一、什么是 checkpoint
上次发文,提到了 Flink 可以非常高效的进行有状态流的计算,通过使用 Flink 内置的 Keyed State 和 Operator State,保存每个算子的状态。
默认情况下,状态是存储在 JVM 的堆内存中,如果系统中某个环节发生了错误,宕机,这个时候所有的状态都会丢失,并且无法恢复,会导致整个系统的数据计算发生错误。
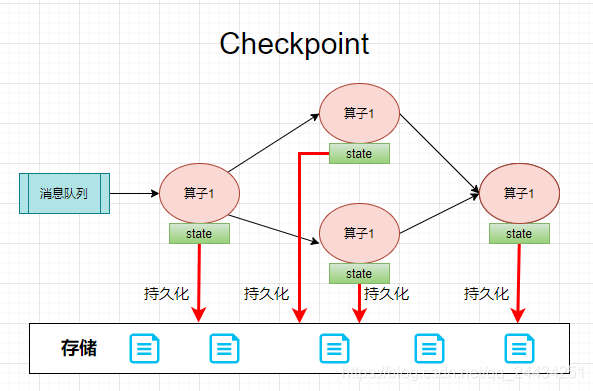
此时就需要 Checkpoint 来保障系统的容错。Checkpoint 过程,就是把算子的状态周期性持久化的过程。在系统出错后恢复时,就可以从 checkpoint 中恢复每个算子的状态,从上次消费的地方重新开始消费和计算。从而可以做到在高效进行计算的同时还可以保证数据不丢失,只计算一次。
二、任何条件下都能 Checkpoint 吗
答案是否,需要满足以下两个条件才能做 Checkpoint:
-
需要支持重放一定时间范围内数据的数据源,比如:kafka 。因为容错机制就是在任务失败后自动从最近一次成功的 checkpoint 处恢复任务,此时需要把任务失败前消费的数据再消费一遍。假设数据源不支持重放,那么数据还未写到存储中就丢了,任务恢复后,就再也无法重新消费这部分丢了的数据了。
-
需要一个存储来保存持久化的状态,如:Hdfs,本地文件。可以在任务失败后,从存储中恢复 checkpoint 数据。
三、程序中如何设置 checkpoint 参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每 60s 做一次 checkpoint
env.enableCheckpointing(60000);
// 高级配置:
// checkpoint 语义设置为 EXACTLY_ONCE,这是默认语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 两次 checkpoint 的间隔时间至少为 1 s,默认是 0,立即进行下一次 checkpoint
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);
// checkpoint 必须在 60s 内结束,否则被丢弃,默认是 10 分钟
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同一时间只能允许有一个 checkpoint
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 最多允许 checkpoint 失败 3 次
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(3);
// 当 Flink 任务取消时,保留外部保存的 checkpoint 信息
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 当有较新的 Savepoint 时,作业也会从 Checkpoint 处恢复
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
// 允许实验性的功能:非对齐的 checkpoint,以提升性能
env.getCheckpointConfig().enableUnalignedCheckpoints();
相关参数的文字描述:
- env.enableCheckpointing(60000),1 分钟触发一次 checkpoint;
- setCheckpointTimeout,checkpoint 超时时间,默认是 10 分钟超时,超过了超时时间就会被丢弃;
- setCheckpointingMode,设置 checkpoint 语义,可以设置为 EXACTLY_ONCE,表示既不重复消费也不丢数据;AT_LEAST_ONCE,表示至少消费一次,可能会重复消费;
- setMinPauseBetweenCheckpoints,两次 checkpoint 之间的间隔时间。假如设置每分钟进行一次 checkpoint,两次 checkpoint 间隔时间为 30s。假设某一次 checkpoint 耗时 40s,那么理论上20s 后就要进行一次 checkpoint,但是设置了两次 checkpoint 之间的间隔时间为 30s,所以是 30s 之后才会进行 checkpoint。
另外,如果配置了该参数,那么同时进行的 checkpoint 数量只能为 1; - enableExternalizedCheckpoints,Flink 任务取消后,外部 checkpoint 信息是否被清理。
• DELETE_ON_CANCELLATION,任务取消后,所有的 checkpoint 都将会被清理。只有在任务失败后,才会被保留;
• RETAIN_ON_CANCELLATION,任务取消后,所有的 checkpoint 都将会被保留,需要手工清理。 - setPreferCheckpointForRecovery,恢复任务时,是否从最近一个比较新的 savepoint 处恢复,默认是 false;
- enableUnalignedCheckpoints,是否开启试验性的非对齐的 checkpoint,可以在反压情况下极大减少 checkpoint 的次数.
