1、seq2seq.py的两个重要的库函数
1) outputs, states = basic_rnn_seq2seq(encoder_inputs, decoder_inputs, cell,dtype=dtypes.float32,scope=None)
输入参数 :
encoder_inputs: 它是一个二维tensor构成的列表对象,其中每一个二维tensor代表某一时刻的输入,其尺寸为[batch_size x input_size],这里的batch_size具体指某一时刻输入的单词个数,input_size指encoder的长度;
decoder_inputs:它是一个二维tensor构成的列表对象,其中每一个二维tensor代表某一时刻的输入,其尺寸为[batch_size x output_size],这里的 batch_size具体指某一时刻输入的单词个数,output_size指decoder的长度;
cell: 它是一个rnn_cell.RNNCell或者multi-layer-RNNCell对象,其中定义了cell函数和hidden units的个数;
dtype: 初始化RNN cell状态的类型,默认为tf.float32;
scope:variablescope for the created subgraph,默认为“basic_rnn_seq2seq”;
输出参数 :
outputs: 它是一个二维tensor构成的列表对象,其中每一个二维tensor代表某一时刻输出,其尺寸为[batch_size x output_size],这里的 batch_size具体指某一时刻输入的单词个数,output_size指decoder的长度;
state: 它是一个二维tensor,表示每一个decoder cell在最后的time-step的状态,其尺寸为[batch_size x cell.state_size],这里的cell.state_size可以表示一个或者多个子cell的状态,视输入参数cell而定;
2) outputs, states = embedding_attention_seq2seq(encoder_inputs, decoder_inputs, …)
输入参数 :
encoder_inputs: 与上面的基本函数,它是一个一维tensor构成的列表对象,其中每一个一维tensor的尺寸为[batch_size],代表某一时刻的输入;
decoder_inputs: 与encoder_inputs的解释类似;
cell: 它是一个rnn_cell.RNNCell或者multi-layer-RNNCell对象,其中定义了cell函数和hidden units的个数;
num_encoder_symbols: 具体指输入词库的大小,也即输入单词one-hot表示后的向量长度;
num_decoder_symbols: 具体指输出词库的大小;
embedding_size: 词库中每一个单词“嵌套”后向量的长度;
num_heads: Number of attention heads that read from attention_states, 默认为1;
output_projection: 为None或者 (W, B) 元组对象,其中W的尺寸为[output_size x num_decoder_symbols],B的尺寸为[num_decoder_symbols],显然,解码器每一时刻的输出仅共享偏置参数B,权值参数不共享;
feed_previous: 为True时用于模型测试阶段,基于贪婪算法生成输出序列,为False时用于训练模型参数;
dtype: 初始化RNN cell状态的类型,默认为tf.float32;
scope:variablescope for the created subgraph,默认为“embedding_attention_seq2seq”
initial_state_attention: 如果是FALSE(默认),初始化attention为0;如果是TRUE, 设置初始attention的状态,也即上图中αij的取值;
输出参数 :
outputs: 它是一个二维tensor构成的列表对象,其中每一个二维tensor代表某一时刻输出,其尺寸为[batch_size x num_decoder_symbols];
