摘要:本文整理自 Tech Lead of Shopee Flink Runtime Team 范瑞,在 Flink Forward Asia 2022 核心技术的分享。本篇内容主要分为五个部分:
- Checkpoint 存在的问题
- Unaligned Checkpoint 原理
- 大幅提升 UC 收益
- 大幅降低 UC 风险
- UC 在 Shopee 的生产实践和未来规划

一、Checkpoint 存在的问题
1.1 数据库的 Snapshot 和恢复机制
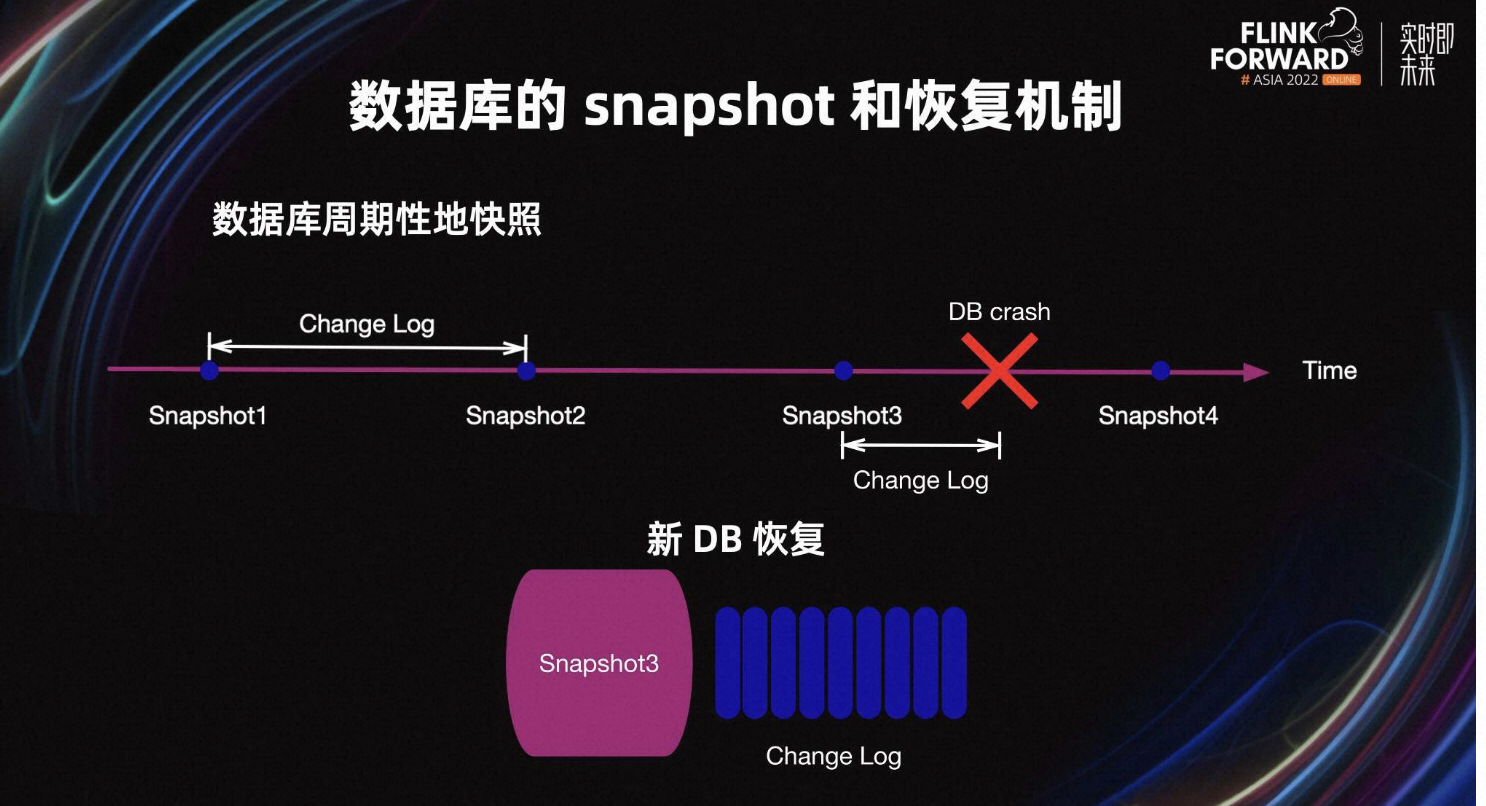
首先看一下数据库的 Snapshot 和恢复机制。数据库周期性地快照,每一次 Snapshot 是一个全量快照,同时要持续地写 Change Log 或 WAL。当数据库 crash 后,新的数据库实例会从 Snapshot3 以及最新的 Change Log 恢复。
1.2 Flink Checkpoint 和恢复
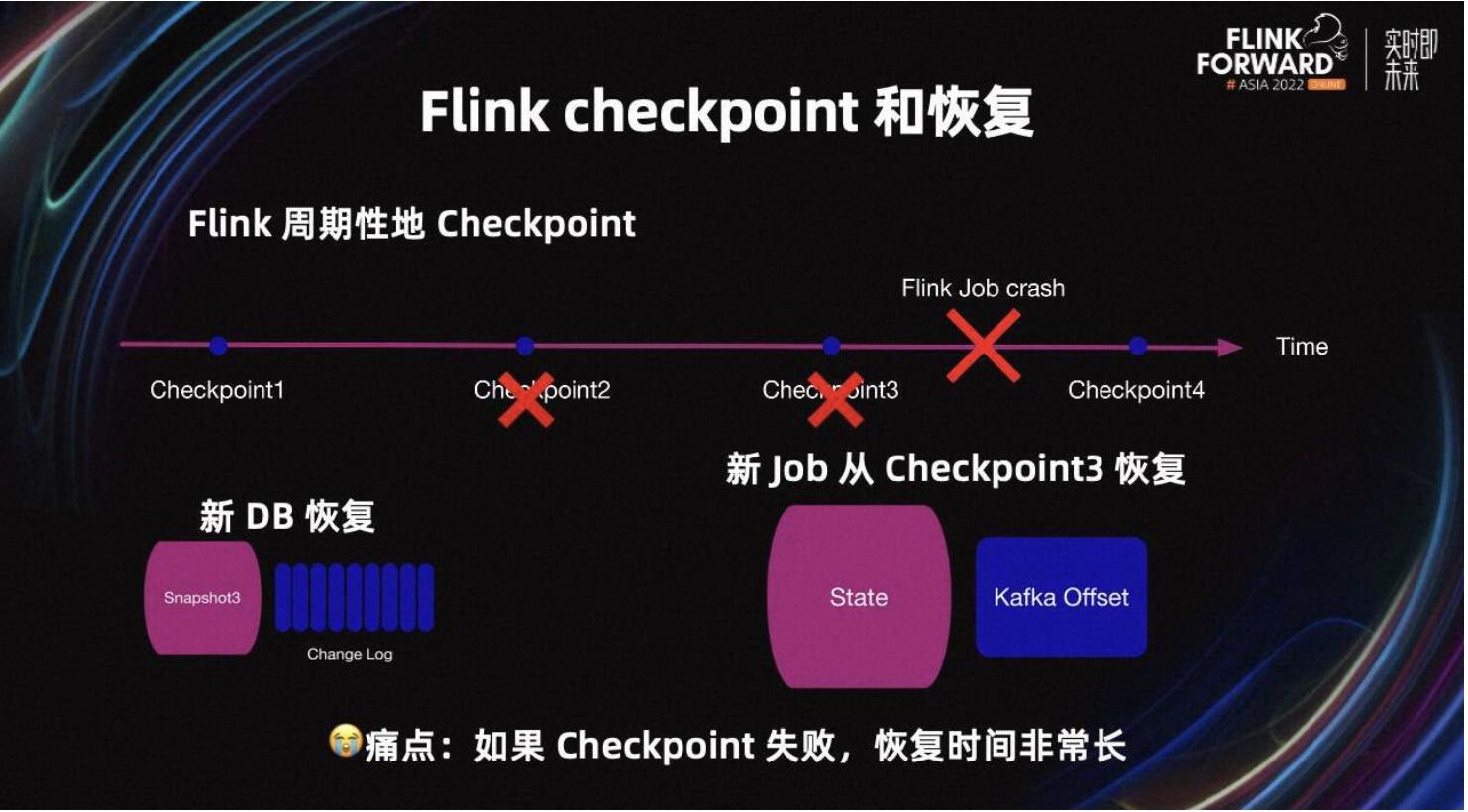
Flink Checkpoint 与数据库的 Snapshot 类似,Flink 周期性的 Checkpoint。当 Flink Job crash 后,新的 Job 会从 Checkpoint3 恢复。Checkpoint 的 State 与数据库的 Snapshot 类似。Checkpoint 的 Kafka Offset 与数据库的 Change Log 类似。Flink 任务会从 Checkpoint3 的 State 恢复,且从 Checkpoint3 的 Kafka Offset 开始消费。
从技术上来讲,如果 Checkpoint2 和 Checkpoint3 都失败,Flink 任务需要从 Checkpoint1 恢复,恢复时间可能会非常长。
1.3 Checkpoint 失败对业务的影响

