如果刚开始入门该模型请阅读tf官方说明:Sequence-to-Sequence Models
模型应用于机器翻译的示例代码:github
如果还没有看懂tf的translate示例代码,请先理解透彻translate项目代码之后再阅读本文。
开始
开始阅读源码之前,应该对模型有基本的认识,了解模型的基本原理。我认为需要注意的几个关键点是:
1、output projection的作用
2、attention的计算公式
3、embedding的作用和原理
这里强调一下attention的计算公式:
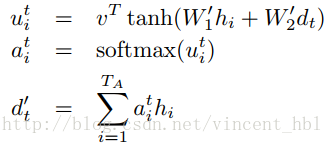
另外,模型中一个cell的计算过程其实用到了两次attention机制,一次作用与cell的输入,一次作用与cell的输出。
embedding_attention_seq2seq函数
def embedding_attention_seq2seq(encoder_inputs,
decoder_inputs,
cell,
num_encoder_symbols,
num_decoder_symbols,
embedding_size,
num_heads=1,
init_embedding=None,
output_projection=None,
feed_previous=False,
dtype=None,
scope=None,
initial_state_attention=False):
'''对encoder输入进行embedding,运行encoder部分,将encoder输出作为参数传给embedding_attention_decoer'''
with variable_scope.variable_scope(
scope or "embedding_attention_seq2seq", dtype=dtype) as scope:
dtype = scope.dtype
# 自己添加的代码,增加指定输入embedding的功能
# embedding initializer
if init_embedding:
initializer = tf.constant_initializer(init_embedding,dtype=dtype)
else:
initializer = None
# 将对输入的embedding添加到cell中
# Encoder.
encoder_cell = copy.deepcopy(cell)
encoder_cell = core_rnn_cell.EmbeddingWrapper(
encoder_cell,
embedding_classes=num_encoder_symbols,
embedding_size=embedding_size,
initializer=initializer)
# 运行encoder,得到输出和最终状态
encoder_outputs, encoder_state = core_rnn.static_rnn(
encoder_cell, encoder_inputs, dtype=dtype)
# 这里对encoder_outputs 进行reshape,变为[batch_size,input_length,cell_size]大小
# encoder_outputs将会在attention_decoder中用于attention的计算
# First calculate a concatenation of encoder outputs to put attention on.
top_states = [
array_ops.reshape(e, [-1, 1, cell.output_size]) for e in encoder_outputs
]
attention_states = array_ops.concat(top_states, 1)
# 在cell中添加outputprojection
# 这种output projection 与手动定义output projection 的差别仅仅在于网络的输出size
# 整个网络模型最后的输出结果,大小与output size相同
# Decoder.
output_size = None
if output_projection is None:
cell = core_rnn_cell.OutputProjectionWrapper(cell, num_decoder_symbols)
output_size = num_decoder_symbols
# 调用 embedding_attention_decoder
if isinstance(feed_previous, bool):
return embedding_attention_decoder(
decoder_inputs,
encoder_state,
attention_states,
cell,
num_decoder_symbols,
embedding_size,
num_heads=num_heads,
output_size=output_size,
output_projection=output_projection,
feed_previous=feed_previous,
initial_state_attention=initial_state_attention)embedding_attention_decoder函数
def embedding_attention_decoder(decoder_inputs,
initial_state,
attention_states,
cell,
num_symbols,
embedding_size,
num_heads=1,
output_size=None,
output_projection=None,
feed_previous=False,
update_embedding_for_previous=True,
dtype=None,
scope=None,
initial_state_attention=False):
'''
对decoder_input进行embedding,定义loop_function,调用attention_decoder
疑难解析:
1、output_size 与 num_symbols的差别:output_size是rnn的一个cell输出的大小,num_symbols是最终的输出大小,对应着词汇表的大小
'''
if output_size is None:
output_size = cell.output_size
if output_projection is not None:
proj_biases = ops.convert_to_tensor(output_projection[1], dtype=dtype)
proj_biases.get_shape().assert_is_compatible_with([num_symbols])
with variable_scope.variable_scope(
scope or "embedding_attention_decoder", dtype=dtype) as scope:
# 初始化decoder的embedding向量,默认tf使用glorot_uniform_initializer
embedding = variable_scope.get_variable("embedding",
[num_symbols, embedding_size])
# loop_function的作用是将上一个cell输出进行output_projection然后embedding得到当前cell的输入,仅在feed_previous情况下使用
loop_function = _extract_argmax_and_embed(
embedding, output_projection,
update_embedding_for_previous) if feed_previous else None
# 查询embedding,得到decoder_input对应的embedding
emb_inp = [
embedding_ops.embedding_lookup(embedding, i) for i in decoder_inputs
]
# 调用attention_decoder
# embedding的decoder_input、encoder的输出、encoder最终状态 作为输入
return attention_decoder(
emb_inp,
initial_state,
attention_states,
cell,
output_size=output_size,
num_heads=num_heads,
loop_function=loop_function,
initial_state_attention=initial_state_attention)
attention_decoder函数
def attention_decoder(decoder_inputs,
initial_state,
attention_states,
cell,
output_size=None,
num_heads=1,
loop_function=None,
dtype=None,
scope=None,
initial_state_attention=False):
'''
:param decoder_inputs: 经过embedding的输入
:param initial_state: encoder输入的encoder_state;encoder最终状态
:param attention_states: 就是encoder_output
:param output_size: cell输出大小,不是词汇表的大小
:param num_heads: 每个decoder hiden state, 会计算num_heads 个 加权encoder output
:param initial_state_attention:
:return:
'''
if not decoder_inputs:
raise ValueError("Must provide at least 1 input to attention decoder.")
