Flink-State/Checkpoint和Savepoint的详解
Flink特性之一:有状态计算
什么是状态计算:程序计算过程中,在程序内部产生的中间结果,并提供给后续的算子。
如图:
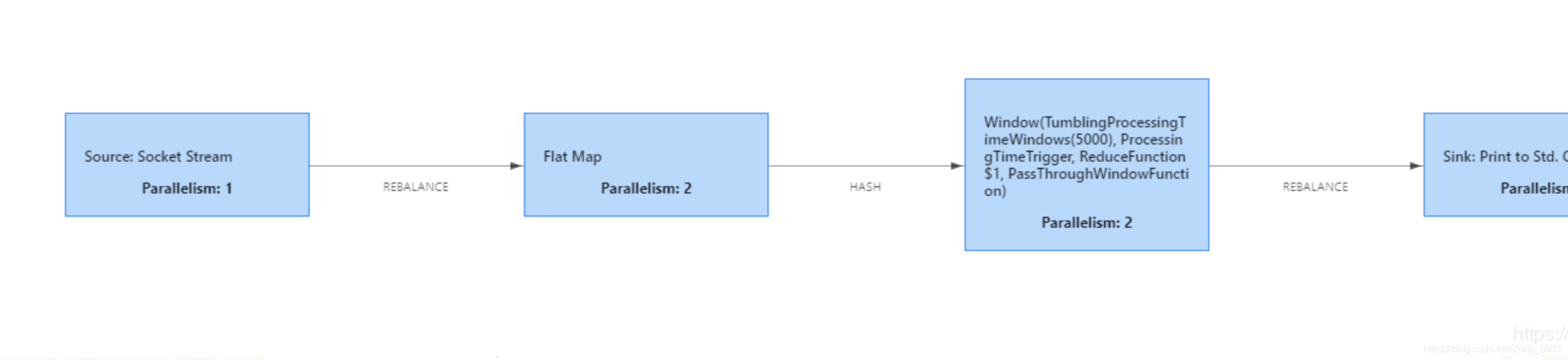
每个模块把自己的结果传递给下面的Task,也就是状态计算。
Flink-State划分
State粗分为两类:
- Keyed State:与key相关,作用于key对应的Function或者Operator上。
例如:ValueState,ListState,ReducingState,AggregatingState,MapState。 - Operator State:与并行的算子实例绑定。并且在并行度发生变化的时候(划分一个State),能够自动重新分配状态数据。
例如:ListState,BroadcastState。
注意:
这些State对象仅仅用于状态的改变,用于交互行为,如更新、删除、清空等操作。实际上,这些状态有3种存储方式。
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend
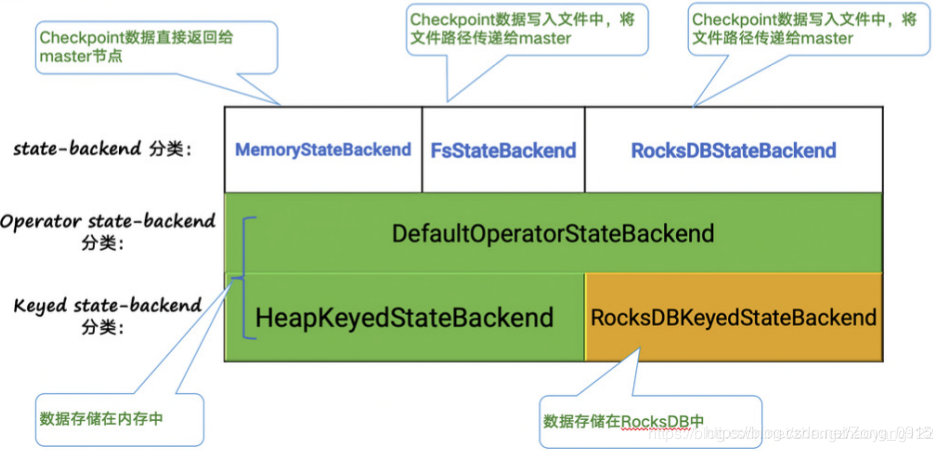
主要的区别:
MemoryStateBackend和FsStateBackend将数据存放于JavaHeap中。
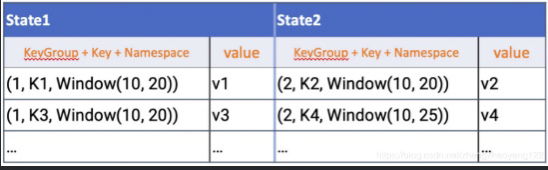
而第三种RocksDBStateBackend是存放于RocksDB上(一种内存磁盘混合的存储),并且每个State存储于单个Column Family中,并且用(key+keyGroup+namespace)作为key,如下图:
Flink-状态管理
Flink的状态管理有两种:
- 托管状态
- 原生状态
1.托管状态:Manager State。由Flink本身去管理,将状态数据转换为HashTables或者RocksDB对象进行存储,然后持久化于Checkpoint,用于异常恢复。
2.原生状态:Row State。算子自身管理数据结构,触发Checkpoint后,将数据转换为Bytes,然后存储在Checkpoint上,异常恢复时,由算子自身进行反序列化Bytes获得数据。