从业务上来讲,Checkpoint 失败可能有较多的影响。
- Flink 恢复时间长,会导致服务可用率降低。
- 非幂等或非事务场景,导致大量业务数据重复。
- Flink 任务如果持续反压严重,可能会进入死循环,永远追不上 lag。因为反压严重会导致 Flink Checkpoint 失败,Job 不能无限容忍 Checkpoint 失败,所以 Checkpoint 连续失败会导致 Job 失败。Job 失败后任务又会从很久之前的 Checkpoint 恢复开始追 lag,追 lag 时反压又很严重,Checkpoint 又会失败。从而进入死循环,任务永远追不上 Lag。
- 在一些大流量场景中,SSD 成本很高,所以 Kafka 只会保留最近三小时的数据。如果 Checkpoint 持续三小时内失败,任务一旦重启,数据将无法恢复。
1.4 反压严重时 Checkpoint 失败
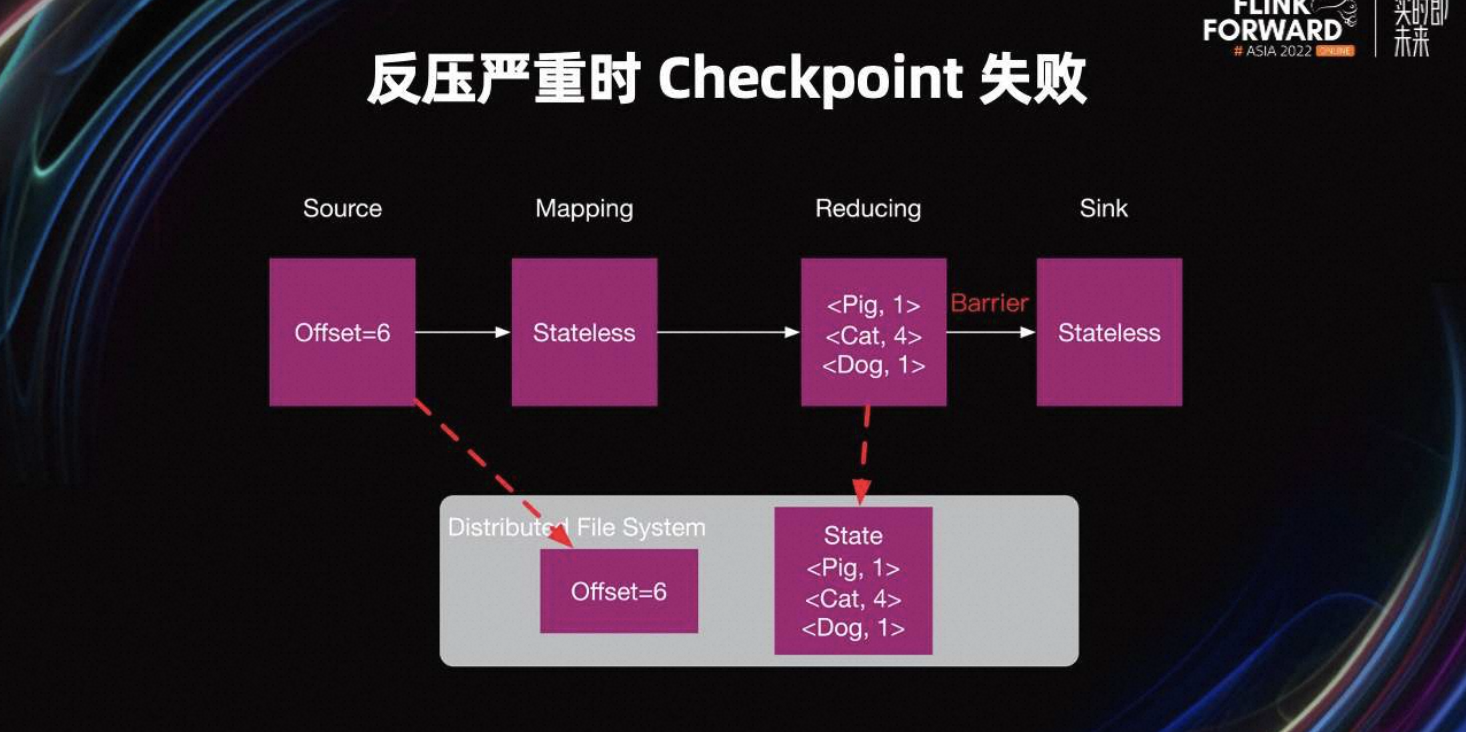
为什么 Checkpoint 会失败呢?Checkpoint Barrier 从 Source 生成,并且 Barrier 从 Source 发送到 Sink Task。当 Barrier 到达 Task 时,该 Task 开始 Checkpoint。当这个 Job 的所有 Task 完成 Checkpoint 时,这个 Job 的 Checkpoint 就完成了。
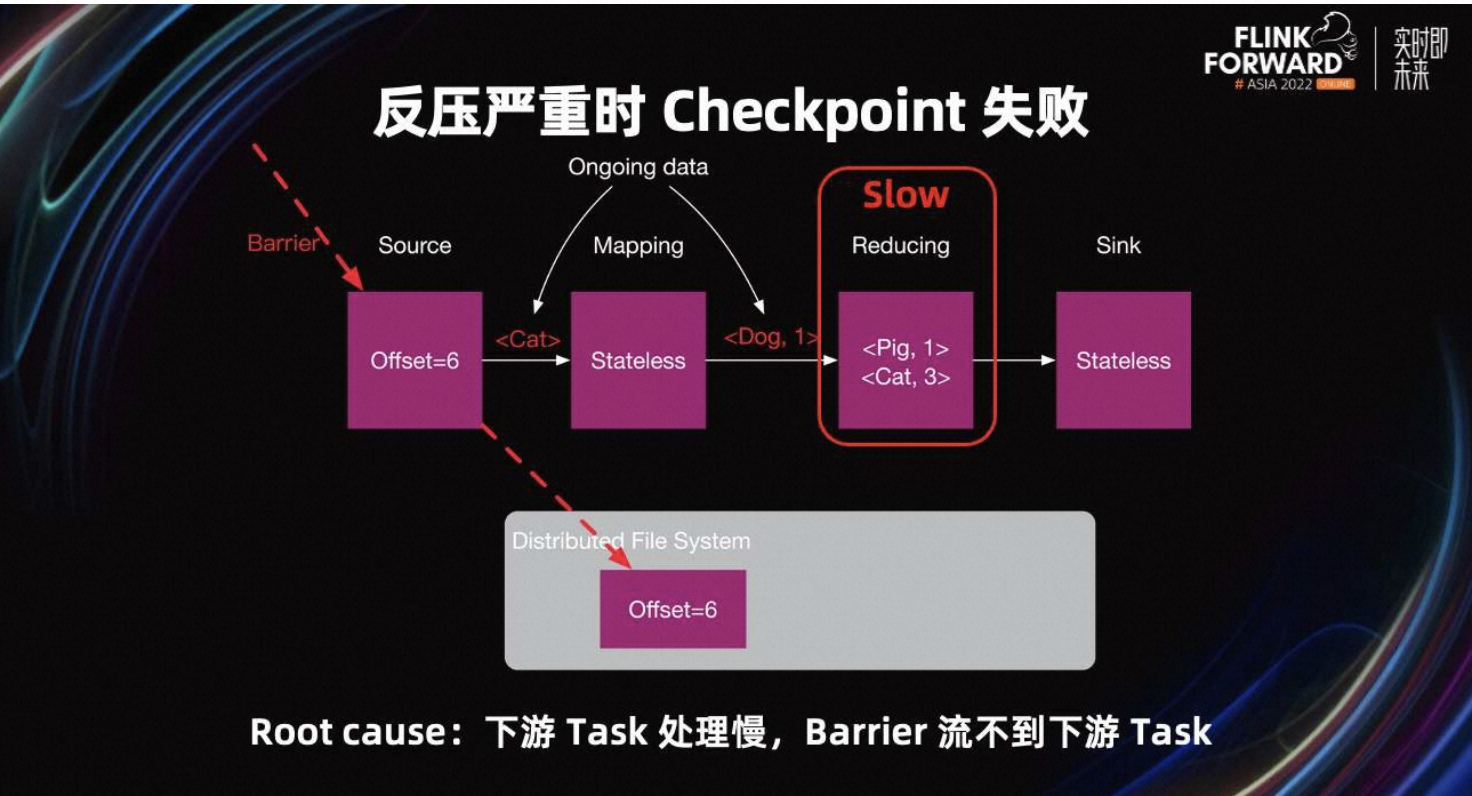
Task 必须处理完 Barrier 之前的所有数据,才能接收到 Barrier。例如 Reducing Task 处理数据慢,Task 不能快速消费完 Barrier 前的所有数据,所以不能接收到 Barrier。最终 Reducing Task 的 Checkpoint 就会失败,从而导致 Job 的 Checkpoint 失败。
1.5 Unaligned Checkpoint 核心思路
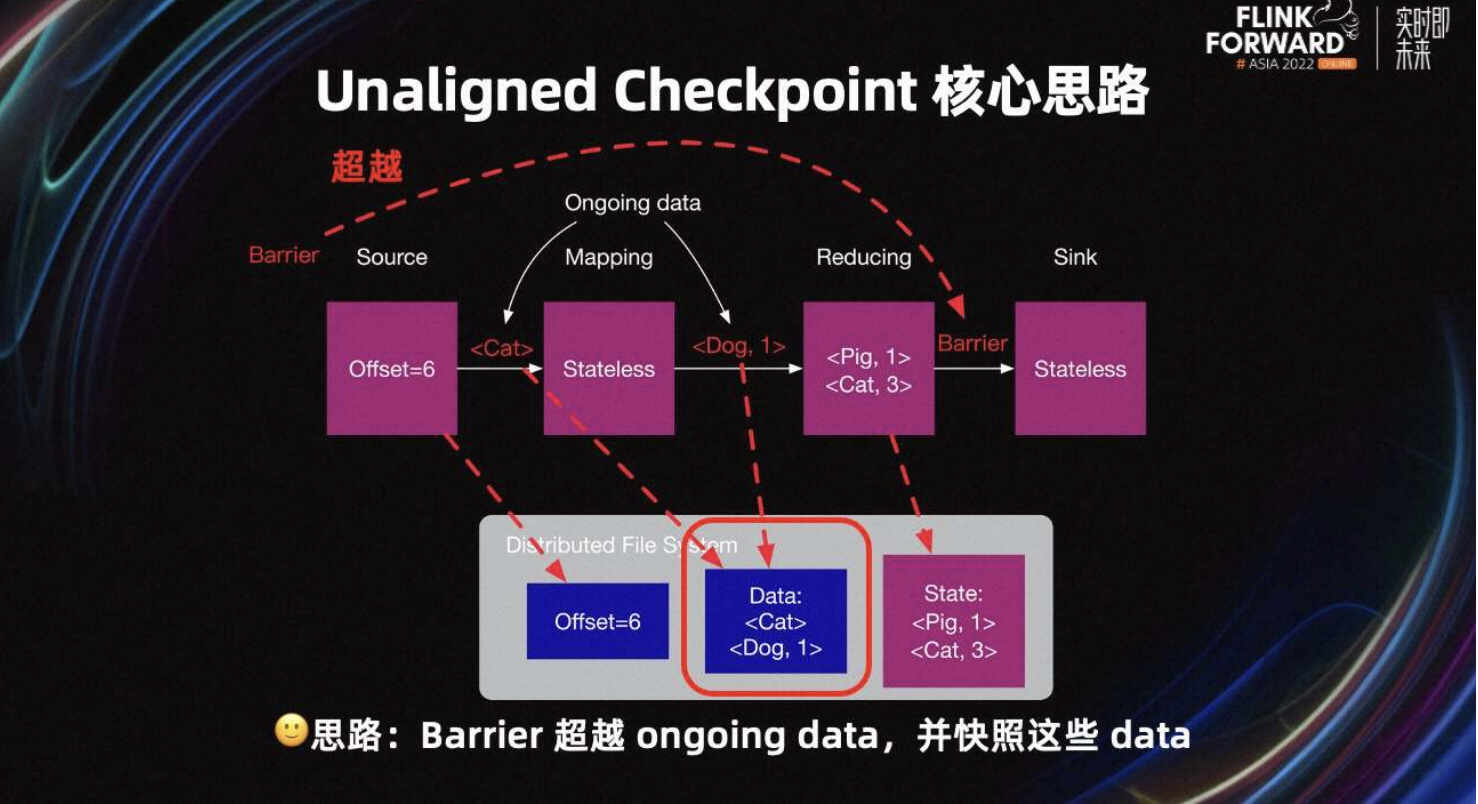
UC 的核心思路是 Barrier 超越这些 ongoing data,即 Buffer 中的数据,并快照这些数据。由此可见,当 Barrier 超越 ongoing data 后,快速到达了 Sink Task。与此同时,这些数据需要被快照,防止数据丢失。
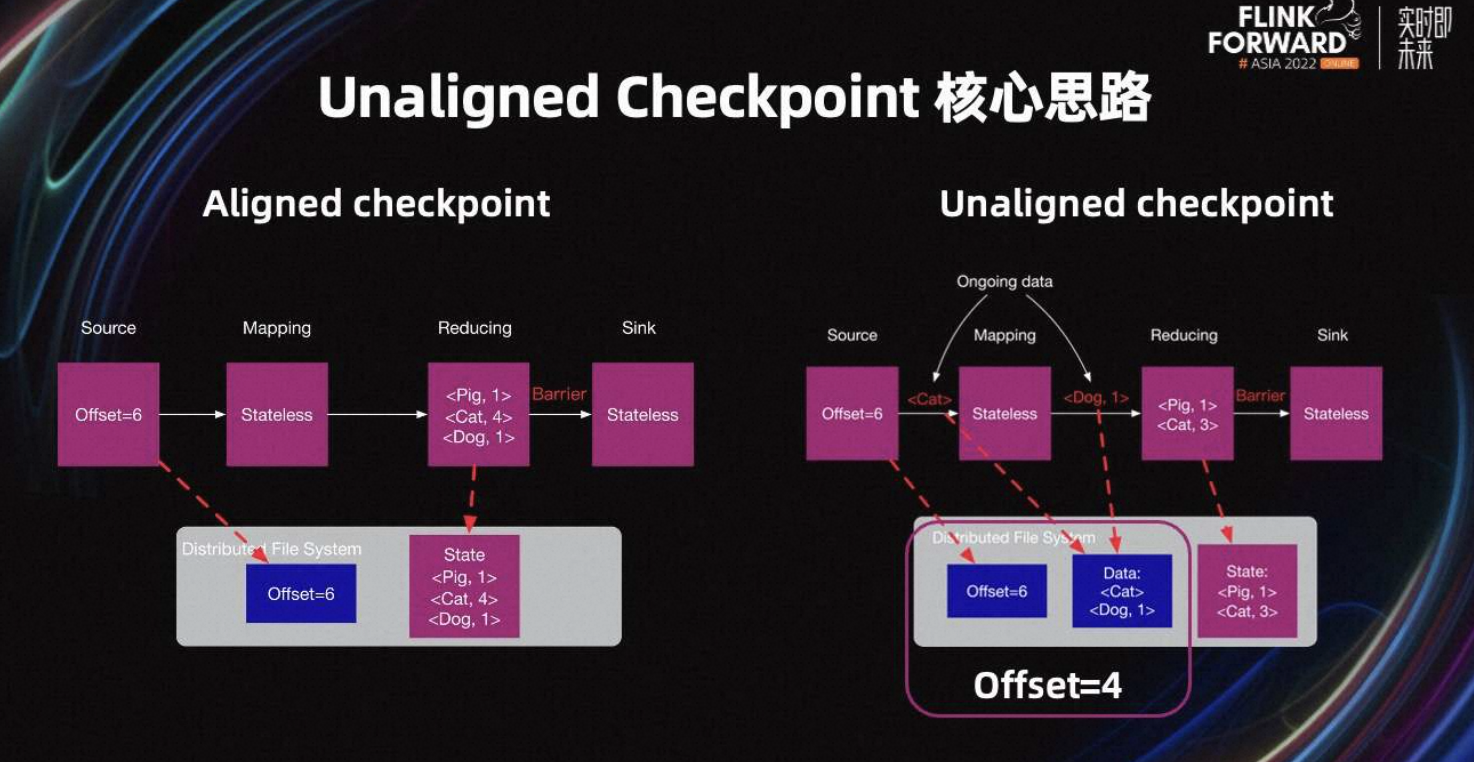
上图是 UC 和 AC 的简单对比,对于 AC,Offset 与数据库 Change log 类似。对于 UC,Offset 和 data 与数据库的 Change log 类似。Offset6 和 data 的组合,可以认为是 Offset4。其中,Offset4 和 Offset5 的数据从 State 中恢复,Offset6 以及以后的数据从 Kafka 中恢复。
二、Unaligned Checkpoint 原理
2.1 Unaligned Checkpoint 的实现原理
了解完 Checkpoint 存在的问题以及 UC 的核心思路后。接下来主要介绍 UC 的实现原理。
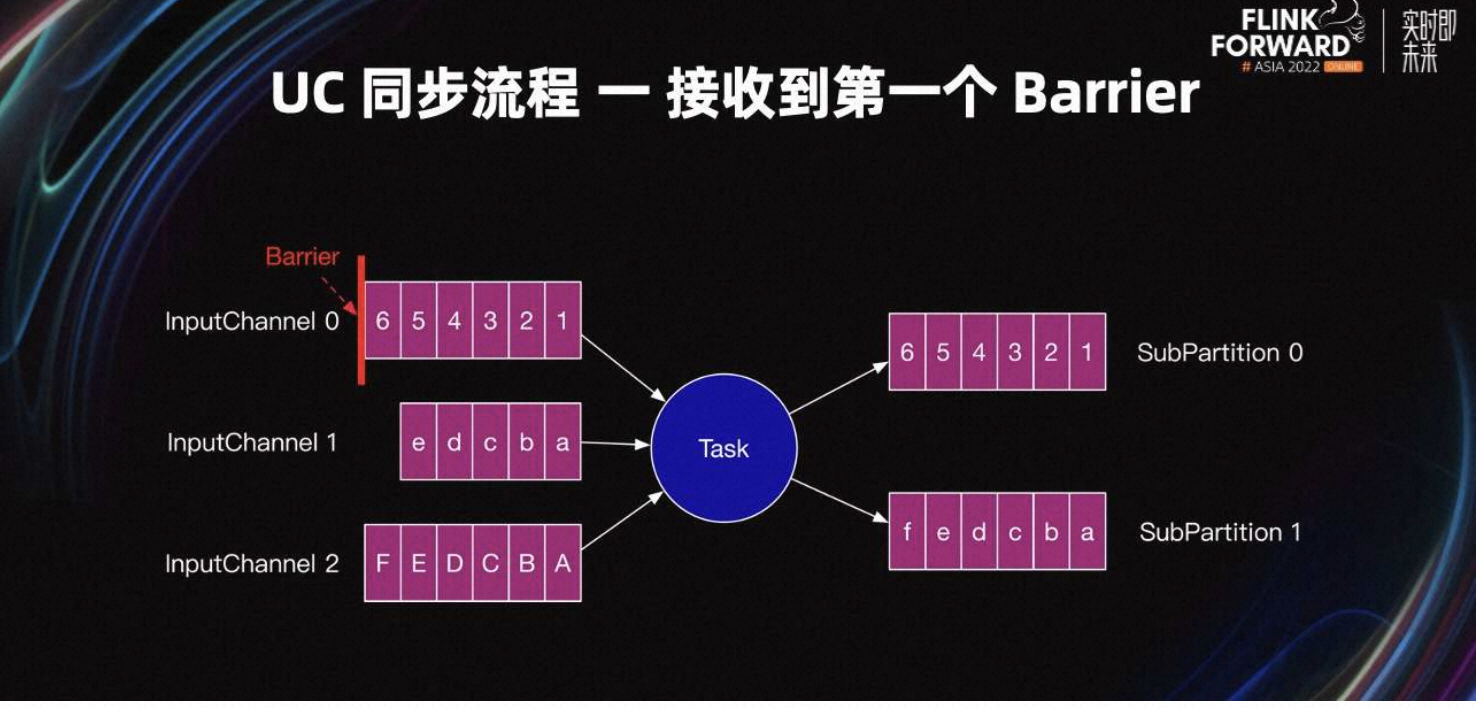
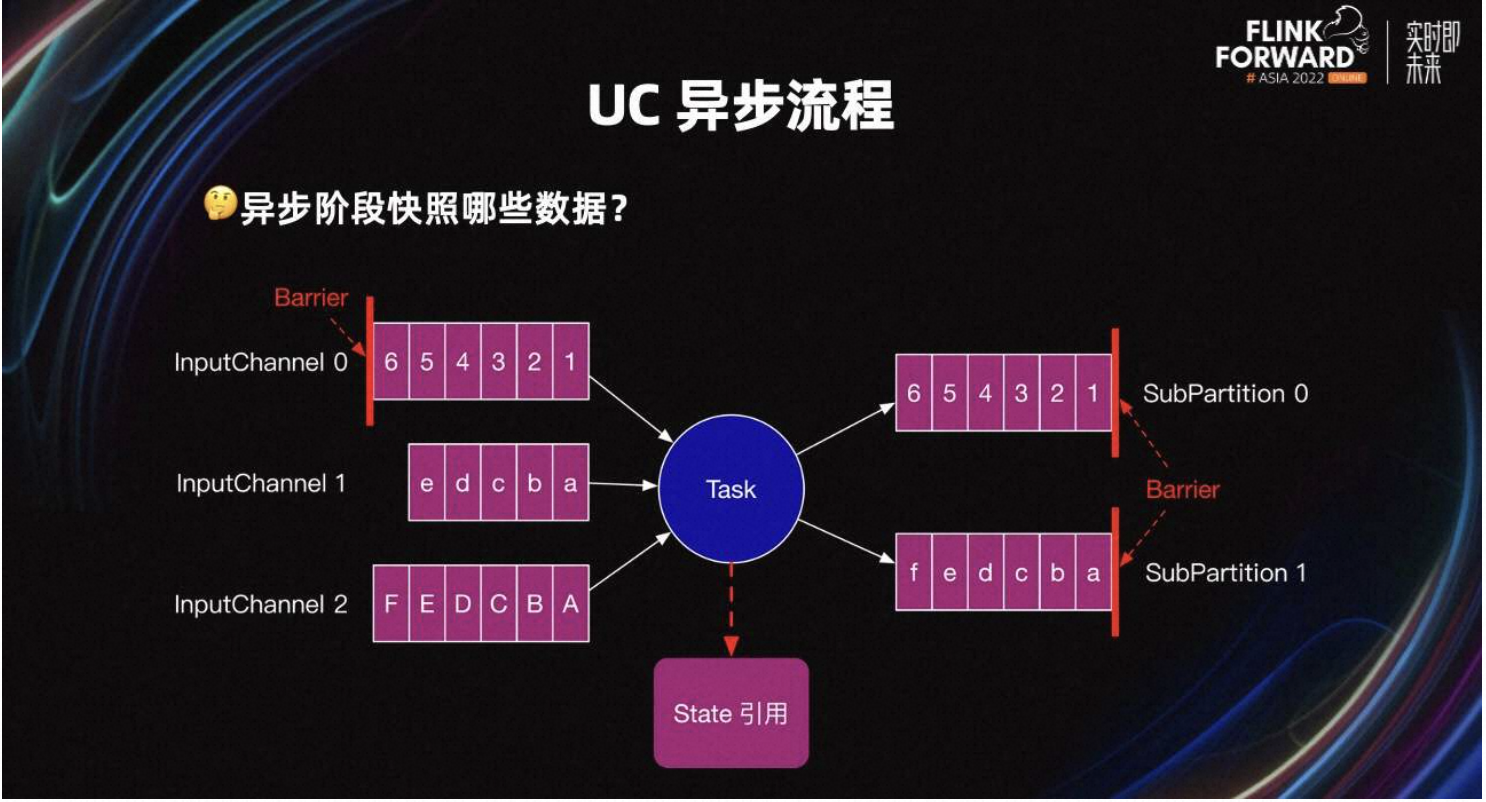
假设当前 Task 的上游 Task 并行度为 3,下游 Task 并行度为 2。如图所示,Task 会有三个 InputChannel 和两个 SubPartition。紫红色框表示 Buffer 中的一条条数据。
UC 开始后,Task 的三个 InputChannel 会陆续收到上游发送的 Barrier。如图所示,InputChannel 0 先收到了 Barrier,其他 Inputchannel 还没有收到 Barrier。当某一个 InputChannel 接收到 Barrier 时,Task 会直接开始 UC 的第一阶段,即:UC 同步阶段。
这里只要有任意一个 Barrier 进入 Task 网络层的输入缓冲区,Task 就会直接开始 UC,不用等其他 InputChannel 接收到 Barrier,也不需要处理完 InputChannel 内 Barrier 之前的数据。
2.2 UC 同步流程
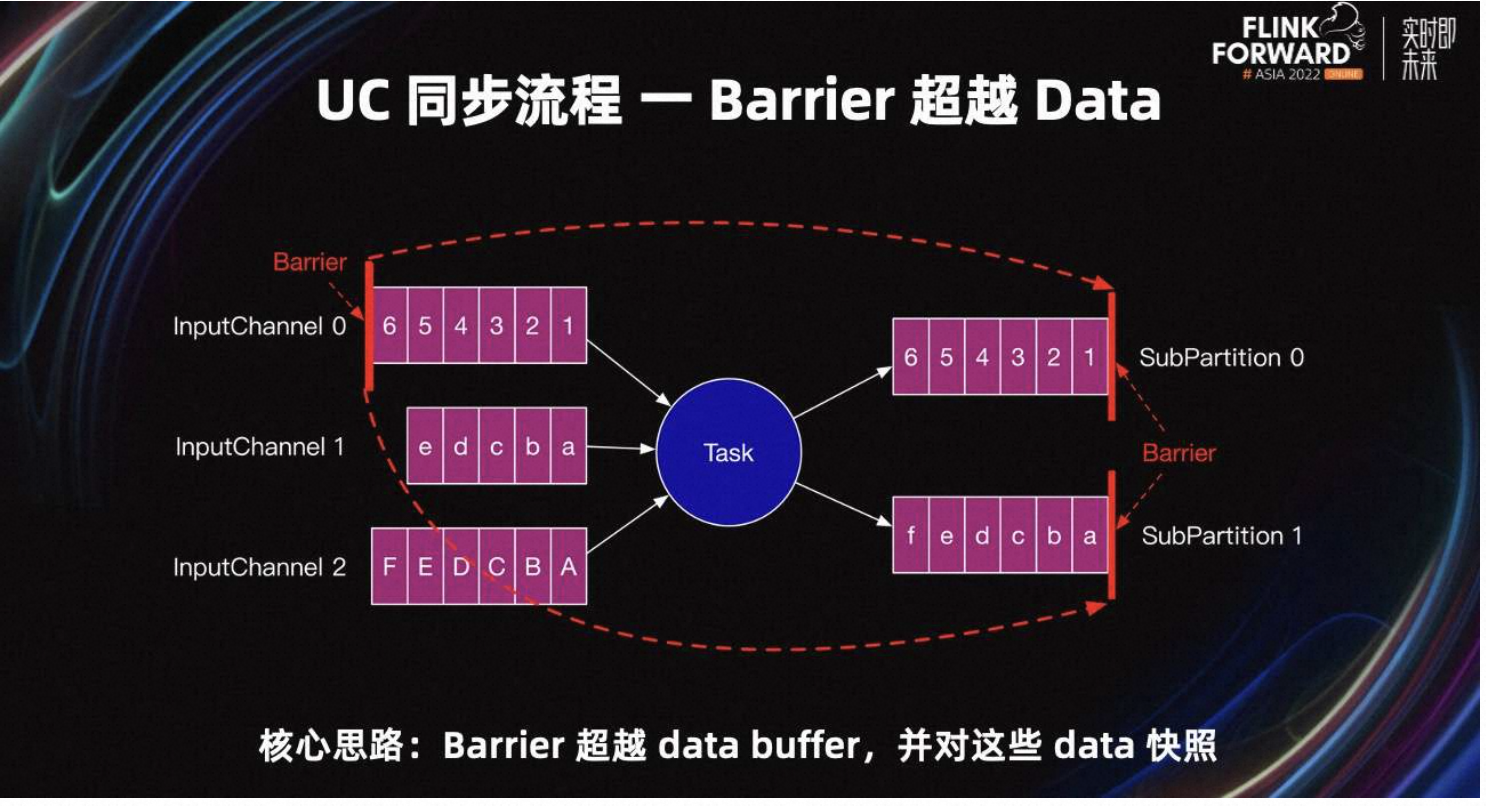
UC 同步阶段的核心思路是:Barrier 超越所有的 data Buffer,并对这些超越的 data Buffer 快照。我们可以看到 Barrier 被直接发送到所有 SubPartition 的头部,超越了所有的 input 和 output Buffer,从而 Barrier 可以被快速发送到下游 Task。这也解释了为什么反压时 UC 可以成功:
- 从 Task 视角来看,Barrier 可以在 Task 内部快速超车。
- 从 Job 视角来看,如果每个 Task 都可以快速超车,那么 Barrier 就可以从 Source Task 快速超车到 Sink Task。