if num_heads < 1:
raise ValueError("With less than 1 heads, use a non-attention decoder.")
if attention_states.get_shape()[2].value is None:
raise ValueError("Shape[2] of attention_states must be known: %s" %
attention_states.get_shape())
if output_size is None:
output_size = cell.output_size
with variable_scope.variable_scope(
scope or "attention_decoder", dtype=dtype) as scope:
dtype = scope.dtype
batch_size = array_ops.shape(decoder_inputs[0])[0] # Needed for reshaping.
attn_length = attention_states.get_shape()[1].value
if attn_length is None:
attn_length = array_ops.shape(attention_states)[1]
attn_size = attention_states.get_shape()[2].value
# attention 计算公式:v*tanh(w1*h_t+w2*di)
# To calculate W1 * h_t we use a 1-by-1 convolution, need to reshape before.
hidden = array_ops.reshape(attention_states,
[-1, attn_length, 1, attn_size])
hidden_features = []# 保存计算好的w1*h_t
v = []
attention_vec_size = attn_size # Size of query vectors for attention.
for a in xrange(num_heads):
k = variable_scope.get_variable("AttnW_%d" % a,
[1, 1, attn_size, attention_vec_size])
# 使用1x1卷积 计算 w1*h_t
hidden_features.append(nn_ops.conv2d(hidden, k, [1, 1, 1, 1], "SAME"))
v.append(
variable_scope.get_variable("AttnV_%d" % a, [attention_vec_size]))
state = initial_state
def attention(query):
# query 就是 di,decoder 的第i个节点的节点值
# 该函数输入decoder 节点值,得到加权求和的encoder output
"""Put attention masks on hidden using hidden_features and query."""
ds = [] # Results of attention reads will be stored here.
if nest.is_sequence(query): # If the query is a tuple, flatten it.
query_list = nest.flatten(query)
for q in query_list: # Check that ndims == 2 if specified.
ndims = q.get_shape().ndims
if ndims:
assert ndims == 2
query = array_ops.concat(query_list, 1)
for a in xrange(num_heads):
with variable_scope.variable_scope("Attention_%d" % a):
# y = w2*di+b
y = linear(query, attention_vec_size, True)
y = array_ops.reshape(y, [-1, 1, 1, attention_vec_size])
# 执行 s = v*tanh(w1*h_t + w2*di)
# Attention mask is a softmax of v^T * tanh(...).
s = math_ops.reduce_sum(v[a] * math_ops.tanh(hidden_features[a] + y),
[2, 3])
# s是每个encoder output的attention值、经过softmax计算得到权重值 a
a = nn_ops.softmax(s)
# d = sum( h_t* a_t )
# Now calculate the attention-weighted vector d.
d = math_ops.reduce_sum(
array_ops.reshape(a, [-1, attn_length, 1, 1]) * hidden, [1, 2])
# 每一个attention_head 会得到一个 d,num_heads>1时会得到一组d
ds.append(array_ops.reshape(d, [-1, attn_size]))
return ds
outputs = []
prev = None
batch_attn_size = array_ops.stack([batch_size, attn_size])
# attns 是由上一个decoder hidden state 计算出来的加权求和的encoder output
attns = [
array_ops.zeros(
batch_attn_size, dtype=dtype) for _ in xrange(num_heads)
]
for a in attns: # Ensure the second shape of attention vectors is set.
a.set_shape([None, attn_size])
# 使用encoder state 初始化第一个decoder 节点的attention
if initial_state_attention:
attns = attention(initial_state)
for i, inp in enumerate(decoder_inputs):
if i > 0:
variable_scope.get_variable_scope().reuse_variables()
# 如果设置了loop function,使用loop function 获得当前cell的 input
# If loop_function is set, we use it instead of decoder_inputs.
if loop_function is not None and prev is not None:
with variable_scope.variable_scope("loop_function", reuse=True):
inp = loop_function(prev, i)
# Merge input and previous attentions into one vector of the right size.
input_size = inp.get_shape().with_rank(2)[1]
if input_size.value is None:
raise ValueError("Could not infer input size from input: %s" % inp.name)
# 当前cell输入是 decoder input 和对应的 attention 的线性组合
# x' = w*concate(x,attens)
x = linear([inp] + attns, input_size, True)
# Run the RNN.
cell_output, state = cell(x, state)
# 用当前state 计算attention
# Run the attention mechanism.
if i == 0 and initial_state_attention:
with variable_scope.variable_scope(
variable_scope.get_variable_scope(), reuse=True):
attns = attention(state)
else:
attns = attention(state)
# cell 真正输出是cell输出和当前attention的线性组合
with variable_scope.variable_scope("AttnOutputProjection"):
output = linear([cell_output] + attns, output_size, True)
if loop_function is not None:
prev = output
outputs.append(output)
return outputs, state参考文献:
[1]Tensorflow源码解读(一):Attention Seq2Seq模型
感谢上文作者在阅读代码最艰难的困境之中点播了我,愿我也能帮助到现在的你。