TextCraft: Zero-Shot Generation of High-Fidelity and Diverse Shapes from Text
论文原文: https://arxiv.org/abs/2211.01427
论文的研究动机
- DALL2已经在文本控制的图像生成上取得很好的效果,但是基于文本控制的3d点云生成的研究还不太成熟,于是本文作者想要研究这个方向内容;
- 但是这时候作者发现了新的问题:没有成熟的数据集;
- 因此作者想要利用clip的预训练模型来解决这个问题。
论文的具体思路
其实这个思路不困难,就是整理本身有的东西,本身有的东西包括:
- 3d点云数据和视图对
- 利用视图控制生成3d点云的网络
现在想要获得:
- 利用文字控制生成3d点云的网络
想到clip:
- 提供了一个提取出文字和图片的共用特征
所以只需要利用这个共用特征控制生成3d点云,就可以在训练的阶段用“视图和3d模型对”训练,在预测阶段用文字输入生成3d点云。
论文网络结构
总体网络图
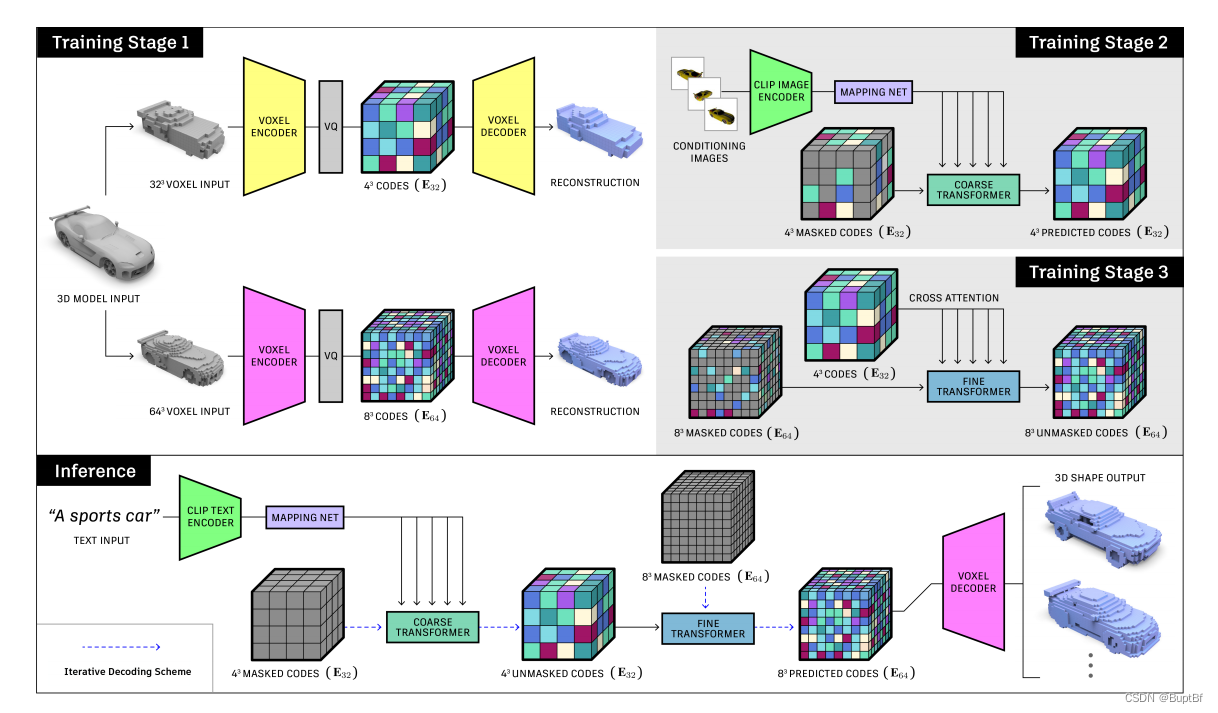
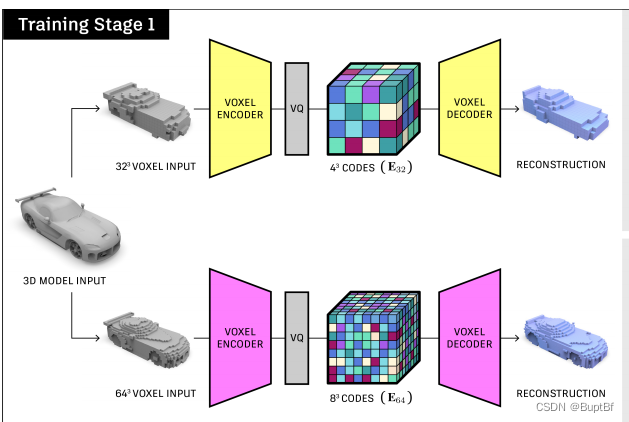
第一部分训练,这部分主要是找出来两个东西:隐层表达、读入隐层表达输出3d模型的网络,这样在之后,只需要获得这个隐层表达就可以获得相对应的3d点云。
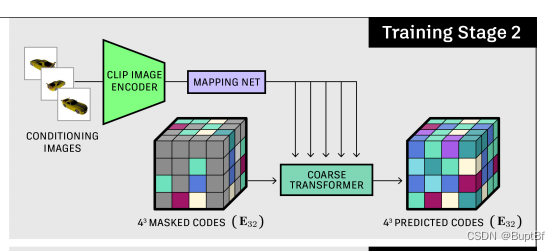
第二部分训练,主要是用“视图和3d点云对”训练由视图生成隐层特征,
第三部分,增强隐层特征,感觉这里就是丰富一下隐层特征,增加生成的多样性,生成网络类型的东西,一般在低维度生成大方向,高维度则是小细节,这里应该就是在大方向确定的情况下丰富小细节。
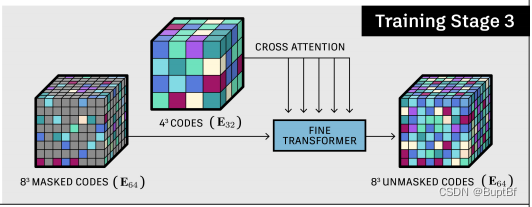
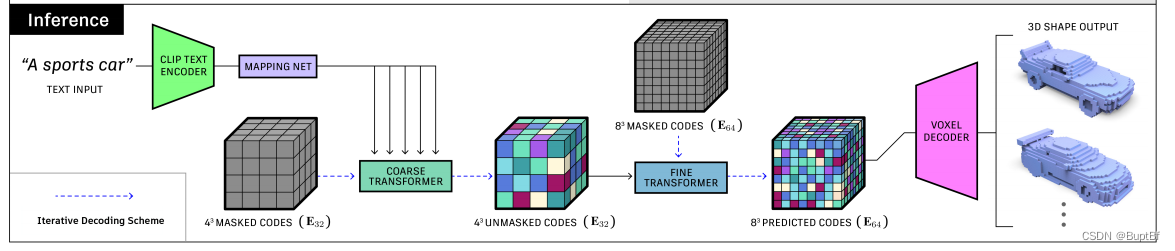
接下来是预测阶段,主要是把控制信息换成由文字产生的共有特征。