为了保证数据一致性,在 UC 同步阶段 Task 不能处理数据。同步阶段主要有上图中的流程。
- Barrier 超车:保证 Barrier 快速发送到下游 Task。
- 对 Buffer 进行引用:这里只是引用,真正的快照会在异步阶段完成。
- 调用 Task 的 SnapshotState 方法。
- State backend 同步快照。
UC 同步阶段的最后两步与 AC 完全一致,对算子内部的 State 进行快照。
2.3 UC 异步流程
当 UC 同步阶段完成后,会继续处理数据。与此同时,开启 UC 的第二阶段:Barrier 对齐和 UC 异步阶段。
异步阶段要快照同步阶段引用的所有 input 和 output Buffer,以及同步阶段引用的算子内部的 State。
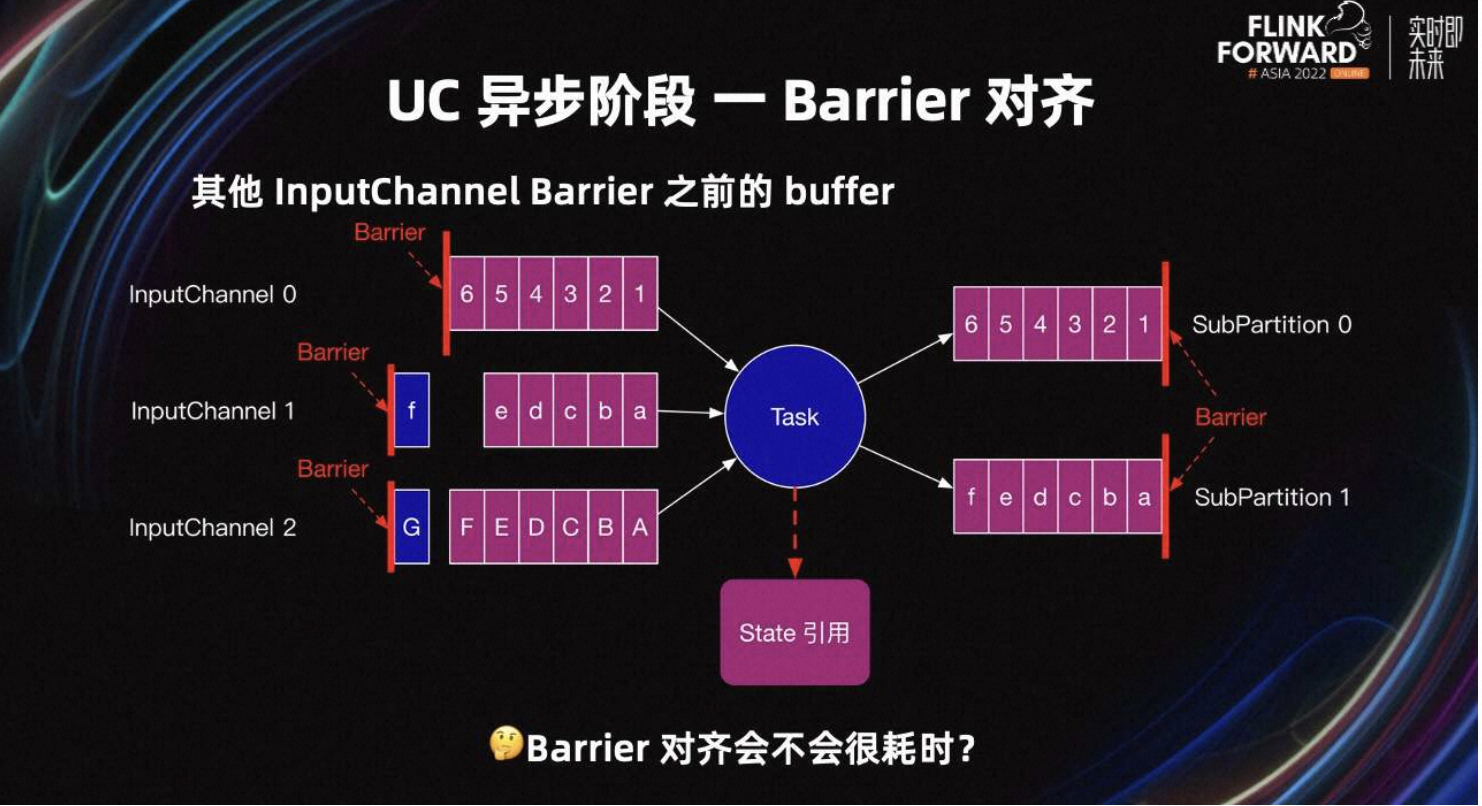
除此之外,UC 也有 Barrier 对齐。当 Task 开始 UC 时,有很多 Inputchannel 没接收到 Barrier。这些 InputChannel Barrier 之前的 Buffer,可能还有一些 Buffer 需要快照。例如上图中 InputChannel1 的 f 和 InputChannel2 的 g。
所以 UC 的第二阶段需要等所有 InputChannel 的 Barrier 到达,且 Barrier 之前的 Buffer 都需要快照,这就是所谓的 UC Barrier 对齐。
那 UC 的 Barrier 对齐会不会很耗时呢?理论上 UC 的 Barrier 对齐会很快,像之前的 Task 一样,Barrier 可以快速超越所有的 input 和 output Buffer,优先发送 Barrier 给下游 Task。所以上游 Task 也类似,Barrier 超越上游所有的 Buffer 快速发送给当前 Task。