两者相同点:都是依赖于Checkpoint
不同点:
- 托管状态交给Flink RunTime完成。数据转为HashTables或者RocksDB对象。
- 原生状态:数据转换为Bytes字节。
Checkpoint
什么是Checkpoint?也就是所谓的检查点,是用来故障恢复用的一种机制。Spark也有Checkpoint。Flink与Spark一样,都是用Checkpoint来存储某一时间或者某一段时间的快照(snapshot),用于将任务恢复到指定的状态。
Checkpoint实现的核心就是barrier,Flink通过在数据集上间隔性的生成屏障barrier,并通过barrier将某段时间内的数据保存到Checkpoint中。
barrier屏障
barrier又可以分为单流以及并行。
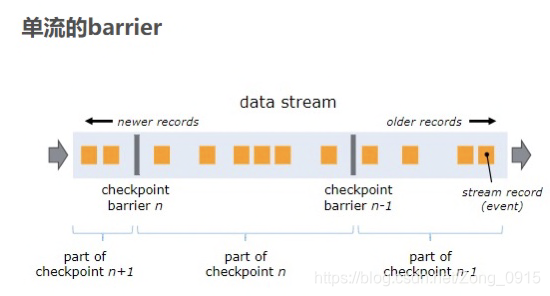
单流的barrier:
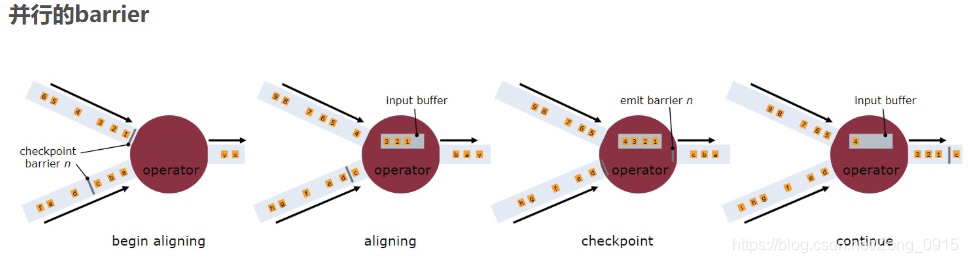
并行的barrier:
barrier的特点
- barrier作为数据流的一部分流入。
- barrier的占量非常的小。就是轻量级。
- barrier严格遵循间隔性的产生,不会出现乱序的情况。
- barrier还自带Id的,因此可以被唯一的识别。
barrier对齐机制
其实也可以理解为EXACTLY ONCE机制。
之前我并不了解什么是Exactly once。后来去百度了以下,意思是:保证一次性结果。那么barrier是如何保证的呢?
步骤:
- Flink根据配置,根据时间间隔进行Checkpoint,同时给多个DataSource插入barrier(因为可能源不止一个)。
- barrier会成为数据流的一部分,随着数据流向下游流动。(进入到DataStream部分)
- 因为可能存在多个输入端向同一个下游Operator中输入数据。那么,下游一旦接收到上游的其中一个barrier,则开始停止接收新的数据。(注意,此时可能已经收集新数据有一段时间了,那么此时这一端数据会作为缓存数据,暂且称他为buf),直到下游将所有上游同一时间点插入的barrier全部接收。
