LLaMA
GPT一代
模型堆叠了12个transformer的解码器层(有关transformer的内容可以参考Swin Transformer介绍 )。由于这种设置中没有编码器,这些解码器层将不会有普通transformer解码器层所具有的编码器-解码器注意力子层。但是它扔具有自注意力层。
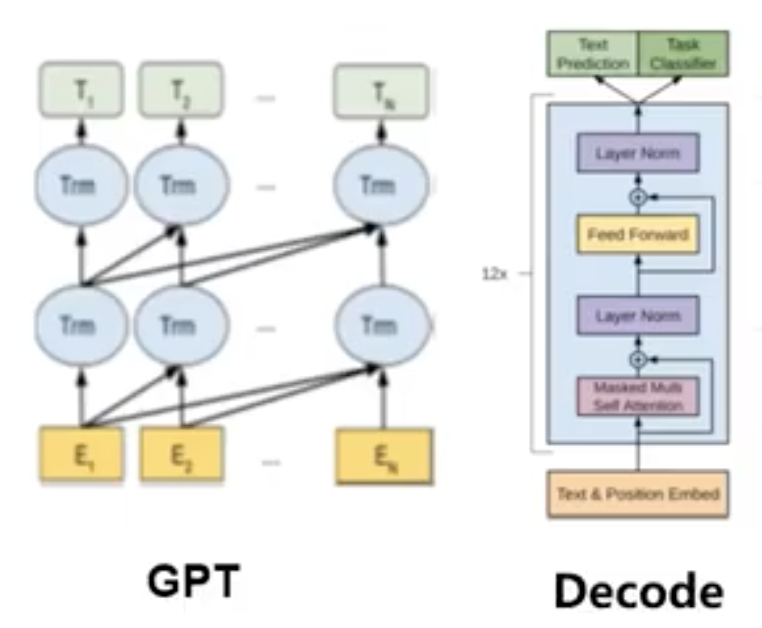
上图中的GPT包含了12个右边的Decode结构。它没有层级间的SW_MSA (偏移窗口自注意力机制),只有W_MSA (窗口自注意力机制)。
输入:
U = {\(u_1,...,u_n\)} 这里的\(u_i\)是一个一个的词向量,比如"我爱北京天安门",那么\(u_1\)就是"我",\(u_2\)就是"爱",\(u_3\)就是"北京",\(u_4\)就是"天安门"。
\(h_0 = UW_e + W_p\) 神经网络
\(h_l = transformer\_block(h_{l-1}) ∀i∈[1,n]\) 上一层的神经网络需要经过一个trannsformer_block抵达下一层神经网络
输出:
\(P(u) = softmax(h_nW_e^T)\)
- 训练过程
我们的训练目标就是让某一个词在某个句子中出现的概率最大化,这其实就是一个完形填空。
北京是中国的_____。 (首都)
那我们的目标函数就为
\(L_1(U) = \sum_ilogP(u_i|u_{i-k},...,u_{i-1};θ)\) θ是神经网络参数
这里的\(u_i\)就是"首都",条件概率中的条件\(u_{i-k},...,u_{i-1}\)就是"北京"、"是"、"中国"、"的"。我们的目的就是要使得概率P最大化。
如此,我们就可以通过语料对该模型去进行一个训练。训练完了之后所得到的参数就可以去做推理测试。而LLaMA用到的语料包含了数万亿个词。
LLaMA背景介绍
LLaMA是一个基础语言模型的集合,参数范围从7B到65B。
- 这些模型是在来自公开数据集的数万亿个tokens上训练的。
- 它由Meta(前Facebook)于2023年2月发布,作为致力于开放科学和人工智能实践的一部分。
- 它与其他大型语言模型的关联
- LLaMA与GPT、GPT-3、Chinchilla和PaLM等其他大型语言模型类似,因为它使用Transformer architecture来预测给定单词或token序列作为输入的下一个单词或token。
- 然而,LLaMA与其他模型的不同之处在于,它使用在更多token上训练,得到较小模型,这使它更高效,资源密集度更低。
- LLaMA发展史
InstructGPT(基于提示学习的一系列模型) -> GPT3.5时代(大规模预训练语言模型,参数量超过1750亿) -> ChatGPT模型(高质量数据标注以及反馈学习(强化学习) -> LLaMA
- LLaMA的特点
- 参数量和训练语料:LLaMA有四种尺寸,7B、13B、33B和65B参数。最小的模型LLaMA 7B在一万亿个tokens上进行训练,而最大的模型LLaMA 65B在1.4万亿个tokens上训练。
- 语种:LLaMA涵盖了20种使用者最多的语言,重点是那些使用拉丁字母和西里尔字母的语言。这些语言包含英语、西班牙语、法语、俄语、阿拉伯语、印地语、汉语等。
- 生成方式:和GPT一样。
- 所需资源更小:LLaMA比其他模型更高效,资源密集度更低,因为它使用在更多tokens上训练的较小模型。这意味着它需要更少的计算能力和资源来训练和运行这些模型,也需要更少的内存和带宽来存储和传输它们。例如LLaMA 13B在大多数基准测试中都优于GPT-3(175B),而只使用了约7%的参数。
- 它对研究界很重要
- 它能够在人工智能领域实现更多的可访问性和个性化(垂直领域)。
- 通过共享LLaMA的代码和模型,Meta允许其他无法访问大量基础设施的研究人员研究,验证和改进这些模型,并探索新的用例和应用程序。
- 开源!
训练方式与训练数据
