Bring Your Data!Self- supervised Evolution of Large Language Models
Introduction
这篇论文提出了一种自监督的评估方式来衡量大型语言模型的能力和局限性。常规的基于数据集的评估方式存在一些缺点:
- 需要不断新建数据集。
- 存在数据集和模型训练数据交叉的问题,影响评估结果。
- 难以评估模型在实际部署中的表现。为了弥补这些缺点,论文提出了自监督评估方法。
主要思想是:对输入文本做一些简单的转换(如添加否定词、颠倒词序等),然后比较原始文本和转换文本模型的输出(或概率分布),通过模型对这些转换的不变性或敏感度来评估它的能力。
Method
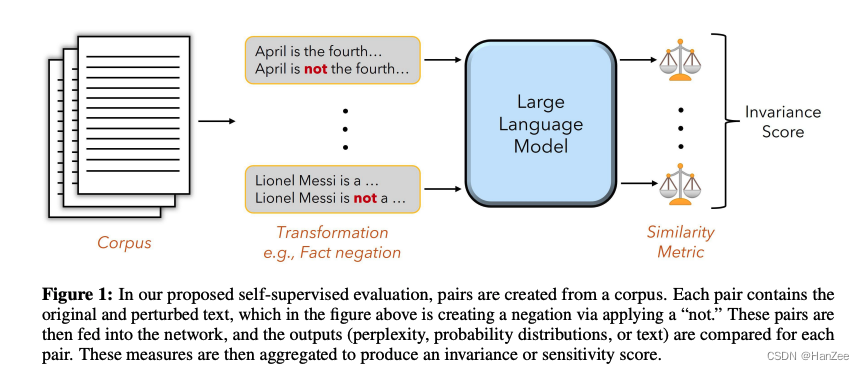
自监督评估的主要思想是:
基于输入文本做某种简单的转换,形成一对原始文本和变换后的文本,将这对文本送入模型,分析模型对这种转换的不变性或敏感度,将多个这样的文本对的数据聚合,形成一个总体上的不变性或敏感度分数。
具体过程:
- 对数据集(如维基百科)构建输入文本x和变换后的文本x’对。
- 将这对文本送入模型f,获取模型输出(可以是概率分布、困惑值、文本等)。
- 根据输出f(x)和f(x’)使用一个相似度度量M量化它们的相似性。
- 将相似度度量在整个数据集上聚合,使用聚合函数A计算最终的不变性/敏感度分数。
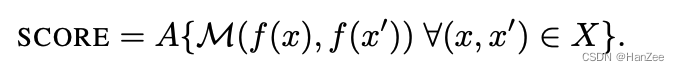
论文提出了以下变换来评估模型:
-
添加否定词,测量模型对否定句子模型分布的变化,来反应模型的世界知识。
-
添加有毒引发词,分析模型生成的文本来测量模型对有毒文本的敏感度。
-
替换一些上下文句子,测量模型对最后一句话的概率分布变化,来反应模型对长距离上下文的敏感度。
-
颠倒词序,测量模型对概率分布的变化来反应模型对词序的敏感度。
-
将输入文本拆分后重新组合,测量模型对这样的分词变化的鲁棒性。
参考
https://arxiv.org/pdf/2306.13651.pdf