英法机器翻译Tensorflow代码实现
1、Encoder-Decoder
在网上大家能够找到很多关于,sequence to sequence模型。简单的来说它就是一个编码器和解码器,用循环神经网络RNN去实现。
在编码端,用RNN对句子进行中间语义表示,得到c后,根据c的表示去进行解码。在机器翻译当中,就是将源端的语言,进行中间表示,然后再解码成目标端的语言。

但是编码端,通常是将源语言编码成一个固定长度的向量。这种做法,在改善效果来说比较差,而且对于神经网络来说,难以处理长距离依赖。于是提出了Attention机制。
2、ATTENTION 机制
参考下面这篇文章

attention机制的思想,就是在翻译一个词的时候,我的注意力应该集中于目标端的哪一个词或者哪几个词。而不是只用编码端循环神经网络最后一个状态作为语义表示。一种直观的理解,可以将编码端所有的,隐状态的输出进行平均得到中间表示。但是这样并没有应用到解码端的信息。
我们以下图,t1为例,来进行说明。
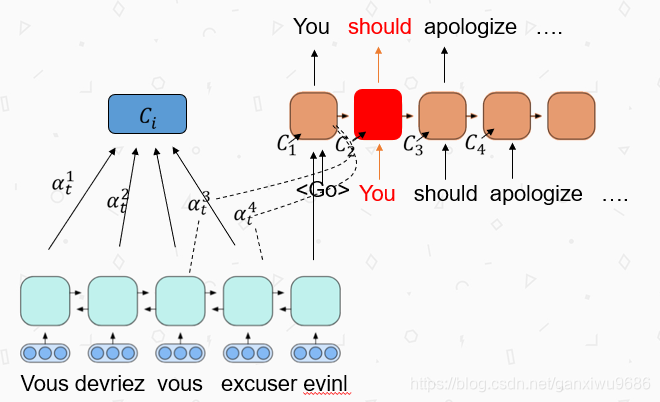
在对You进行下一个词的预测时候,我们需要去计算C2,即对编码端的注意力表示。
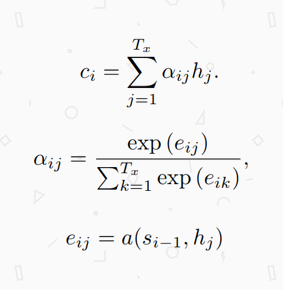
C是对编码端隐藏层输出的一个加权求和,其中阿尔法表示0~1之间的一个得分(经过softmax之后)。
接受当前时刻的前一时刻的隐藏成的状态
(Decoder)和编码层的隐藏状态输出
。
a as a feedforward neural network which is jointly trained with all the other components of the proposed system
在得到attention,c2之后,我们利用下面公式就可以去解码预测下一个单词出现的概率。
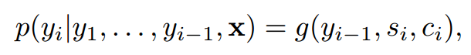
此后又提出了一篇新的论文,他在该注意力机制的基础上进行了改进,分别介绍了全局注意力和局部注意力。
Effective Approaches to Attention-based Neural Machine Translation 2015EMNLP
3、改进的Attention
下图是B提出的(上文所述)
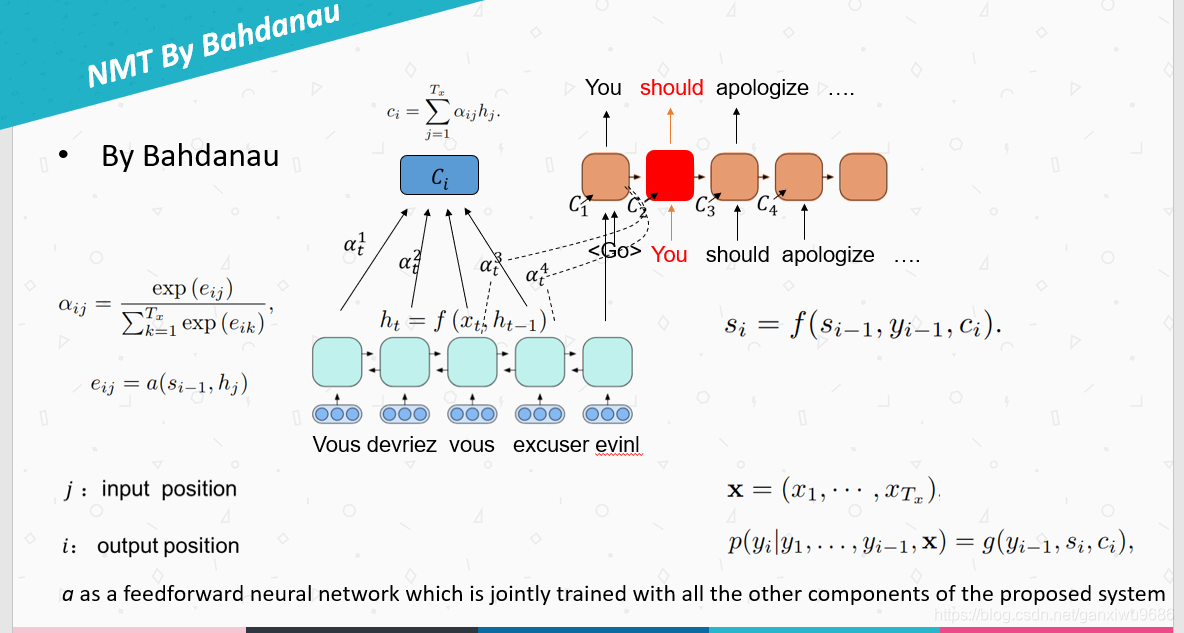
如下图所示:主要有三个不同点,第1个不同点,编码器改成了单向循环神经网络。第2个不同点,attention的计算方式不一样。第3个不同的在解码端循环神经网络的基础上,增加了一层非线性变换,attention不直接作用于循环神经网络。

- attention计算方式
attention的计算方式变为当前时刻解码端的隐层状态,和编码端的隐层状态进行计算。计算方式有如下三种,由之前的加法计算变成了乘法计算。而且少了a这个函数,即前馈神经网。运算速度大大的提高。

- 非线性变换层
得到的attention的结果C,不作用于解码端的循环神经网,而是作用于其上一层的神经元,并且再结合RNN的隐层状态,通过参数Wc和一个非线性变换得到新的状态。然后以此状态去softmax,得到下一个词的概率。
随后还提出了局部attention。即,不是对编码端所有的隐藏状态进行计算,而是固定一个窗口,这个位置,由训练获得。具体可以参看论文。
根据以上的模型,我们在英法的数据集上进行实验。具体可以看github,ReadMe有详细介绍。
下一次会介绍Transformer模型,该模型摒弃了RNN和CNN,完全只有attention,效果也很不错。