一、Transformer变换器模型
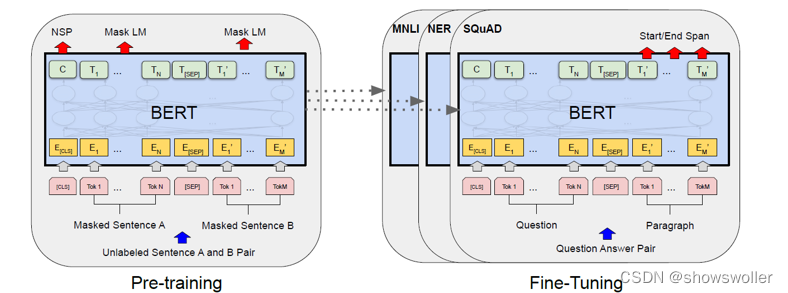
Transformer模型的编码器是由6个完全相同的层堆叠而成,每一层有两个子层 。
第一个子层是多头自注意力机制层,第二个子层是由一一个简单的、按逐个位置进行全连接的前馈神经网络。在两个子层之间通过残差网络结构进行连接,后接一一个层正则化层。可以得出,每一一个子层的输出通过公式可以表示为LayerNorm(x + Sublayer(x)),其中,Sublayer(x)函数由各个子层独立实现。为了方便各层之间的残差连接,模型中所有的子层包括嵌人层,固定输出的维度为512。Transformer 模型网络架构如图2.2所示。
Transformer模型的解码器也是由6个完全相同的层堆叠而成。除了编码器中介绍过的两个子层之外解码器还有第三个子层用于对编码器对的输出实现多头注意力机制。与编码器类似,使用残差架构连接每个子层,后接 一个层正则化层。对于解码器对的掩码自注意力子层,原论文对结构做了了改变来防止当前序列的位置信息和后续序列的位置信息混在一起。 这样的一个位置掩码操作作,再加上原有输出嵌入端对位置信息做悄难,我可以确保对位置;的预测仅依赖于已知的位置:之前的输出,而不会依赖于位置i之后的输出。
Transformer采用多头自注意力(multitheadsltentin)机制通过联合处理来自序列中不同表征子空间的不同位置的信息来来计算序列语义表征,利用不同的自注意力模块获得文本中每个词在不同语义空间下与原始词向量长度)相同的上下文语义向量在一系列任务中都表现很好


二、自监督学习
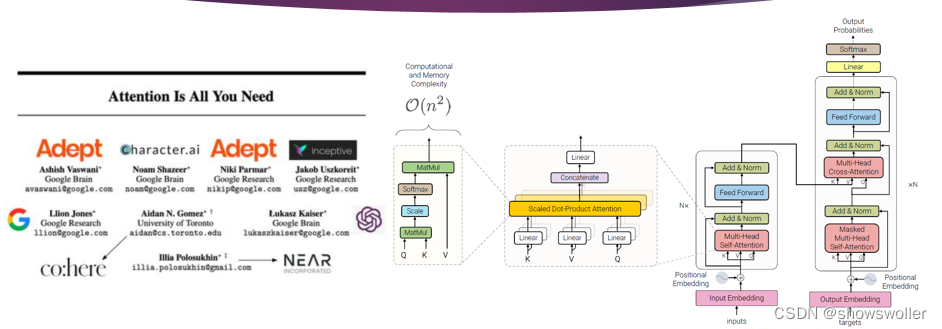
自然语言处理的表征学习有很多种形式,如卷积神经网络参数的监督(superised)训练是一种监督的表征学习形式;对自编码器和限制玻尔兹曼机参数的无监督(unsupervised)预训练是一种 无监督的表征学习形式;对深度信念网络参数先进行无监督预训练,再进行有监督微调是一种半监督(semisupervised1)的共享表征学习形式。早期的无监督预训练模型中一此对无监督任务学习到的有用特征也可能对监督学习任务有用
纯粹的监督学习是通过神经网络来表征一个句子 ,然后通过分类任务数据集去学习网络参数;而纯粹的无监督学习是通过上文预测下文来学习句子表征,利用得到的表征进行分类任务,例如,聚类降维、异常值检测、自编码器。纯监督学习和纯无监督学习都存在各自的瓶颈,为了摆脱人为监督的束缚,神经网络架构转向了数据的自监督。自监督(self-supervised)学习是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征,例如,BERT、MASS、BART等模型都是自监督学习。自监督学习是学习归纳偏差的有效方法,自监督学习最主要的目的就是学习到更丰富的语义表征,自监督的预训练在各种自然语言理解任务中已经取得了巨大的成功。
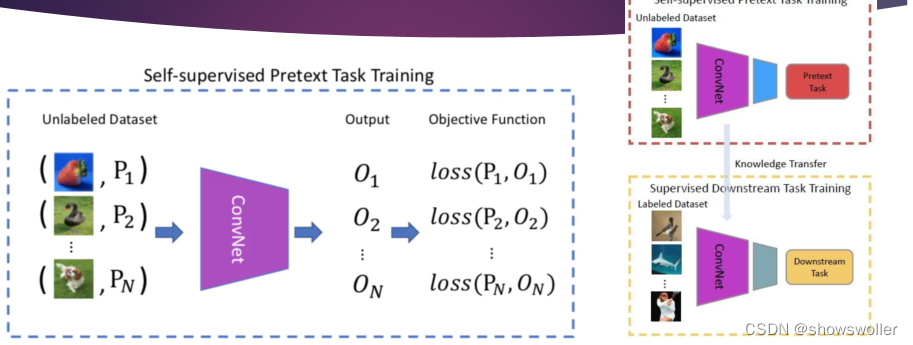

三、BERT基于变换器的双向编码器表征
深度双向变换器的预训练语言理解模型