LLaMA模型训练方法和GPT-3差不多,都是自回归的方式(依据前/后出现的子词来预测当前时刻的子词)。在大量的语料中,使用标准的transformer优化器进行模型的训练。
- 数据集
LLaMA是用Common Crawl这个大规模的网络文本数据集和其他开源数据集来训练的。Common Crawl是一个公开的网络文本数据集,它包含了从2008年开始收集的数千亿个网页的原始数据、元数据和文本提取。另外进行了一些预处理,来确保数据的质量要求:
使用了fastText线性分类器执行语言识别以删除非英语页面,使用n-gram语言模型过滤低质量内容。
下载地址(42B tokens,300d vectors,1.75G):https://huggingface.co/stanfordnlp/glove/resolve/main/glove.42B.300d.zip
下载地址(840B tokens,300d vectors,2.03G):https://huggingface.co/stanfordnlp/glove/resolve/main/glove.840B.300d.zip
训练数据集是多个来源混合,如下表所示,涵盖了不同的领域
| 数据集 | 采样比例 | 训练轮数 | 数据集大小 |
| CommonCrawl | 67.0% | 1.10 | 3.3T |
| C4 | 15.0% | 1.06 | 783G |
| Github | 4.5% | 0.64 | 328G |
| Wikipedia | 4.5% | 2.45 | 83G |
| Books | 4.5% | 2.23 | 85G |
| ArXiv | 2.5% | 1.06 | 92G |
| StackExchange | 2.0% | 1.03 | 78G |
C4数据集是一个巨大的、清洗过的Common Crawl网络爬取语料库的版本。另外进行了一些不同的预处理,包含去重和语言识别步骤,与CommmonCrawl的主要区别在于质量过滤,它主要依赖于启发式方法,例如对网页中的标点符号的过滤,或者限制单词和句子的数量。
GitHub是使用Google BigQuery上可用的公共GitHub数据集。只保留在Apache、BSD和MIT许可证下分发的项目。根据行长或字母数字字符的比例使用启发式方法过滤了低质量文件。在文件级别对生成的数据集进行重复数据删除。
Wikipedia添加了2022年6月至8月期间的维基百科数据,涵盖20种语言,使用拉丁文或西里尔文脚本。
以上这些数据集的下载地址可以参考https://zhuanlan.zhihu.com/p/612243919?utm_id=0
模型结构
LLaMA的网络也是基于Transformer架构。并且对Trannsformer架构进行了部分改进。
- LLaMA方法——Pre-normalization
为了提高训练稳定性,对每个Transformer子层的输入进行归一化,而不是对输出进行归一化。这个叫RMSNorm归一化函数。
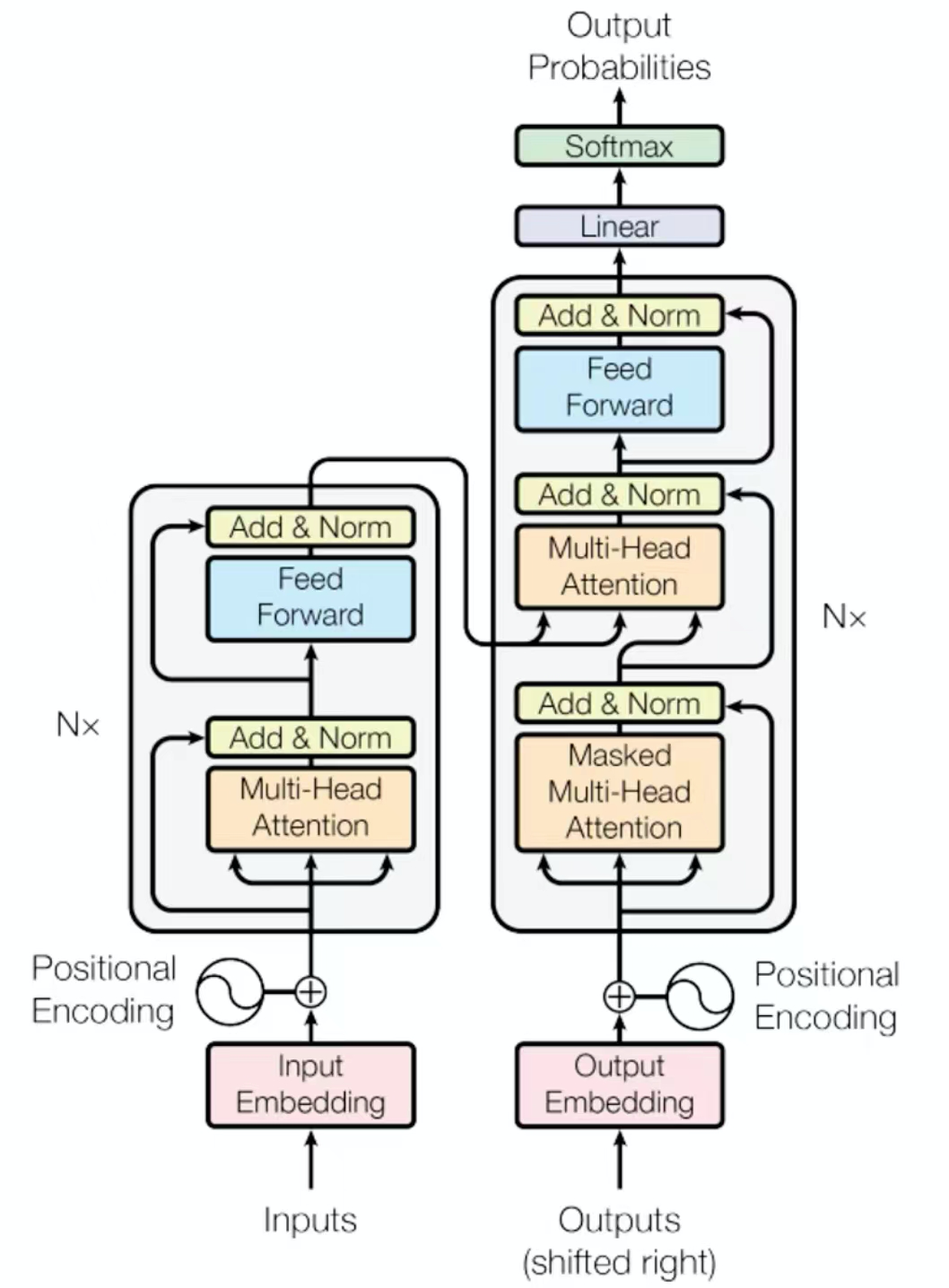
上图是传统的Transformer的编解码器,无论是编码器还是解码器,它们都有一个Add & Norm层,Add代表残差连接,Norm则是批归一化(有关批归一化的内容可以参考Tensorflow技术点整理 中的归一化与批归一化)。LLaMA有8组编解码器。
而LLaMA则是把Norm批归一化放到多头注意力机制之前,而通过Multi-Head Attention之后不再进行归一化处理。因为大模型的参数量很大,要进行稳定的训练是比较困难的。
\(RMSNorm(x) = {x \over \sqrt {{1\over n}\sum_{i=1}^nx_i^2+ξ}}\)
其中x是输入的向量,n是向量的长度,ξ是一个很小的常数,用于避免分母为0。
- LLaMA方法——SwiGLU激活函数
SwiGLU激活函数代替ReLU非线性,以提高性能。
好处是:
- SwiGLU激活函数的收敛速度更快,效果更好。
- SwiGLU激活函数和ReLU都拥有线性的通道,可以使梯度很容易通过激活的units,更快收敛。