- 接收完所有同一时间点的barrier后,这些数据会成为snapshot,flink会将他发射出去,作为一次Checkpoint的数据。与此同时将第三步生成的buf数据,发射给下游,作为下游的输入(Outgoing Records)
Checkpoint详解
Flink的Checkpoint的核心算法叫做Chandy-Lamport。
大致过程如下:
- Checkpoint Coordinator发起Checkpoint机制。
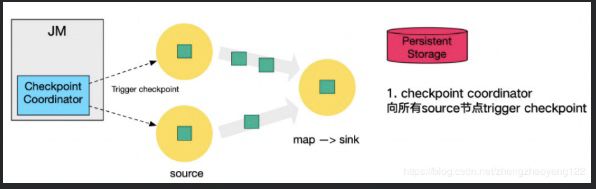
- 广播barrier并进行持久化。
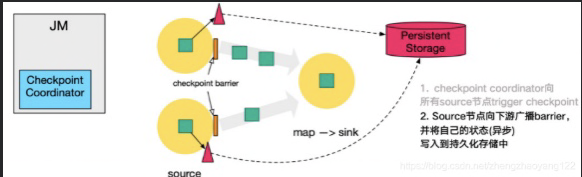
- 完成备份后,将State Handle通知给Coordinator(这次可能只是其中一部分,只是完成了一个Flink任务的某一个Task,还有别的Task也需要完成Checkpoint)
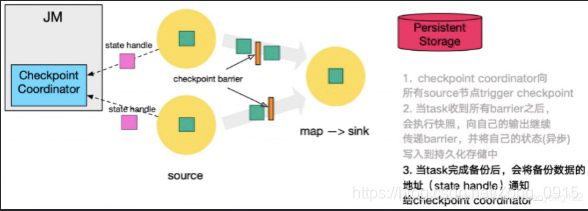
- 重复第三步,直到下游的Sink节点(一般也就是最后一个Task),收集上游两个input的barrier后,执行本地快照。并按照配置,将数据往对应的地方写入,如RocksDB。
这里是先写入红色的三角形(RocksDB),在写入第三方持久化数据库中(紫色三角形)
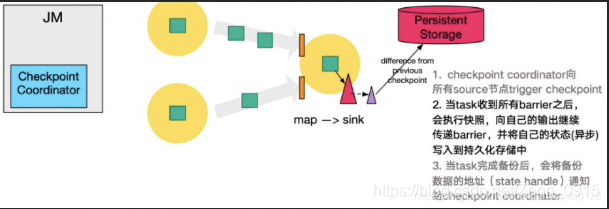
- sink节点在完成自己的Checkpoint后,将state Handle返回通知给Coordinator。
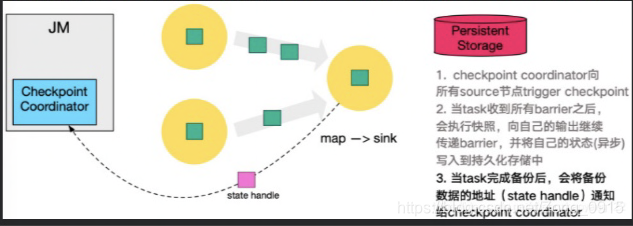
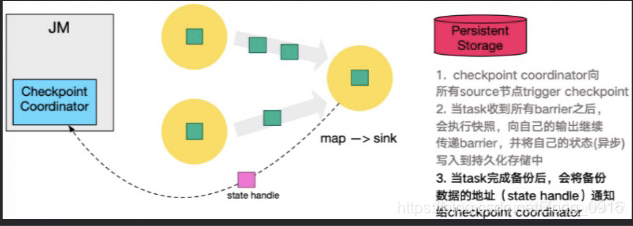
- 当Coordinator集齐所有task的stateHandle后,认为一次Checkpoint的全局完成了。向持久化存储的地址中备份一个Checkpoint meta文件。
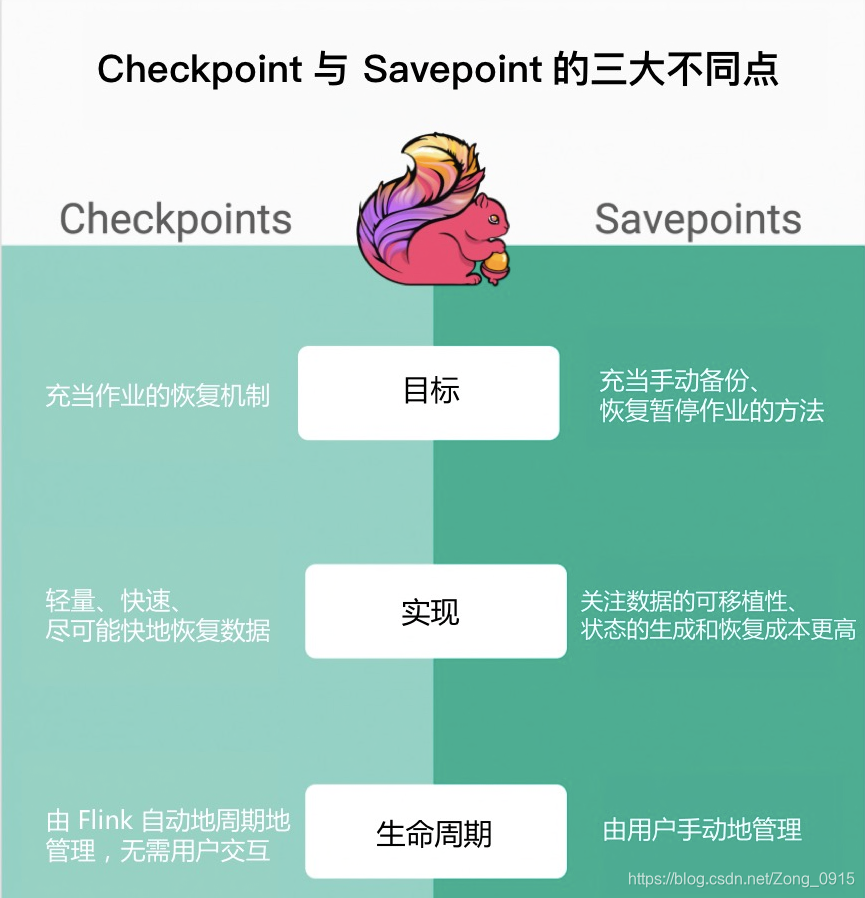
Checkpoint与Savepoint的对比
先来说一下什么是Savepoint
Savepoint:用于在某个时间点生成快照的一个功能。
生成快照包含的内容有:
- 目录:其中包含很多二进制文件(一般比较大),用于保存流状态。
- 元数据文件:存储数据的。
以下图是他们俩主要的不同: