目录
1 CNN(卷积神经网络)
https://www.zhihu.com/question/52668301
卷积层->非线性层->池化层->完全连接层
经典结构:
输入→卷积→ReLU→卷积→ReLU→池化→ReLU→卷积→ReLU→池化→全连接
1.1 卷积层
第一层的输入是原始图像,而第二卷积层的输入正是第一层输出的激活映射。也就是说,这一层的输入大体描绘了低级特征在原始图片中的位置。
在此基础上再采用一组过滤器(让它通过第 2个卷积层),输出将是表示了更高级的特征的激活映射。这类特征可以是半圆(曲线和直线的组合)或四边形(几条直线的组合)。随着进入网络越深和经过更多卷积层后,你将得到更为复杂特征的激活映射。
1.2 完全连接层
简单地说,这一层处理输入内容(该输入可能是卷积层、ReLU 层或是池化层的输出)后会输出一个 N 维向量,N 是该程序必须选择的分类数量。
如果有 10 个数字,N 就等于 10。这个 N 维向量中的每一数字都代表某一特定类别的概率。
完全连接层观察上一层的输出(其表示了更高级特征的激活映射)并确定这些特征与哪一分类最为吻合。例如,如果该程序预测某一图像的内容为狗,那么激活映射中的高数值便会代表一些爪子或四条腿之类的高级特征。
1.3 卷积的应用
https://blog.csdn.net/zhu_hongji/article/details/81562746
用一个模板和一幅图像进行卷积,对于图像上的一个点,让模板的原点和该点重合,然后模板上的点和图像上对应的点相乘,然后各点的积相加,就得到了该点的卷积值。 对图像上的每个点都这样处理。
由于大多数模板都是对称的,所以模板不旋转。
卷积是一种积分运算,用来求两个曲线重叠区域面积。可以看作加权求和,可以用来消除噪声、特征增强。
卷积:是图像处理中一个操作,是kernel在图像的每个像素上的操作。
Kernel:本质上一个固定大小的矩阵数组,其中心点称为锚点(anchor point)
2 PointNet
2.1 网络结构

2.2 局限性
缺失局部特征
对每一个点映射到高维空间,再通过max结合。由于其网络直接暴力地将所有的点最大池化为了一个全局特征,因此局部点与点之间的联系并没有被网络学习到。
=>PointCNN 卷积神经网络能够利用网格中密集表示的数据(例如图像)的空间局部相关性。
3 PointCNN:Convolution On X-Transformed Points
PointCNN:x变换点上的卷积
PointCNN:Convolution On X-Transformed Points
3.1 Abstract
提出问题:
- PointNet的方法会造成局部特征的丢失。
- 点云是不规则且无序的,因此直接将核与与点相关联的特征进行卷积将导致形状信息的丢失和点到点排序的变化。
解决问题:
我们建议从输入点学习一个X变换,以同时(simultaneously)促进两个原因:
- 第一个是与点相关联的输入特征的权重
- 第二个是将点排列成潜在的和潜在的规范顺序。
3.2 Introduction
首先介绍了由于点云没有规范的数据格式,导致其不适合卷积。
3.3 Related Work
CNN方法很有效的利用了图像中的空间局部相关性。
Feature Learning from Regular Domains.常规领域的特征学习
将CNN扩展到了三维体素=>由于输入核和卷积核都是高维的,计算量和存储量都急剧膨胀。
基于八叉树、Kd-Tree 和Hash的方法已经被提出来通过跳过空空间中的卷积来节省计算。
与这些方法相比,PointCNN在输入表示和卷积核上都是稀疏的。
对于稀疏的理解:稀疏性可以被简单地解释如下。如果当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制。
Feature Learning from Irregular Domains不规则域的特征学习
PointNet和Deep set提出通过在输入上使用对称函数来实现输入顺序不变性。
PointNet++和SO-Net分层应用PointNet,以便更好地捕获局部结构。
为了改进类似PointNet的方法,提出了核相关和图池( Kernel correlation and graph pooling)
RNN在[18]中用于处理通过汇集有序点云切片而聚集的要素。
[50]提出在点和特征空间中利用邻域结构。
虽然这些基于对称池的方法,以及[10,58,36]中的方法,在实现顺序不变性方面有保证,但它们的代价是丢弃信息。
[43,3,44]建议首先将特征“内插”或“投影”到预定义的规则域中,在这些域中可以应用典型的CNNs。
在这些方法中,与每个点相关联的核被单独参数化,而我们的方法中的X变换是从每个邻域中学习的,因此可能更适合于局部结构。
除了作为点云之外,不规则区域中的稀疏数据可以表示为图形或网格,并且已经提出了一些用于从这种表示进行特征学习的工作[31,55,30]。
Invariance vs. Equivariance.不变性与等方差
已经提出了一系列旨在实现等方差的开创性工作,以解决在实现不变性时汇集的信息丢失问题[16,40]。
在PointCNN中,X变换被假定为既用于加权又用于置换,因此被建模为通用矩阵。
3.4 PointCNN
首先,我们在PointCNN中引入了分层卷积,类似于图像CNN,然后,我们详细解释了核心的X-Conv算子,最后,给出了面向各种任务的PointCNN体系结构。
3.4.1 分层卷积

对图2的解释:
上半部分: 在常规网格中,卷积递归地应用于局部网格面片,这通常会降低网格分辨率(4×4→3×3→2×2),同时增加通道数(通过点厚度可视化)。
下半部分: 类似地,在点云中,X-Conv被递归地应用于将来自邻域的信息“投影”或“聚集”成更少的代表点(9→5 →2),但每一个都有更丰富的信息。
基于网格的CNNs的输入:
1、输入特征 F 1 F_1 F1 ( R 1 × R 1 × C 1 R_1\times R_1\times C_1 R1×R1×C1)
R 1 R_1 R1:空间分辨率 C 1 C_1 C1:特征通道深度
2、核 K K K( K × K × C 1 × C 2 K\times K \times C_1\times C_2 K×K×C1×C2)与来自 F 1 F_1 F1的batch( K × K × C 1 K\times K \times C_1 K×K×C1)卷积生成特征图 F 2 F_2 F2( R 2 × R 2 × C 2 R_2\times R_2\times C_2 R2×R2×C2)
在图2中, R 1 = 4 , K = 2 , R 2 = 3 R_1=4,K=2,R_2=3 R1=4,K=2,R2=3
与 F 1 F_1 F1相比, F 2 F_2 F2通常具有较低的分辨率( R 2 < R 1 R_2< R_1 R2<R1)和较深的通道( C 2 > C 1 C_2>C_1 C2>C1) 并且编码更高级别的信息。
这个过程被递归地应用,产生具有降低的空间分辨率的特征地图(4×4→3×3→2×2),但通道更深(通过图2上部越来越粗的点可见)。
PointCNN的输入:
表示每一个点 p 1 , i p_{1,i} p1,i都有一个特征 f 1 , i f_{1,i} f1,i,且 { f 1 , i : f 1 , i ∈ R C 1 } \left\{f_{1, i}: f_{1, i} \in \mathbb{R}^{C_{1}}\right\} { f1,i:f1,i∈RC1}
我们希望在 F 1 F_1 F1上应用X-Conv,以获得更高级别的表示:
F 2 = { ( p 2 , i , f 2 , i ) : f 2 , i ∈ R C 2 , i = 1 , 2 , … , N 2 } \mathbb{F}_{2}=\left\{\left(p_{2, i}, f_{2, i}\right): f_{2, i} \in \mathbb{R}^{C_{2}}, i=1,2, \ldots, N_{2}\right\} F2={
(p2,i,f2,i):f2,i∈RC2,i=1,2,…,N2}
F2比F1具有更小的空间分辨率和更深的特征通道, N 2 < N 1 , C 2 > C 1 N_2<N_1,C_2>C_1 N2<N1,C2>C1
p 2 , i p_{2,i} p2,i 是 p 1 , i p_{1,i} p1,i的一组代表点
当递归的使用X变换将 F 1 F_1 F1转向 F 2 F_2 F2时,具有特征的输入点被"投影"或“聚集”成更少的点(9→5→2),但是每个都具有越来越丰富的特征(在图2中通过越来越粗的点来可视化较低)。
具有代表性的点p2i在分类任务中由随机下采样生成。
3.4.2 X卷积算子
为了利用空间局部相关性,类似于基于网格的中枢神经系统中的卷积,X-Conv在局部区域运行。
由于输出要素应该与代表点 { p 2 , i } \left\{p_{2, i}\right\} { p2,i}相关联,因此X-Conv将它们在 { p 1 , i } \left\{p_{1, i}\right\} { p1,i}中的邻域点以及相关联的要素作为输入进行卷积。