state: 它是一个二维tensor,表示每一个decoder cell在最后的time-step的状态,其尺寸为[batch_size x cell.state_size],这里的cell.state_size可以表示一个或者多个子cell的状态,视输入参数cell而定;
2、sequence-to-sequence模型实现中的技巧
1)sample softmax策略
解码器RNN序列在每一时刻的输出层为softmax分类器,在对上面的目标函数求梯度时,表达式中会出现对整个target vocabulary的求和项,显然这样做的计算量是非常大的,于是大牛们想到了用target vocabulary中的一个子集,来近似对整个词库的求和,子集中word的选取采用的是均匀采样的策略,从而降低了每次梯度更新步骤的计算复杂度,在tensorflow中可以采用tf.nn.sampled_softmax_loss函数。
2)bucketing策略
bucketing策略可以用于处理不同长度的训练样例,如果我们把训练样例的输入和输出长度固定,那么在训练整个网络的时候,必然会引入很多的PAD辅助单词,而这些单词却包含了无用信息;如果不引入PAD辅助单词,每一个样例作为一个graph的话,因为每一个样例的输入尺寸和输出尺寸一般是不一样的,所以每一个样例定义出的graph也是不一样的,因此就会定义出非常多的graph,尽管这些graph有相似的sub-graph,但是在训练的时候不能够进行并行计算,势必会大大降低模型的训练效率。所以,一个折中的方法就是,可以设置若干个buckets,每个bucket指定一个输入和输出长度,比如教程给的例子buckets = [(5, 10), (10, 15), (20, 25), (40, 50)],这样的话,经过bucketing策略处理后,会把所有的训练样例分成4份,其中每一份的输入序列和输出序列的长度分别相同。为了更好地理解源代码中bucketing的使用,我们这里补充讲述一下。TensorFlow是先定义出Graph,模型的训练过程就是对Graph中参数进行更新。对于本例中的Graph而言,Graph中encoder部分的长度为40,decoder部分的长度为50,在每次采用梯度下降法更新模型参数时,会随机地从4个buckets中选择一个,并从中随机选取batch个训练样例,此时相当于对当前Graph中的参数进行优化,但考虑到4个graph之间存在“weight share”,因此每个batch中样例的长度不一样也是可以的。
3、Github源代码解析
整个工程主要使用了四个源文件,seq2seq.py文件是一个用于创建sequence-to-sequence模型的库,data_utils.py中包含了对原始数据进行预处理的一些操作,seq2seq_model.py用于定义machine translation模型,translate.py用于训练和测试所定义的翻译模型。因为源代码较长,下面仅针对每个.py文件,对理解起来可能有困难的代码块进行解析。
1)seq2seq.py文件
这个文件中比较重要的两个库函数basic_rnn_seq2seq和embedding_attention_seq2seq已经在上一部分作了介绍,这里主要介绍其它的几个功能函数。
(1)sequence_loss_by_example(logits, targets, weights)
这个函数用于计算所有examples的加权交叉熵损失,logits参数是一个2D Tensor构成的列表对象,每一个2D Tensor的尺寸为[batch_size x num_decoder_symbols],函数的返回值是一个1D float类型的Tensor,尺寸为batch_size,其中的每一个元素代表当前输入序列example的交叉熵。另外,还有一个与之类似的函数sequence_loss,它对sequence_loss_by_example函数返回的结果进行了一个tf.reduce_sum运算,因此返回的是一个标称型float Tensor。函数seq2seq有两个返回值,因为tf.nn.seq2seq.embedding_attention_seq2seq函数有两个返回值