四、追根究底,checkpoint 是如何实现的
Flink 的 checkpoint 是基于 Chandy-Lamport 算法,实现了一个分布式一致性的存储快照算法。
这里我们假设一个简单的场景来描述 checkpoint 具体过程是怎样的。
场景是:假如现在 kafka 只有一个分区,数据是每个 app 发过来的日志,我们统计每个 app 的 PV。
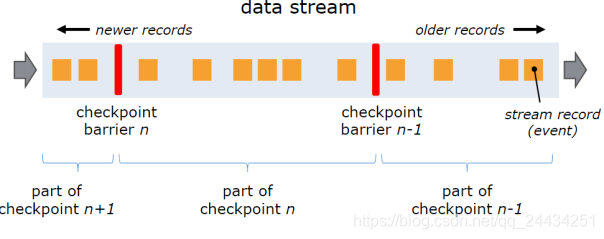
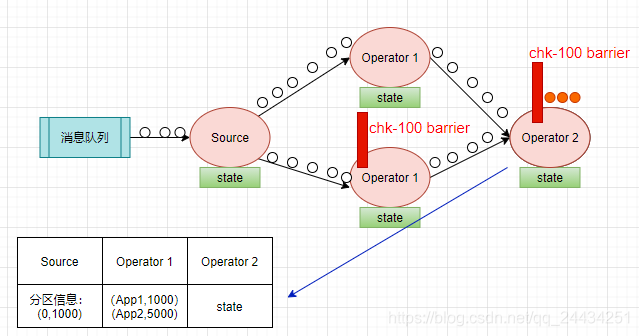
Flink 的 checkpoint coordinator (JobManager 的一部分)会周期性的在流事件中插入一个 barrier 事件(栅栏),用来隔离不同批次的事件,如下图红色的部分。
下图中有两个 barrier ,checkpoint barrier n-1 处的 barrier 是指 Job 从开始处理到 barrier n -1 所有的状态数据,checkpoint barrier n 处的 barrier 是指 Job 从开始处理到 barrier n 所有的状态数据。
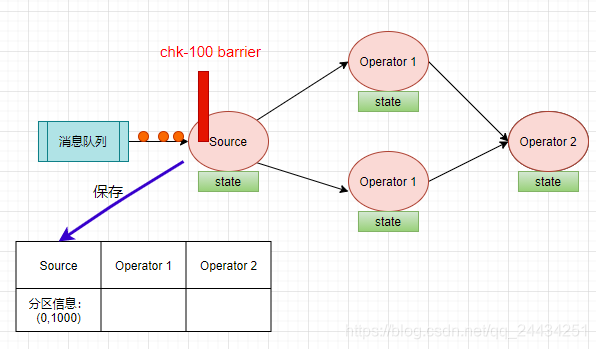
回到刚刚计算 PV 的场景,当 Source Task 接受到 JobManager 的编号为 chk-100 的 Checkpoint 触发请求后,发现自己恰好接收到了 offset 为(0,1000)【表示分区0,offset 为1000】处的数据,所以会往 offset 为(0,1000)数据之后,(0,1001)数据之前安插一个 barrier,然后自己开始做快照,把 offset (0,1000)保存到状态后端中,向 CheckpointCoordinator报告自己快照制作情况,同时向自身所有下游算子广播该barrier。如下图:
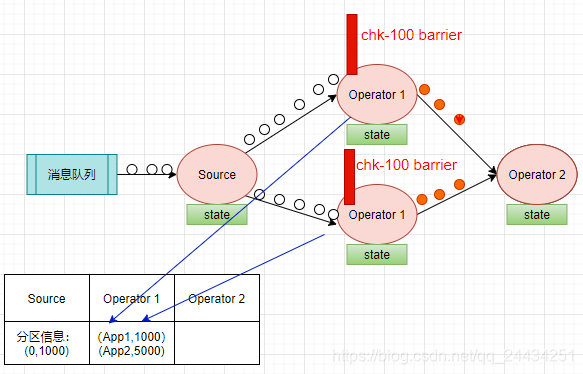
当下游计算的算子收到 barrier 后,会看是否收到了所有输入流的 barrier,我们现在只有一个分区,Source 算子只有一个实例,barrier 到了就是收到了所有的输入流的 barrier。
开始把本次的计算结果(app1,1000),(app2,5000)写到状态存储之中,向 CheckpointCoordinator 报告自己快照制作情况,同时向自身所有下游算子广播该barrier。
当 Operator 2 收到栅栏后,会触发自身进行快照,把自己当时的状态存储下来,向 CheckpointCoordinator 报告 自己快照制作情况。因为这是一个 sink ,状态存储成功后,意味着本次 checkpoint 也成功了。
Barrier 对齐
上面我们举的例子是 Source Task 实例只有一个的情况,在输入流的算子有多个实例的情况下,会有一个概念叫 Barrier 对齐。