接下来,总结一下 UC 异步阶段流程。异步阶段需要写三部分数据到 HDFS,分别是:
-
同步阶段引用的算子内部的 State。
-
同步阶段引用的所有 input 和 output Buffer。
-
以及其他 input channel Barrier 之前的 Buffer。
当这三部分数据写完后,Task 会将结果汇报给 JobManager,Task 的异步阶段结束。其中算子 State 和汇报元数据流程与 Aligned Checkpoint 一致。

理论上,反压时 Barrier 可以一路超车,快速从 Source Task 超车到 Sink,保证 UC 可以快速完成。
但现实却是 UC 效果不佳,很多反压场景 UC 仍然不能完成。而且 UC 相比 AC 有大量的额外风险和 bug。
三、大幅提升 UC 收益
3.1 Task 处理数据流程

接下来介绍哪些场景 UC 不能完成以及通过一些优化项大幅提升 UC 的适用场景和收益。
首先看一下 Task 处理数据流程。Task 会检查是否有接收到 UC Barrier。如果接收到,直接进行 UC。如果没有接收到 Barrier,则检查是否有接收到数据。如果也没有接收到数据,则循环检测。如果接收到数据,就开始处理。处理数据分三步:
- 如果是 Source Task,则从 Source 读取数据。如果是非 Source Task,则从 input channel 读取数据。
- 读取到数据后,执行业务逻辑开始处理。
- 处理完以后,将结果写入到 output Buffer 中。
当处理结束后,再次循环检测。
如果 Task 处理一条数据并写入到 output Buffer 需要十分钟。那么在这 10 分钟期间,就算 UC Barrier 来了,Task 也不能进行 Checkpoint,所以 UC 还是会超时。
通常处理一条数据不会很慢,但写入到 output Buffer 里,可能会比较耗时。因为反压严重时,Task 的 output Buffer 经常没有可用的 Buffer,导致 Task 输出数据时经常卡在 request memory 上。这就是我们熟知的 Flink 反压机制。
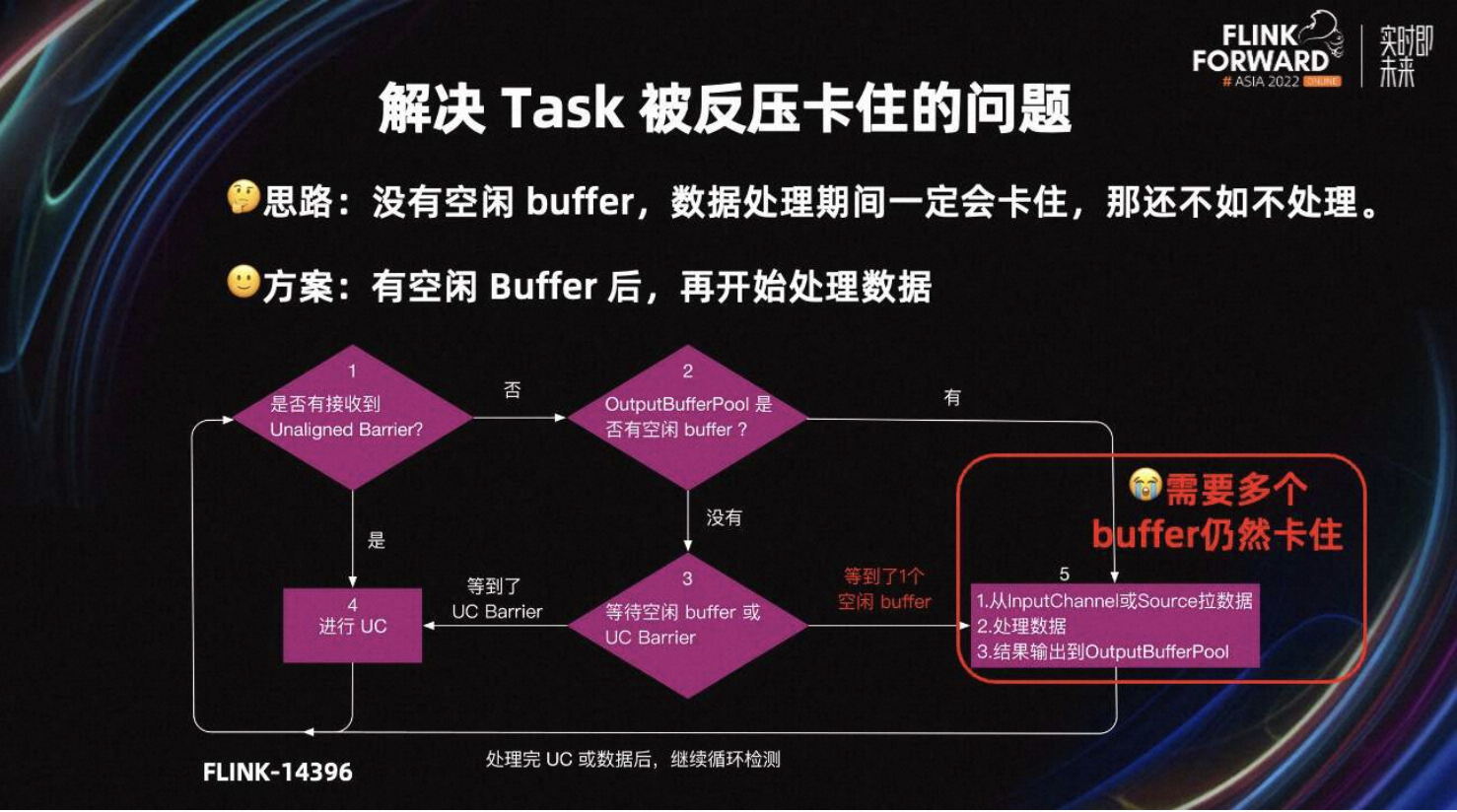
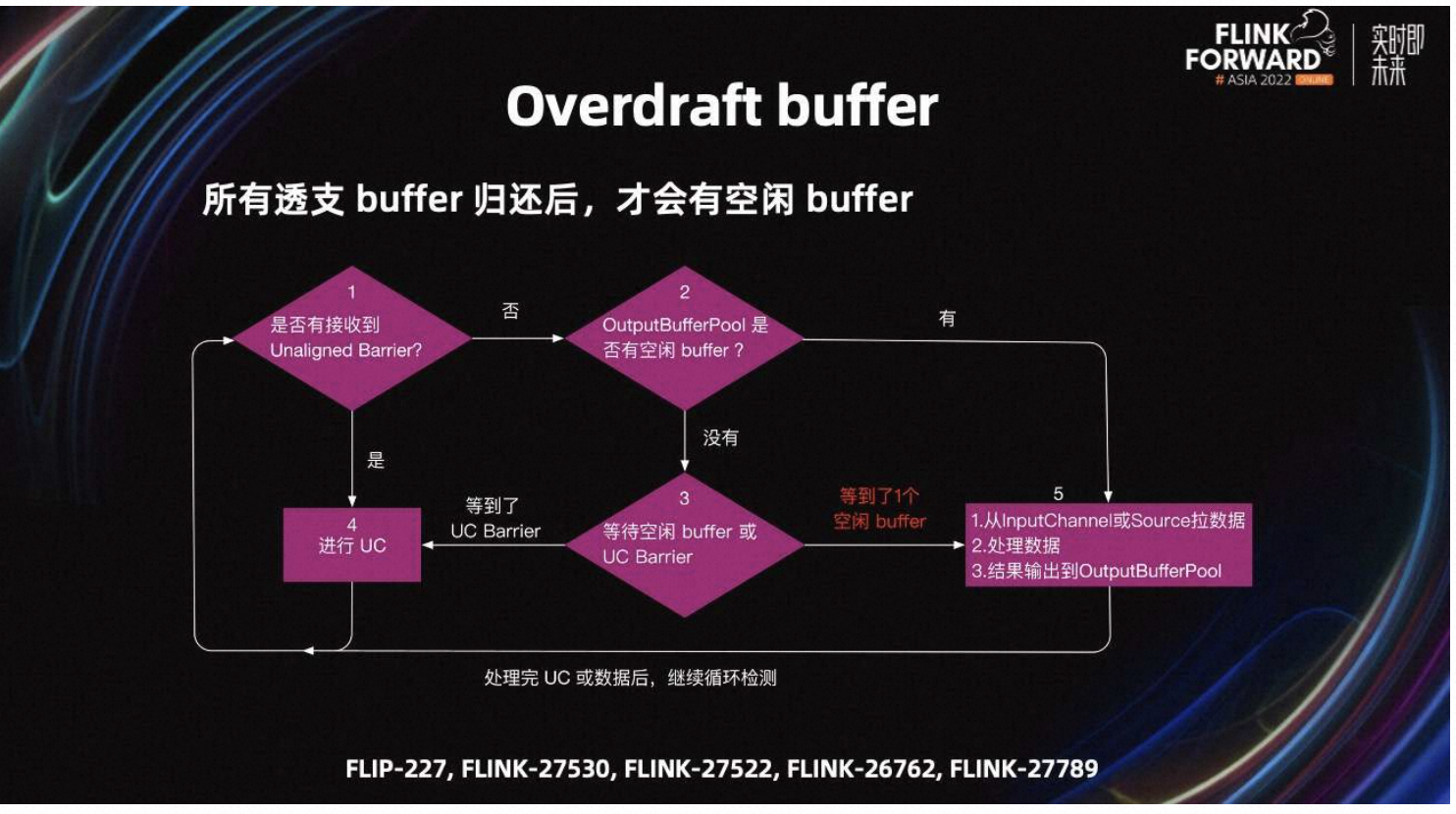
如果没有空闲 Buffer,数据处理完也一定会卡住,还不如不处理。所以 Flink 社区在 Flink-14396 中引入了检查空闲 Buffer 的机制。解决方案是 Task 在处理数据前,检查 output Buffer Pool 是否有空闲的 Buffer,等有空闲 Buffer 分后再处理数据。
详细处理流程如图所示,首先会检查是否接收到 Barrier。如果有,则进行 UC;如果没有,则先判断 output Buffer Pool 是不是有空闲的 Buffer,如果有则处理数据,如果没有则进入第三步,等待空闲 Buffer 或 UC Barrier。如果等到 Barrier,则开始 Checkpoint;如果等到了一个空闲 Buffer,则开始处理数据。
优化前,Task 会卡在第五步的数据处理环节,不能及时响应 UC。优化后,Task 会卡在第三步,在这个环节接收到 UC Barrier 时,也可以快速开始 UC。
第三步,只检查是否有一个空闲 Buffer。所以当处理一条数据需要多个 Buffer 的场景,Task 处理完数据输出结果时,可能仍然会卡在第五步,导致 Task 不能处理 UC。
例如单条数据较大,flatmap 算子、window 触发以及广播 watermark,都是处理一条数据,需要多个 Buffer 的场景。这些场景 Task 仍然会卡在 request memory 上。
3.2 Overdraft Buffer
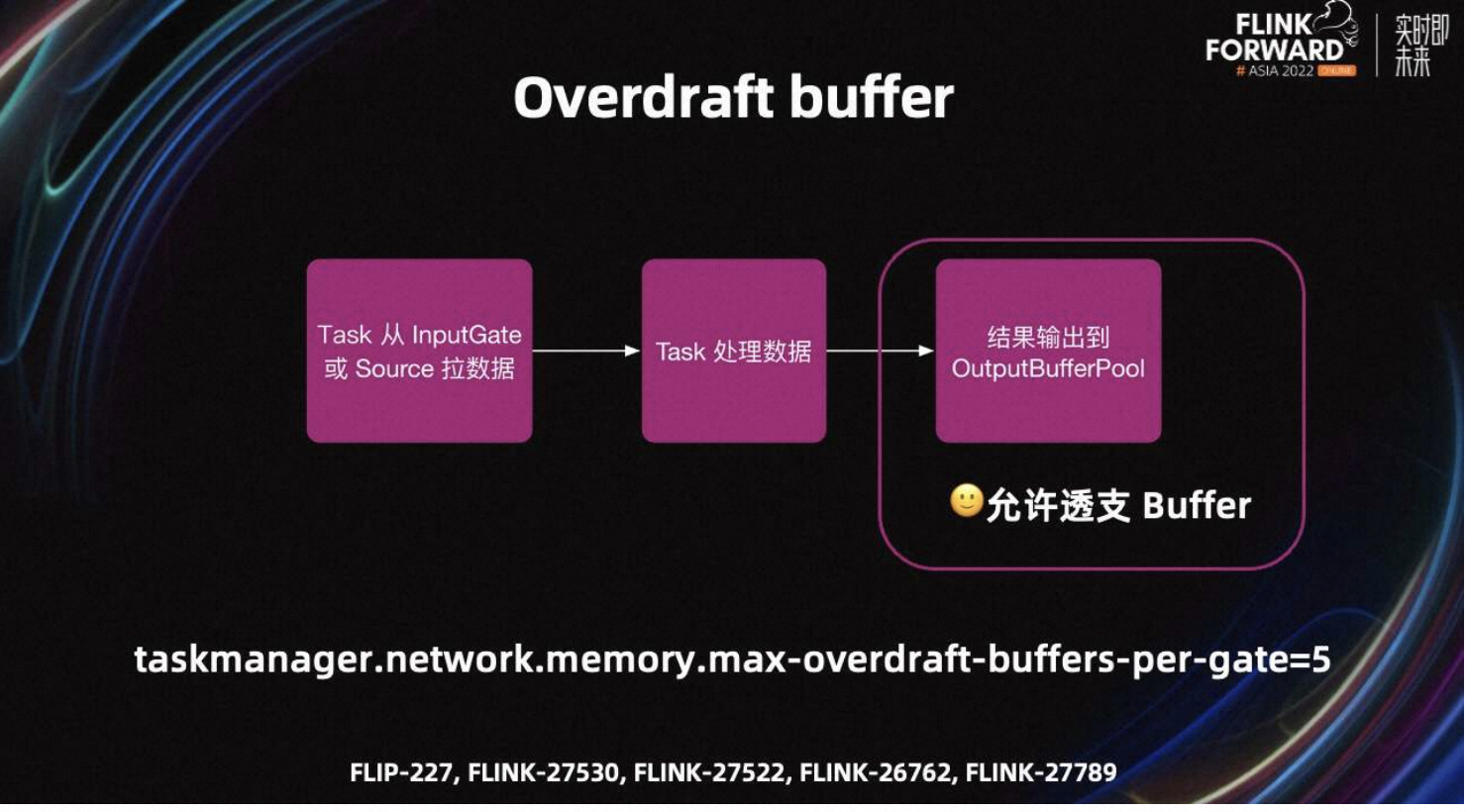
基于上述问题,FLIP-227 提出了 overdraft Buffer(透支 Buffer)的提议。
Task 处理数据时有三步,即拉数据、处理数据以及输出结果。透支 Buffer 的思路是,在输出结果时,如果 output Buffer pool 中的 Buffer 不足,且 Task 有足够的 network Buffer。则当前 Task 会向 TM 透支一些 Buffer,从而完成数据处理环节,防止 Task 阻塞。
优化后处理一条数据需要多个 Buffer 的场景,UC 也可以较好的工作。默认每个 gate 可以透支五个 Buffer,可以调节 max-overdraft-Buffer 参数来控制可以透支的 Buffer 量。
Task 一定会在没有空闲 Buffer 时,才会使用透支 Buffer。一旦透支 Buffer 被使用,Task 在等待 Barrier 和空闲 Buffer 时,会认为没有空闲 Buffer。直到所有透支 Buffer 都被下游 Task 消费,且 output Buffer pool 至少有一个空闲 Buffer 时,Task 才能继续处理数据。Flink 1.16 已经支持了透支 Buffer 功能。
3.3 Legacy Source