(2)model_with_buckets(encoder_inputs,decoder_inputs,targets,weights,buckets,seq2seq)
这个函数创建了一个支持bucketing策略的sequence-to-sequence模型,它仍然属于Graph的定义阶段。具体来说,这段程序定义了length(buckets)个graph,每个graph的输入为总模型的输入“占位符”的一部分,但这些graphs共享模型参数,函数的返回值outputs和losses均为列表对象,尺寸为[length(buckets)],其中每一个元素为当前graph的bucket_outputs和bucket_loss。
2)data_utils.py文件
(1)create_vocabulary(vocabulary_path, data_path, max_vocabulary_size)
这个函数用于根据输入文件创建词库,在这里data_path参数表示输入源文件的路径,vocabulary_path表示输出文件的路径,vocabulary_path文件中每一行代表一个单词,且按照其在data_path中的出现频数从大到小排列,比如第1行为r”_EOS”,第2行为r”_UNK”,第3行为r’I’,第4行为r”have”,第5行为r’dream’,……
(2)data_to_token_ids(data_path, target_path, vocabulary_path)
这个函数用于把字符串为元素的数据文件转换为以int索引为元素的文件,在这里data_path表示输入源数据文件的路径,target_path表示输出索引数据文件的路径,vocabulary_path表示词库文件的路径。整个函数把数据文件中的每一行转换为在词库文件中的索引值,两单词的索引值之间用空格隔开,比如返回值文件的第一行为’1 123 235’,第二行为‘3 1 234 554 879 355’,……
3)seq2seq_model.py文件
(1)输入变量的定义
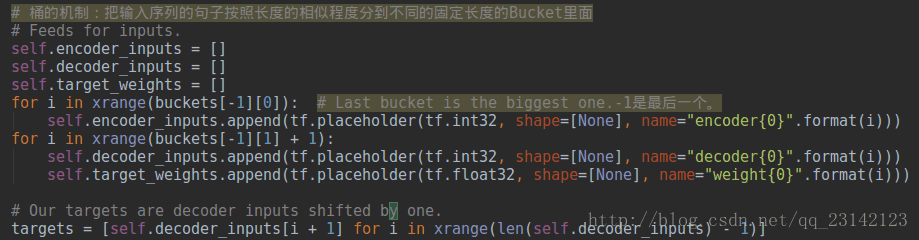
与前面的几个样例不同,这里输入数据采用的是最常见的“占位符”格式,以self.encoder_inputs为例,这个列表对象中的每一个元素表示一个占位符,其名字分别为encoder0, encoder1,…,encoder39,encoder{i}的几何意义是编码器在时刻i的输入。这里需要注意的是,在训练阶段执行sess.run()函数时会再次用到这些变量名字。另外,跟language model类似,targets变量是decoder inputs平移一个单位的结果,读者可以结合当前模型的损失函数进行理解。
(2)输入信息的forward propagation
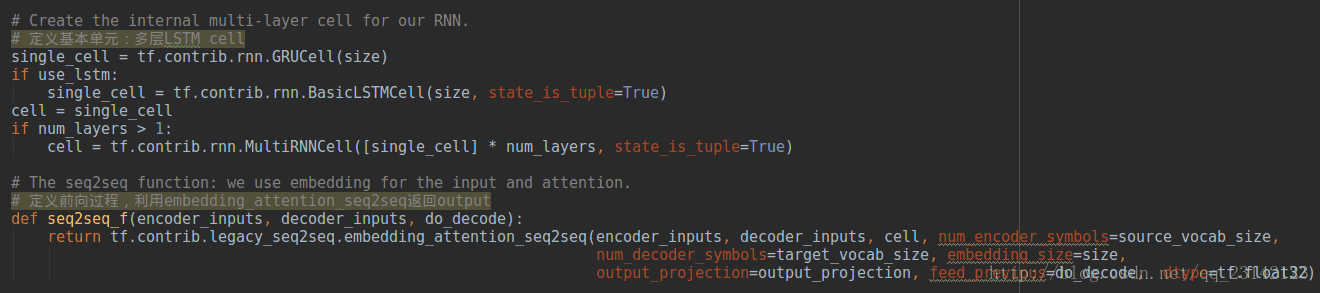
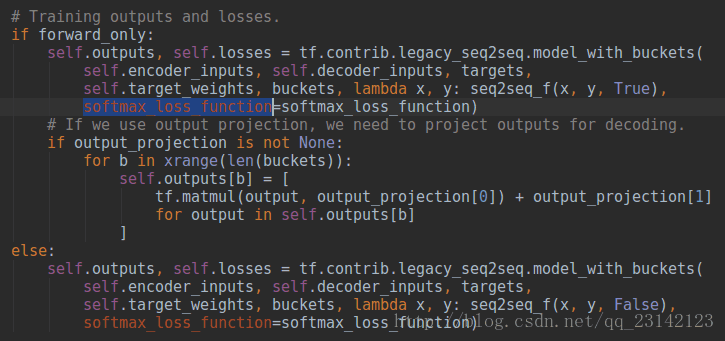
从代码中可以看到,输入信息的forward popagation分成了两种情况,这是因为整个sequence to sequence模型在训练阶段和测试阶段信息的流向是不一样的,这一点可以从seq2seqf函数的do_decode参数值体现出来,而do_decoder取值对应的就是tf.nn.seq2seq.embedding_attention_seq2seq函数中的feed_previous参数,forward_only为True也即feed_previous参数为True时进行模型测试,为False时进行模型训练。这里还应用到了一个很重要的函数tf.nn.seq2seq.model_with_buckets,我们在seq2seq文件中对其进行讲解。
(3)误差信息的backward propagation
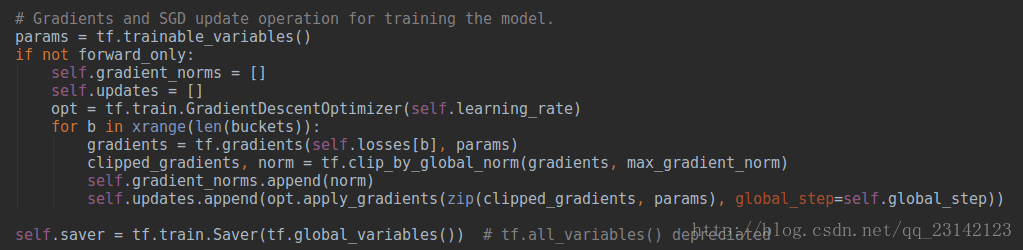
返回所有bucket子graph的梯度和SGD更新操作,这些子graph共享输入占位符变量encoder_inputs,区别在于,对于每一个bucket子图,其输入为该子图对应的长度。
参考资料:
https://www.2cto.com/kf/201612/575911.html
https://www.tensorflow.org/versions/r0.12/tutorials/seq2seq/index.html