令 p p p为 p 2 , i p_{2, i} p2,i中的代表点, f f f为 p p p的特征, N N N为在 p 1 , i p_{1, i} p1,i中 p p p的 K K K个邻近点。
因此,p的X-Conv输入为: S = { ( p i , f i ) : p i ∈ N } \mathbb{S}=\left\{\left(p_{i}, f_{i}\right): p_{i} \in \mathbb{N}\right\} S={ (pi,fi):pi∈N}
S \mathbb{S} S可以被转换成一个 K × D i m K \times Dim K×Dim的矩阵: P = ( p 1 , p 2 , … , p K ) T \mathbf{P}=\left(p_{1}, p_{2}, \ldots, p_{K}\right)^{T} P=(p1,p2,…,pK)T,和一个 K × C 1 K×C_1 K×C1大小的矩阵: F = ( f 1 , f 2 , … , f K ) T \mathbf{F}=\left(f_{1}, f_{2}, \ldots, f_{K}\right)^{T} F=(f1,f2,…,fK)T
其中 K K K表示可被训练的卷积核
有了这些输入,我们想计算特征 F p F_p Fp,它是输入特征到代表点 p p p的“投影”或“聚合”。
X_conv算法表达式:
F p = X − Conv ( K , p , P , F ) = Conv ( K , M L P ( P − p ) × [ M L P δ ( P − p ) , F ] ) \mathbf{F}_{p}=\mathcal{X}-\operatorname{Conv}(\mathbf{K}, p, \mathbf{P}, \mathbf{F})=\operatorname{Conv}\left(\mathbf{K}, M L P(\mathbf{P}-p) \times\left[M L P_{\delta}(\mathbf{P}-p), \mathbf{F}\right]\right) Fp=X−Conv(K,p,P,F)=Conv(K,MLP(P−p)×[MLPδ(P−p),F])
M L P δ ( ⋅ ) M L P_{\delta}(\cdot) MLPδ(⋅)表示在每个点上单独应用多层感知机(与PointNet算法相同)
X_Conv是可微的,所以可以通过反向传播插入神经网络进行训练。

像基于PointNet的方法一样,将坐标提升到特征的方法是通过逐点 M L P δ ( ⋅ ) M L P_{\delta}(\cdot) MLPδ(⋅)实现的。但是,提升坐标到特征的方法不是通过对称函数实现的 => 取而代之的是,与相关联的特征一起,它们被所有邻域共同学习的X变换加权和置换。
得到的X取决于点的顺序,这正是所期望的,因为X应该通过输入的点来变换 F ∗ F_* F∗,因此必须知道具体的输入顺序。
对于没有任何附加特征的输入点云,即f为空,第一个X-Conv图层仅使用 F δ F_{\delta} Fδ。PointCNN因此可以以健壮统一的方式处理有或没有附加特征的点云。
3.4.3 PointCNN架构

其中 N N N和 C C C表示输出代表点数和特征维数, K K K是每个代表点的相邻点数,D是X-Conv膨胀率。
a图:
两个X-Conv层的简单PointCNN,这两个层将输入点(有或没有特征)逐渐转换成更少的表示点,但是每个表示点具有更丰富的特征。在第二个X-Conv层之后,只剩下一个代表点,它聚合了来自前一层的所有点的信息。在PointCNN中,我们可以把每个代表点的感受野大致定义为 K / N K/N K/N的比值,其中 K K K是相邻的点数, N N N是上一层的点数。
有了这个定义,最后一个点“看到”了前一层的所有点,因此具有1.0的接受域——它具有整个形状的全局视图,并且它的特征对于形状的语义理解来说是信息丰富的。我们可以在最后一个X-Conv层输出之上添加完全连接的层,然后是一个损失,用于训练网络。
// 未完全完成
3.5 分类实验
3.5.1 数据集
ModelNet40、ScanNet、TU-Berlin、Quick Draw、MNIST、CIFAR10
3.5.2 结果
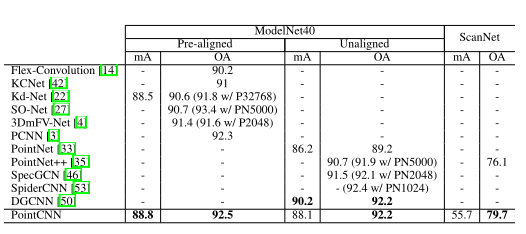
mA:平均每类准确度
oA:总准确度
基于1024个点进行实验
4 代码实现
具体代码实现:https://github.com/Kandy990125/PointClouds_cls/tree/main/PointCNN_Pytorch