- SwiGLU激活函数相比ReLU更具有表达能力。
SwiGLU激活函数的收敛速度更快,这是因为它在计算过程中使用了门控机制,可以更好地控制信息的流动。
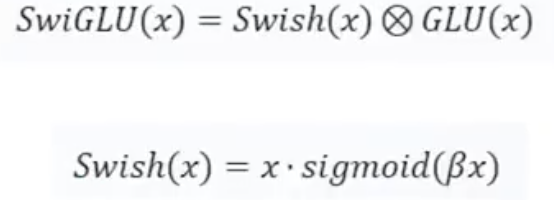
对于一些不重要的信息,我们就会让门完全关闭,而对于很重要的信息,则可以让门完全打开。SwiGLU是以门线性单元GLU为基础的,它是一个双线性函数,表达式为
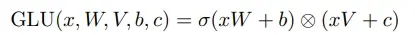
这里的 ⊗ 表示矩阵的逐元素相乘,关于门控机制可以参考Tensorflow深度学习算法整理(二) 中的长短期记忆网络以及GRU。
- LLaMA方法——Rotary Embedding
删除了绝对位置嵌入,取而代之的是在网络的每一层中添加了旋转位置嵌入。
旋转位置嵌入的主要思想是将位置信息编码为一个旋转矩阵,然后将该矩阵与输入向量相乘,从而得到一个新的向量表示。这种方法可以更好地捕捉序列中不同位置之间关系,从而提升模型的性能。(有关旋转矩阵的内容可以参考线性代数整理 中的图形变换矩阵 (向量的函数))
虽然Transformer一般是处理文字数据的,但是它跟接近于CNN而不是RNN,对于句子中所有的输入tokens是同时送入网络并行处理的,而RNN是将句子中的tokens一个一个送入循环神经网络的,为了表征句子中词的位置关系,于是就有了位置编码Position Embedding。之前的位置编码又分为绝对位置和相对位置,绝对位置就是按照原句的顺序进行编码,如"我爱北京天安门",那么编码后就是"我"——1、"爱"——2、"北京"——3、“天安门”——4。一般来说Position Embedding会有一个长度限制——512。相对位置是以某一个词为基准来定义位置的,如"我爱北京天安门"中以"北京"为基准,那么"北京"的位置为0,"爱"——-1,"我"——-2,"天安门"——1。
LLaMA使用的是旋转位置嵌入,它可以更好的处理序列中的旋转对称性。在传统的位置编码方法中,位置信息只是简单的编码为一个向量,而没有考虑到序列中的旋转对称性。而旋转位置嵌入则将位置信息编码为一个旋转矩阵,从而更好的处理序列中的旋转对称性。
旋转对称性是指物体在旋转后仍然具有相同的性质。例如,一个正方形在旋转90度后仍然是一个正方形,因此具有旋转对称性。在句子序列中,旋转对称性指的是序列中的某些部分可以通过旋转变换得到其他部分。例如,在机器翻译任务中,源语言句子和目标语言句子之间存在一定的对称性。这意味着我们可以通过将源语言句子旋转一定角度来得到目标语言句子。
源码分析与解读
最核心的当然是Transformer
class Transformer(nn.Module): def __init__(self, params: ModelArgs): super().__init__() self.params = params # 类实例参数 self.vocab_size = params.vocab_size # 词向量维度 self.n_layers = params.n_layers # 层数 # 获取词向量 self.tok_embeddings = ParallelEmbedding( params.vocab_size, params.dim, init_method=lambda x: x ) # 添加所有的TransformerBlock,共8层 self.layers = torch.nn.ModuleList() for layer_id in range(params.n_layers): self.layers.append(TransformerBlock(layer_id, params)) # 置前的批归一化 self.norm = RMSNorm(params.dim, eps=params.norm_eps) # 线性特征提取 self.output = ColumnParallelLinear( params.dim, params.vocab_size, bias=False, init_method=lambda x: x ) # 计算旋转位置嵌入Rotary Embedding self.freqs_cis = precompute_freqs_cis( self.params.dim // self.params.n_heads, self.params.max_seq_len * 2 ) @torch.inference_mode() def forward(self, tokens: torch.Tensor, start_pos: int): # 获取句子输入的batchsize和句子的长度 _bsz, seqlen = tokens.shape # 将句子变成词向量 h = self.tok_embeddings(tokens) # 旋转位置嵌入 self.freqs_cis = self.freqs_cis.to(h.device) freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen] mask = None if seqlen > 1: mask = torch.full((1, 1, seqlen, seqlen), float("-inf"), device=tokens.device) mask = torch.triu(mask, diagonal=start_pos + 1).type_as(h) # 将词向量(或隐层表示)送入到每一层的Transformer block for layer in self.layers: h = layer(h, start_pos, freqs_cis, mask) # 批归一化 h = self.norm(h) # 线性特征提取 output = self.output(h[:, -1, :]) # only compute last logits return output.float()
然后是Transformer block,它就是layers中的每一层
class TransformerBlock(nn.Module): def __init__(self, layer_id: int, args: ModelArgs): super().__init__() self.n_heads = args.n_heads # 多头 self.dim = args.dim # 句子中词向量的最大数量 self.head_dim = args.dim // args.n_heads # 多头头数 self.attention = Attention(args) # 自注意力机制 # 前馈神经网络 self.feed_forward = FeedForward( dim=args.dim, hidden_dim=4 * args.dim, multiple_of=args.multiple_of ) self.layer_id = layer_id # 批归一化 self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps) self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps) def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]): # 这里的第一步就是批归一化,然后经过自注意力机制运算再接一个残差连接 h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_cis, mask) # 上一步的输出再经过前馈神经网络再接一个残差连接 out = h + self.feed_forward.forward(self.ffn_norm(h)) return out
然后是Attention
class Attention(nn.Module): def __init__(self, args: ModelArgs): super().__init__() # 注意力机制中的头 self.n_local_heads = args.n_heads // fs_init.get_model_parallel_world_size() # 注意力机制中头的长度 self.head_dim = args.dim // args.n_heads # 查询向量矩阵 self.wq = ColumnParallelLinear( args.dim, args.n_heads * self.head_dim, bias=False, gather_output=False, init_method=lambda x: x, ) # 键向量矩阵 self.wk = ColumnParallelLinear( args.dim, args.n_heads * self.head_dim, bias=False, gather_output=False, init_method=lambda x: x, ) # 值向量矩阵 self.wv = ColumnParallelLinear( args.dim, args.n_heads * self.head_dim, bias=False, gather_output=False, init_method=lambda x: x, ) # 合并后的矩阵 self.wo = RowParallelLinear( args.n_heads * self.head_dim, args.dim, bias=False, input_is_parallel=True, init_method=lambda x: x, ) # 将键词对进行缓存,以便于推理的时候更加方便 self.cache_k = torch.zeros( (args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim) ).cuda() self.cache_v = torch.zeros( (args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim) ).cuda() def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]): # 获取词向量的batchsize和长度 bsz, seqlen, _ = x.shape # 通过使用q、k、v的线性变换矩阵对词向量进行线性变换获得q、k、v xq, xk, xv = self.wq(x), self.wk(x), self.wv(x) # resize到各个头的大小 xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim) xk = xk.view(bsz, seqlen, self.n_local_heads, self.head_dim) xv = xv.view(bsz, seqlen, self.n_local_heads, self.head_dim) # 进行旋转位置嵌入 xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis) # 缓存这些k、v self.cache_k = self.cache_k.to(xq) self.cache_v = self.cache_v.to(xq) self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv # 从缓存中取出所有的k、v keys = self.cache_k[:bsz, : start_pos + seqlen] values = self.cache_v[:bsz, : start_pos + seqlen] # 计算Attention的值,计算公式为SoftMax(QK^T/√d + B)V xq = xq.transpose(1, 2) keys = keys.transpose(1, 2) values = values.transpose(1, 2) scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim) if mask is not None: scores = scores + mask # (bs, n_local_heads, slen, cache_len + slen) scores = F.softmax(scores.float(), dim=-1).type_as(xq) output = torch.matmul(scores, values) # (bs, n_local_heads, slen, head_dim) # 合并 output = output.transpose( 1, 2 ).contiguous().view(bsz, seqlen, -1) return self.wo(output)
关于Attention中多头注意力机制计算的详细内容可以参考Swin Transformer介绍 中的相对位置偏移 (Relative Position Bias) 详解。
然后是前馈神经网络FeedForward
class FeedForward(nn.Module): def __init__( self, dim: int, hidden_dim: int, multiple_of: int, ): super().__init__() hidden_dim = int(2 * hidden_dim / 3) hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of) self.w1 = ColumnParallelLinear( dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x ) self.w2 = RowParallelLinear( hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x ) self.w3 = ColumnParallelLinear( dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x ) def forward(self, x): return self.w2(F.silu(self.w1(x)) * self.w3(x))
前馈神经网络其实就是一个全连接层,这个就不解释了。
然后是批归一化RMSNorm
class RMSNorm(torch.nn.Module): def __init__(self, dim: int, eps: float = 1e-6): super().__init__() # 计算公式中的ξ self.eps = eps self.weight = nn.Parameter(torch.ones(dim)) def _norm(self, x): # RMSNorm公式,torch.rsqrt是张量倒数的平方根 return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps) def forward(self, x): output = self._norm(x.float()).type_as(x) return output * self.weight全国首款支持多环境开发的 IDE —— CEC-IDE 微软已将 Python 集成到 Excel,龟叔参与架构制定 中国程序员拒写赌博程序被拔 14 颗牙,全身损伤达 88% 朱雀仿宋 —— 首款开源仿宋字体 Podman Desktop 突破 50 万下载量 自动跳过开屏广告应用「李跳跳」无限期停止更新 System Initiative 宣布将其所有软件全部开源 Unity 引擎中国版“团结引擎”正式发布 Windows QQ 客户端存在远程代码执行漏洞 小米备案 mios.cn 网站域名