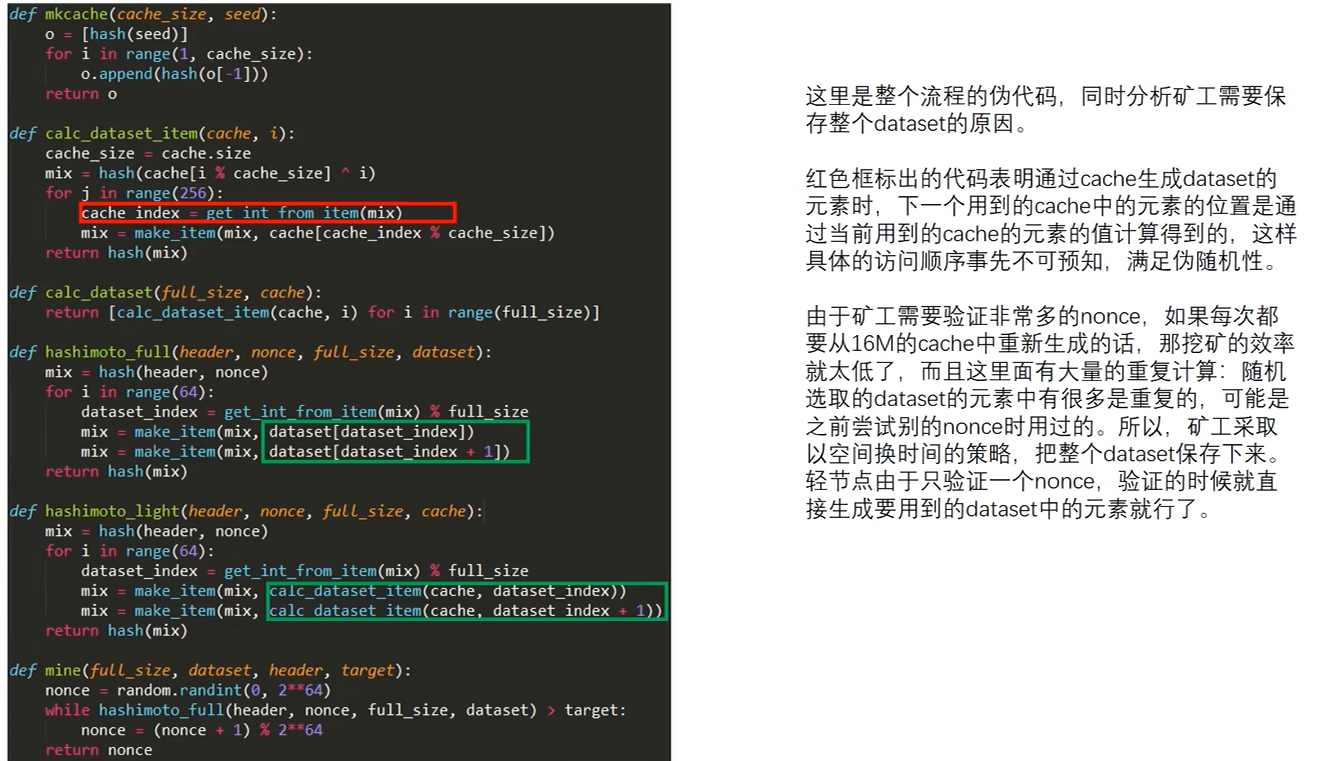
同时解释了为什么轻节点可以只保存cache,而矿工要保存整个大数据集。其实轻节点做一次验证的计算量也不算少,同样要经过64轮循环,每次循环用到大数据集中的两个数,所以是128个数,每个数是从cache里的256个数计算得到的,跟比特币相比,以太坊中验证一个nonce的计算量要大很多,但是仍然在可以接受的范围内,相比之下,如果矿工每次都这么折腾的话,代价就太大了,因为要尝试的nonce就太多了。
4.实际效果
目前为止,以太坊Mining主要还是以GPU为主,用ASIC矿机的很少,所以从这一点来说,他比莱特币来说要成功,起到了ASIC Resistance的作用,这个跟以太坊的Mining算法需要的大内存是很有关系的,这个Mining算法就是ethash。矿工Mining需要1G的内存,跟莱特币的128K比差别非常大,即使是16M的cache跟128K比差距也很大。而且这个大小还会定期增长。
以太坊没有出现ASIC矿机还有另一个原因,以太坊从很早就计划要从工作量证明转移到权益证明,即PoW(Proof of Work)→PoS(Proof of Stake)。所谓的权益证明,就是按照所占的权益进行投票来形成共识,权益证明是不Mining,就类似于股份公司按照股票多少来进行投票。这对于ASIC矿机的厂商来说是个威胁,因为ASIC芯片的研发周期是很长的,一款芯片从设计→研发→流片到最后生产出来,研发周期很长,而且研发的成本也很高,将来以太坊转入权益证明之后,投入的研发费用就白费了。其实到目前为止,以太坊是基于工作量证明,以太坊很早就说要转入权益证明,但是转移的时间点一再往后推迟,到现在也没转过来,但是他不停的宣称要这么做,所以要想达到ASIC Resistance一个简单的办法就是不断地吓唬大家:大家注意哦,下面要搞权益证明就不Mining了,所以你就不要设计ASIC矿机了,你设计出来到时候也没用了,因为要设计一年嘛,一年以后,我们就不Mining了。
从历史看,以太坊成为一个主流的加密货币,其实就是最近两年的事情(2018),以前市值很小的时候,没有人会去设计ASIC芯片,因为划不来啊,无利可图,等到市值上来之后呢,你这么吓唬他几次,就能起到ASIC resistance的作用,这也是另外一方面的原因。
5.预挖矿
以太坊中采用了预Mining(pre-mining),所谓预pre-mining并不是说真的去Mining,而是说,在当初发行货币的时候,预留一部分货币给以太坊的开发者,有点像创业公司会留一部分股票给创始人和早期员工一样,将来这个加密货币成功了的话,这些预留的币就变得是很值钱了。
像以太坊的早期开发者,现在就都很有钱,比北大教授要有钱多了。比特币就没有采用pre-mining的模式,所有的比特币都是挖出来的,只不过早期的Mining的难度低。与pre-mining相关的一个概念叫pre-sale(就是把pre-mining预留的那些币通过出售的方法来换取一些资产用于加密货币的开发工作),有点类似于众筹,如果你看好这个加密货币的未来,可以在pre-sale的时候买入,将来这个加密货币成功之后呢,同样可以赚很大一笔钱。