接下来,介绍一下 Legacy Source 的提升。从数据的来源划分,Flink 有两种 Task,分别是 Source Task 和非 Source Task。Source Task 从外部组件读取数据到 Flink Job。非 Source Task 从 input channel 中读取数据,数据来源于上游 Task。
非 Source Task 会检查有空闲 Buffer 后,再从 input channel 里拿数据。Source Task 从外部组件读取数据前,如果不检查是否有空闲 Buffer,则 UC 会表现不佳。
Flink 有两种 Source,分别是 Legacy Source 和新的 Source。新 Source 与 Task 的工作模式属于拉的模式。工作模式与 input channel 类似,Task 会检查有空闲 Buffer 后,再从 Source 中拿数据。
如图所示,Legacy Source 是推的模式。Legacy Source 从外部系统读数据后,直接往下游发送。当没有空闲 Buffer 时,就会卡住,不能正常处理 UC。
Legacy Source 属于社区废弃的 Source,遗憾的是我们生产环境大部分 Flink 1.13 的任务仍在使用 Legacy Source,所以我们对常用的 Legacy Source 做了改进。
改进思路与上述思路类似:Legacy Source 检查有空闲 Buffer 后,再开始处理数据。Flink 中最常用的 FlinkKafkaConsumer 就是 Legacy Source,所以业界的 Flink 很多用户仍在使用。我们将内部的改进版 Legacy Source 分享到了 Flink-26759 中,有需要的同学可以参考。
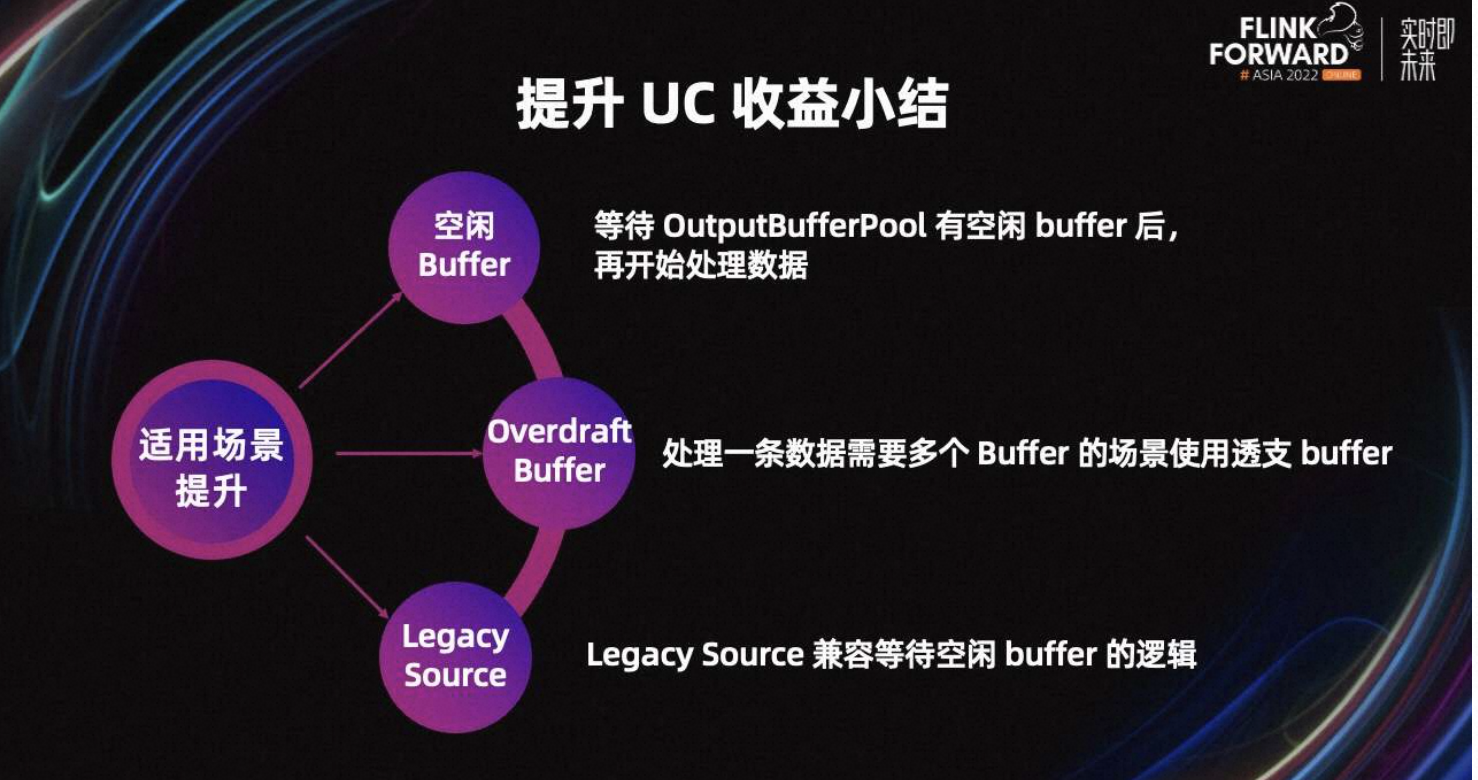
最后,对提升 UC 收益做一个小结。为了防止 Task 在处理数据期间卡住,Flink 会等待有空闲 Buffer 后再处理数据。处理一条数据需要多个 Buffer 的场景,为了防止 Task 卡住,引入了 Overdraft Buffer 来解决。除此之外,Legacy Source 也支持了等待空闲 Buffer 的逻辑。
四、大幅降低 UC 风险
4.1 UC 风险

接下来我会介绍 UC 带来的额外风险以及如何规避风险。
首先,介绍一下 UC 在大规模生产下有哪些风险。由于 UC 比 AC 写入了额外的数据,这些数据会带来一些问题。
例如,作业重启前后,如果数据序列化不兼容,则 UC 无法恢复。其次,如果算子之间的连接发生改变,UC 也无法恢复。除此之外,这些数据会写大量的小文件到 DFS,可能会给系统带来压力。
与此同时,我们在调研和使用过程中发现了一些 UC 的 bug。例如死锁和内存泄露。
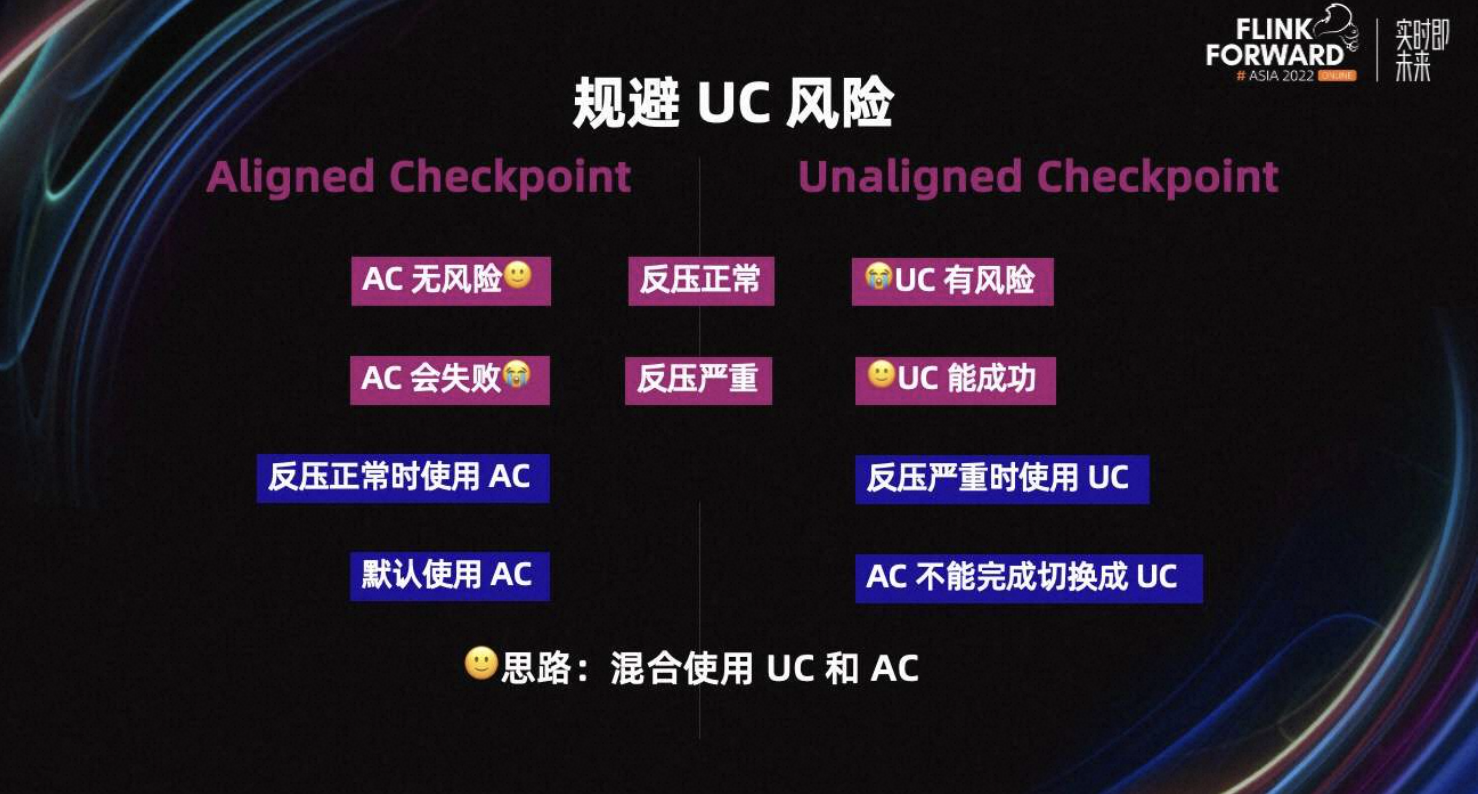
如上图所示,简单对比一下 AC 和 UC。当反压正常时,AC 和 UC 都能成功,但 AC 无风险,UC 有风险,所以 AC 更好。当反压严重时,AC 会失败,但 UC 能成功,所以 UC 更好。所以我们的目标是,反压正常时使用 AC,反压严重时使用 UC。
如何实现这个目标呢?我们的思路就是混合使用 AC 和 UC。即默认使用 AC,当 AC 不能完成时切换成 UC。

Flink 社区在 1.13 提出了 AC timeout 机制,即默认使用 AC。当 AC 在 AC timeout 内不能完成时,从 AC 切换为 UC。
但在我们调研时发现,AC timeout 机制效果不佳。假设 AC timeout 是一分钟,且 Checkpoint timeout 是五分钟,即默认使用 AC。如果 AC 1 分钟内不能成功,则切换为 UC。如果 Checkpoint 总时长超过五分钟,就会超时失败。
效果不佳主要体现在,当一分钟时间到了,Job 仍然不能从 AC 切换为 UC,甚至五分钟都不能切换成为 UC,最终导致 Checkpoint 超时失败。
4.2 AC timeout 机制

接下来,详细介绍一下 AC timeout 机制。AC timeout 在社区的发展主要有三个阶段,Flink-19680 首次支持了 AC timeout 机制。
第一阶段的原理是,Task 从接收到第一个 Barrier 开始计时,超过一分钟还未接收到所有 input channel 的 Barrier,则切换为 UC,或者说 Barrier 对齐时间超过一分钟,则切换为 UC。

第一阶段存在的问题是,每个 Task 接收到第一个 Barrier 后,59 秒接收到所有 Barrier,则不会切换为 UC,但多个 Task 的时间会累计。
我们期望 Job 的 AC 一分钟未完成,再切换为 UC。但图中除了 Source Task 以外的 7 个 Task,每个 Task 都用了 59 秒,所以 Task 都不会切换为 UC。但 7*59 秒,总时间已经超过了五分钟,所以最终会超时失败。
相应解决思路是,AC timeout 应该全局累积。
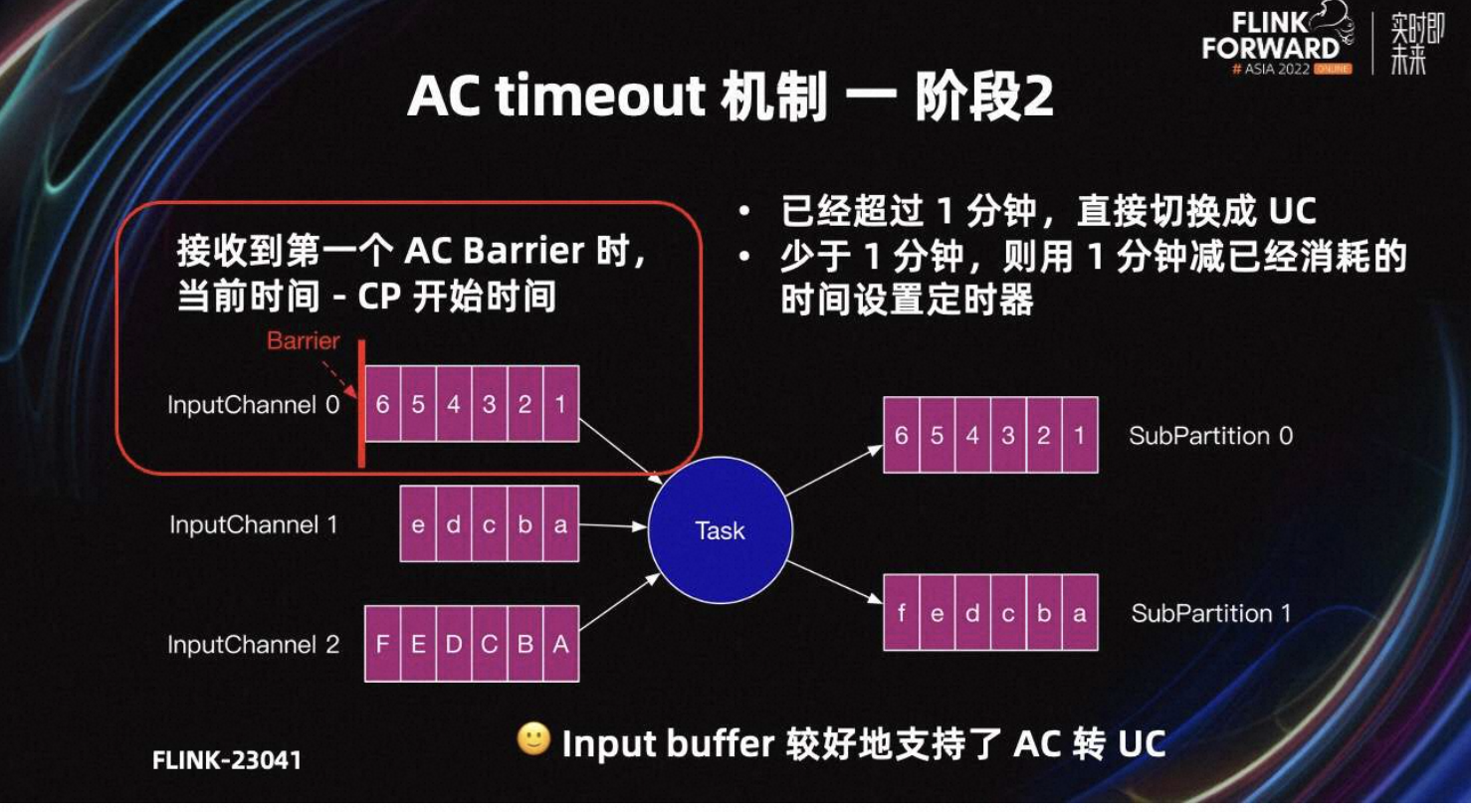
基于阶段一的问题,Flink-23041 进行了改进。第二阶段的原理是,当 input channel 收到 Barrier 后,用当前系统时间减去 Checkpoint 的开始时间,表示 Checkpoint 已经过了多久。
如果超过了一分钟,直接切换为 UC。如果少于一分钟,则用一分钟减 AC 已经消耗的时间,表示希望多久以后切换成 UC。通过设定一个定时器,当 cp 全局时间到达一分钟时触发,时间到了就会切换为 UC。
阶段二相比阶段一,解决了多个 Task 时间累积的问题。只要 input channel 接收到 Barrier,且在指定时间内 AC 没有完成,就可以定时将 AC 切换为 UC。所以阶段二完成后,input Buffer 已经可以较好的支持从 AC 转化为 UC。
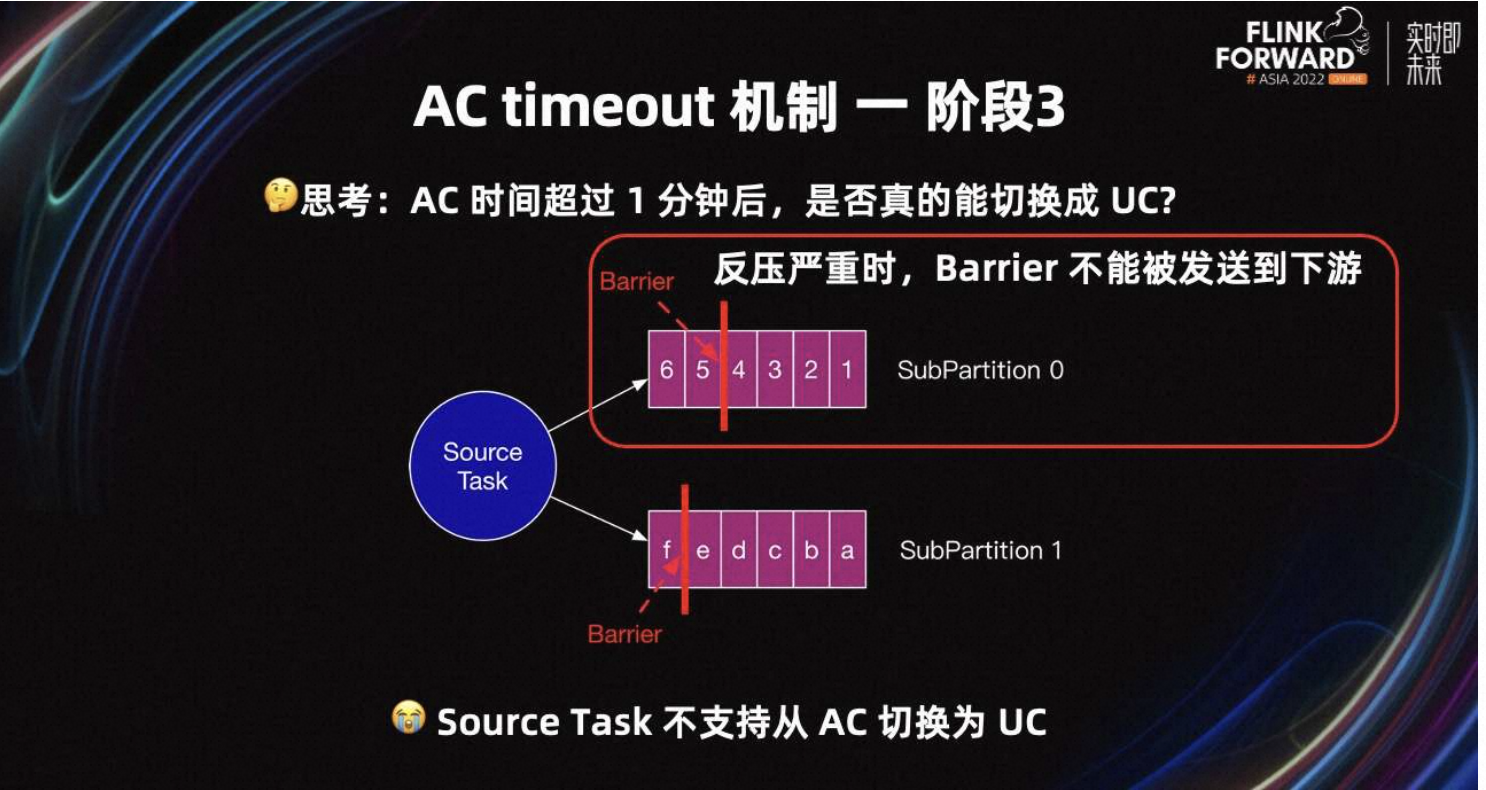
当时间超过一分钟后,所有 Task 真的能从 AC 转化为 UC 吗?例如 Source Task 反压严重时,Barrier 不能被发送到下游。下游 Task 接收不到 Barrier,所以无法从 AC 转化为 UC。当前 Source Task 也不支持从 AC 切换为 UC。

非 Source Task 亦是如此,如果一分钟内接收到了所有 Barrier,则当前 Task 不会切换为 UC。但可能由于反压严重,Barrier 长时间不能发送到下游。所以根本问题是,只有 input Buffer 支持从 AC 切换为 UC,但 output Buffer 不支持从 AC 切换成 UC。
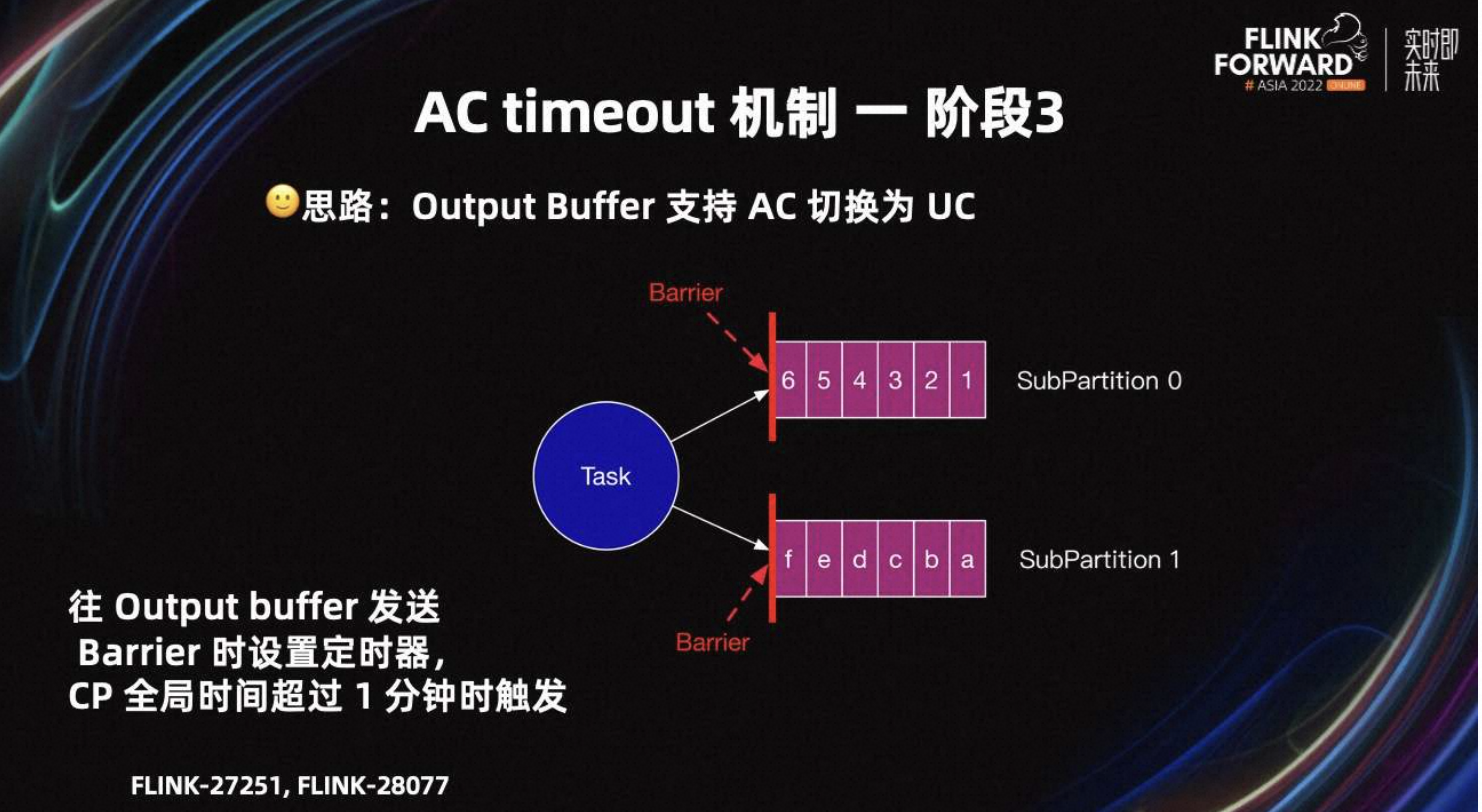
基于这个问题,我们在 Flink-27251 中提出了支持 Output Buffer 从 AC 切换为 UC 的改进。设计思路是 Task 往 output Buffer 发送 Barrier 时,设置定时器,CP 全局时间超过一分钟时触发。
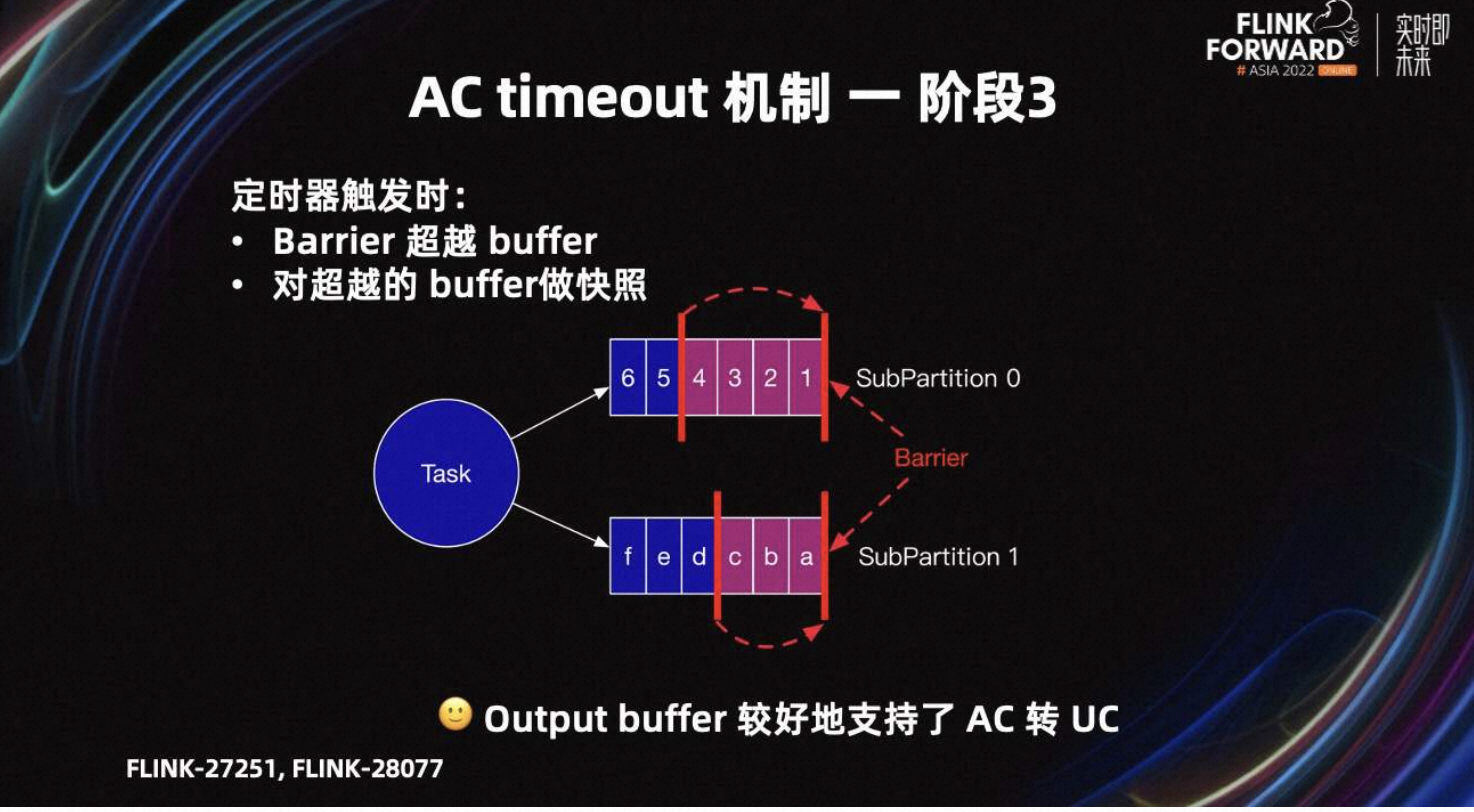
当定时器触发时,output Buffer 切换为 UC,需要进行两个操作。
-
Barrier 超越 Buffer,到 SubPartition 头部。保证 Barrier 快速超车到下游 Task。
-
对图中超越的紫红色 Buffer 做快照。
阶段三完成后,input 和 output Buffer 都可以较好地支持 AC 转 UC 了。
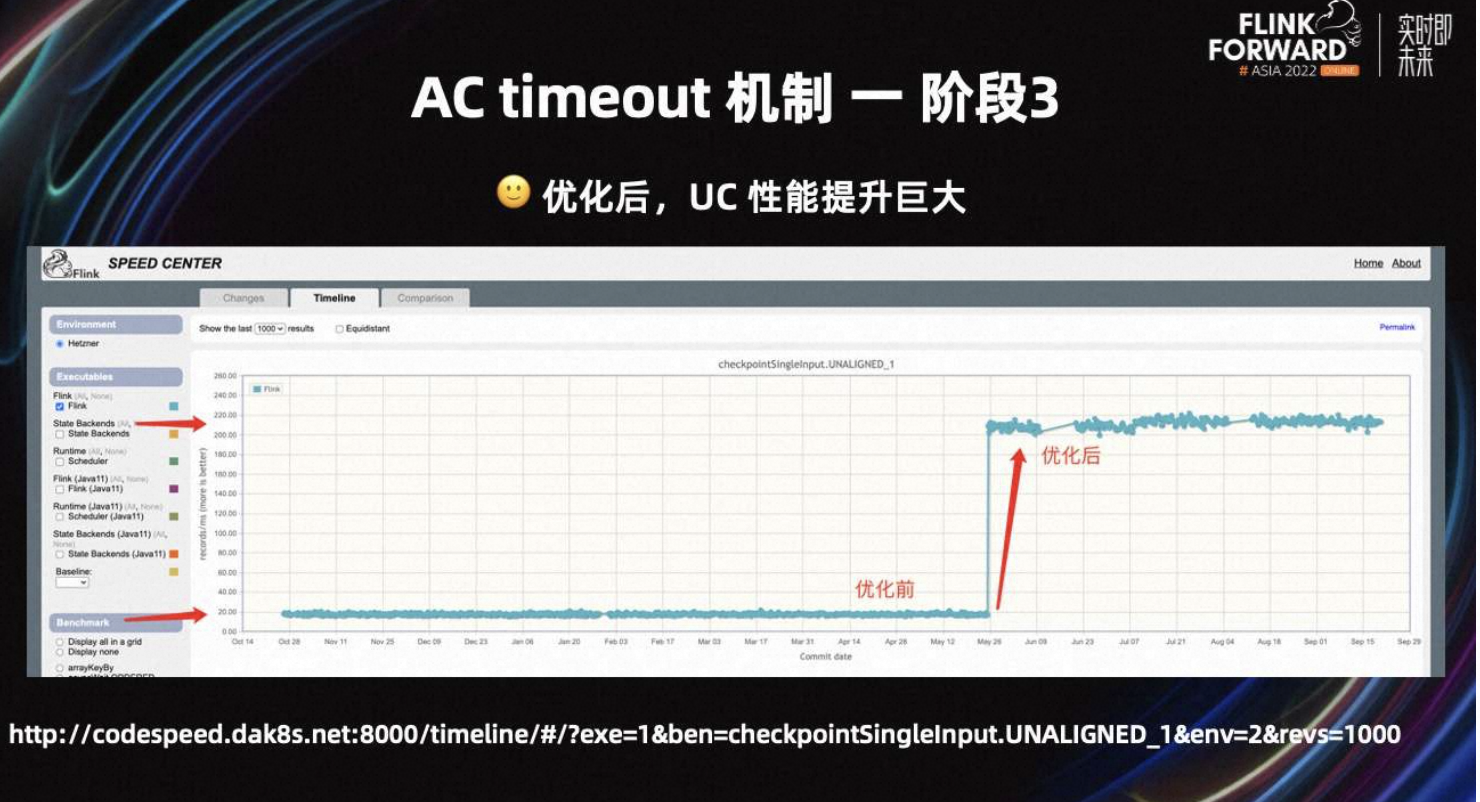
Flink 社区早期为 Checkpoint 设计了 Benchmark,用来评估 Checkpoint 的性能。如上图所示,该优化 merge 到 Flink master 分支后,UC 的性能提升非常明显。这里有链接可以查看 Flink benchmark 的结果,相关地址:
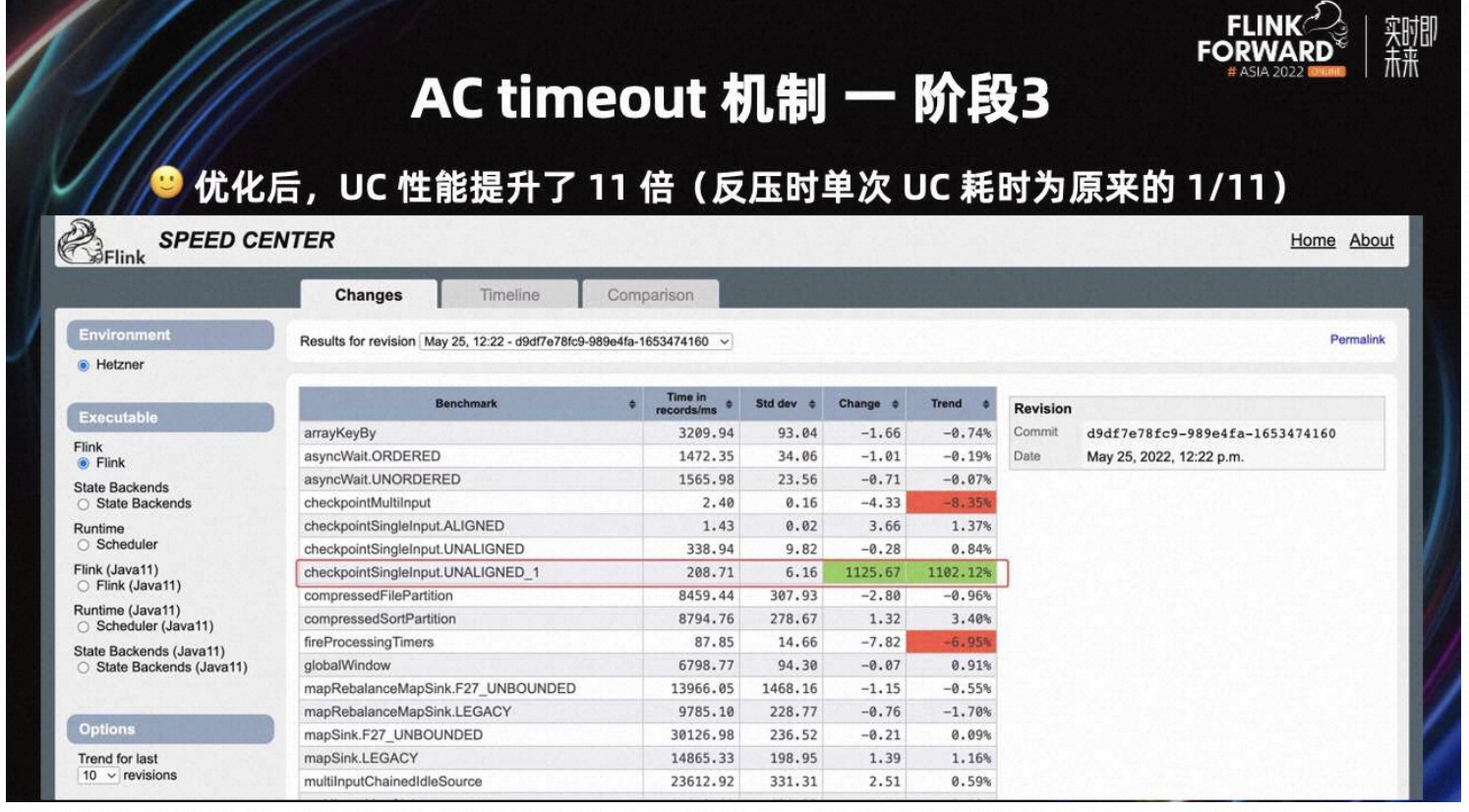
从 Benchmark 图中可以看出,优化后 UC 的性能提升了 11 倍。当反压严重时,单次 UC 耗时为原来的 1/11。

最后,对 AC timeout 机制、AC 和 UC 混合使用场景进行总结。经过上述优化后可以达到的效果是,反压严重时,使用 UC 反压;反压正常时,使用 AC。
对业务侧的收益是,反压严重时,Checkpoint 可以成功。反压正常时,无任何额外的风险和开销。
4.3 非常多的小文件

如果整个集群大量作业同时反压严重,大量作业同时切换为 UC,仍然有其他风险。
假设一个作业有 8 个 Task,各个 Task 的并行度都是 2000。UC 默认每个 Task 写一个文件,所以该 Job 最多会写 1.6 万个文件。
当生产环境有大量 Flink Job 在写 Kafka 时,假设 Kafka 集群出现网络瓶颈或磁盘瓶颈,大量 Flink 任务会反压。此时,大量 Flink 任务会同时从 AC 切换为 UC,瞬间整个集群会突增数上百万个小文件,导致 UC 对 DFS 的压力很难评估。
因为很多任务平时是无状态的,平时对 HDFS 的访问很少。但 UC 会让所有任务都变得有状态,且文件数较多,所以这也算是一个隐患。如果大量任务同时切换为 UC,HDFS 可能会血崩。
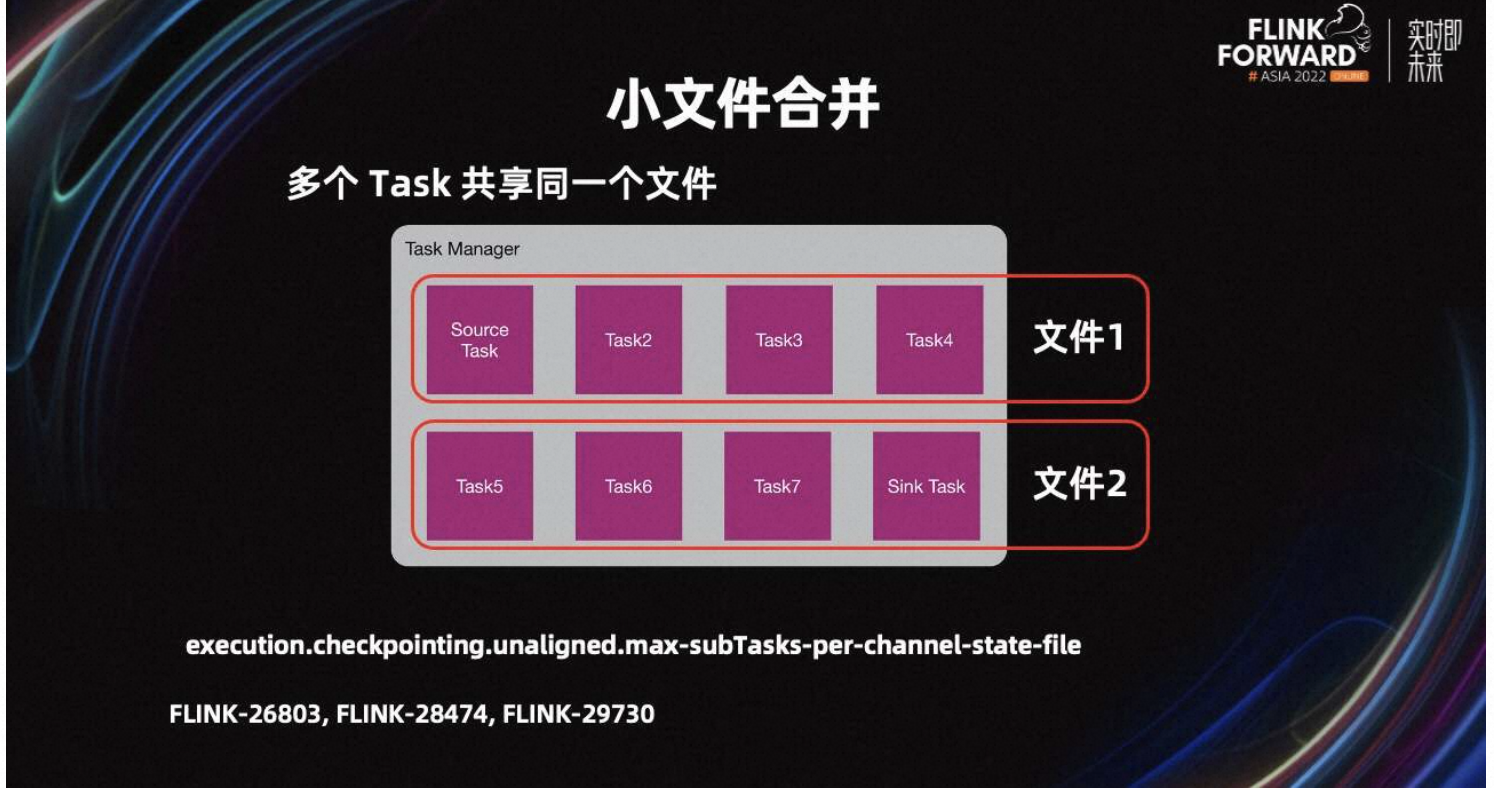
为了解决小文件的问题,我们在 Flink-26803 中提出了合并 UC 小文件的改进。优化思路是,同一个 TM 的多个 Task,不再单独创建文件,而是共享一个文件。
默认 execution.checkpointing.unaligned.max-subTasks-per-channel-state-file 是 5,即五个 Task 共享一个 UC 文件。UC 文件个数就会减少为原来的 1/5。五个 Task 只能串行写文件,来保证数据正确性,所以耗时会增加。
从生产经验来看,大量的 UC 小文件都会在 1M 以内,所以 20 个 Task 共享一个文件也是可以接受的。如果系统压力较小,且 Flink Job 更追求写效率,可以设置该参数为 1,表示 Task 不共享 UC 文件。
Flink 1.17 已经支持了 UC 小文件合并的 feature。
4.4 UC bugs
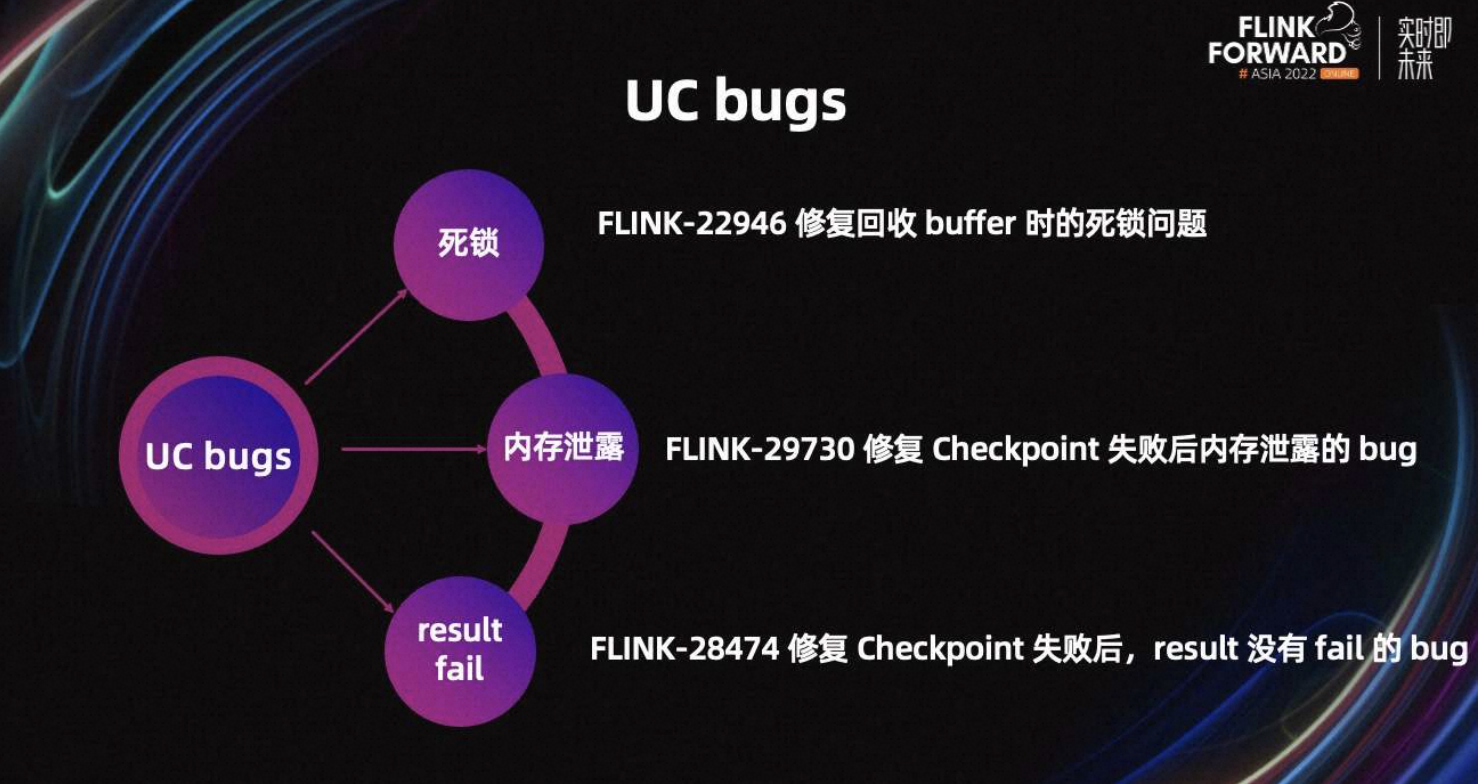
除此之外,我们还修复了一些 UC 的 bug,包括回收 Buffer 时的死锁问题,Checkpoint 失败后内存泄露的 bug、以及 Checkpoint 失败后 result 没有 fail 的 bug。
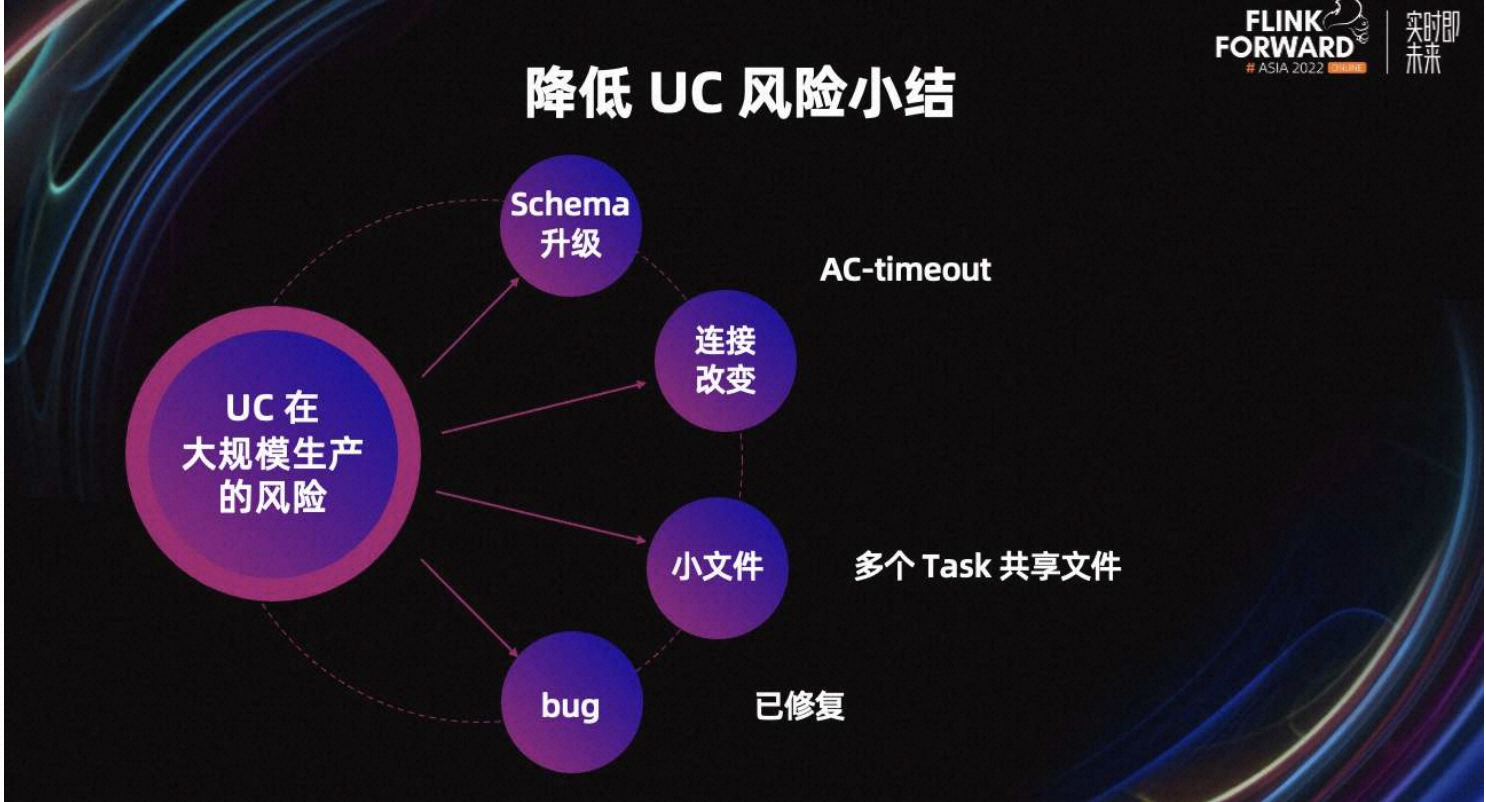
最后,对降低 UC 风险进行小结。回到最初的风险项,AC timeout 可以大大降低业务 schema 升级、连接改变以及小文件的风险。其次,大量作业同时反压,产生大量小文件的风险,通过 Task 共享文件来规避。UC 目前发现的多个 bug,已经全部回馈给了社区。
五、UC 在 Shopee 的生产实践和未来规划
5.1 UC 在 Shopee 的生产实践
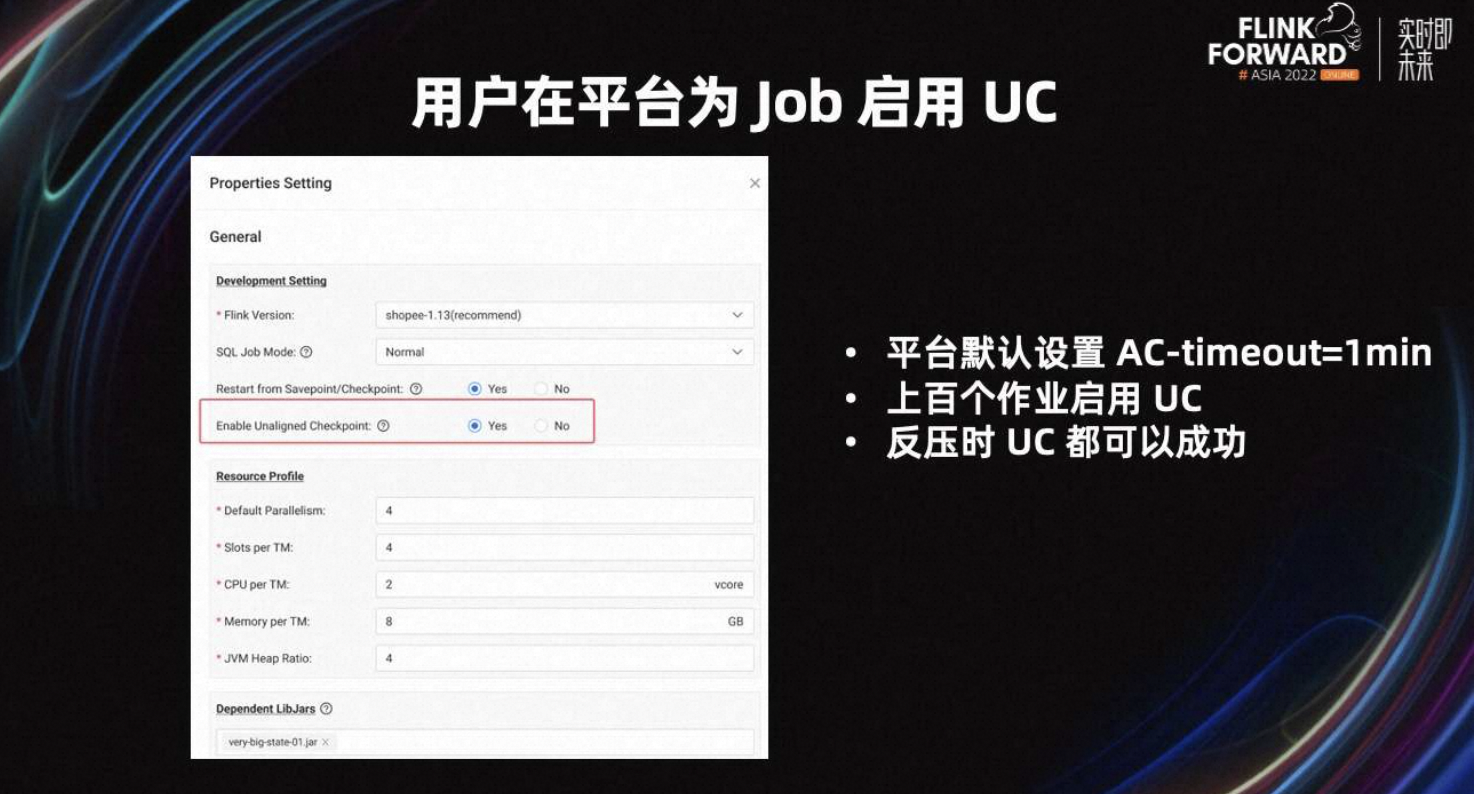
最后一部分,我会介绍 UC 在 Shopee 的生产实践和未来规划。目前,平台的开发页面已经增加了 UC 开关,用户可以选择开启。
为了规避 UC 带来的额外风险,Shopee 内部将 AC timeout 默认设置为一分钟。目前,平台已经有数百个作业开启了 UC,且这些任务表现良好,反压时 UC 都可以成功。
5.2 未来规划

未来,我们希望在开启 AC 的前提下,默认为所有作业开启 UC。其次,Shopee 内部版本对 Flink 的调度以及 network 内存模块有较大改动,可以精确计算 TM 需要的 network 内存,未来我们会在 Shopee Flink 内存模型上适配 overdraft-Buffer。
除此之外,我们也会尝试 UC 结合 Buffer debloating,减少 Checkpoint 大小。
更多内容

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:
0 元试用 实时计算 Flink 版(5000CU*小时,3 个月内)
了解活动详情:https://click.aliyun.com/m/1000372333/