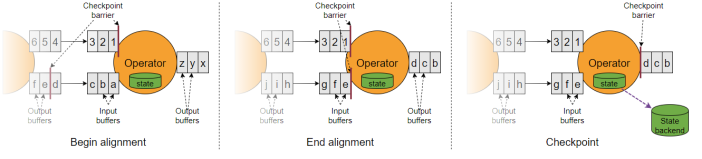
可以看上面的第一张图,有两个输入流,一个是上面的数字流,一个是下面的字母流。
数字流的 barrier 在 1 后面,字母流的 barrier 在 e 后面。
当上面的 barrier 到达 operator 之后,必须要等待下面的数字流的 barrier 也到达,此时数字流后面过来的数据会被缓存到缓冲区。
这就是 barrier 对齐的过程。
看上面的第二张图,当数字流的 barrier 到达后,意味着输入流的所有实例的 barrier 都到达了,此时开始处理
到第三张图的时候,处理完毕,自身做快照,然后把缓冲区的 pending 数据都发出去,把 checkpoint barrier n 继续往下发送。
五、Flink 1.11 对 Checkpoint 做了什么样的优化
从上图的对齐过程,我们可以发现,在进行对齐的过程中,算子是不会再接着处理数据了,一定要等到对齐动作完成之后,才能继续对齐。
也就是上图中的数字流的 barrier 到达之后,需要去等待字母流的 barrier 事件。
这其中会有一个阻塞的过程。在大多数情况下运行良好,然而当作业出现反压时,阻塞式的 Barrier 对齐反而会加剧作业的反压,甚至导致作业不稳定。
首先, Chandy-Lamport 分布式快照的结束依赖于 Marker 的流动,而反压则会限制 Marker 的流动,导致快照的完成时间变长甚至超时。无论是哪种情况,都会导致 Checkpoint 的时间点落后于实际数据流较多。
这时作业的计算进度是没有被持久化的,处于一个比较脆弱的状态,如果作业出于异常被动重启或者被用户主动重启,作业会回滚丢失一定的进度。如果 Checkpoint 连续超时且没有很好的监控,回滚丢失的进度可能高达一天以上,对于实时业务这通常是不可接受的。更糟糕的是,回滚后的作业落后的 Lag 更大,通常带来更大的反压,形成一个恶性循环。
所以在 Flink 1.11 版本中,引入了一个 Unaligned Checkpointing 的模块,主要功能是,在 barrier 到达之后,不必等待所有的输入流的 barrier,而是继续处理数据。
然后把第一次到达的 barrier 之后的所有数据也放到 checkpoint 里面,在下一次计算的时候,会合并上次保存的数据以及流入的数据后再计算。这样会大大加快 Barrier 流动的速度,降低 checkpoint 整体的时长。
六、最后总结一下,Checkpoint 的原理:
-
JobManager 端的 CheckPointCoordinator 会定期向所有 SourceTask 发送 CheckPointTrigger,Source Task 会在数据流中安插 Checkpoint barrier;
-
当 task 收到上游所有实例的 barrier 后,向自己的下游继续传递 barrier,然后自身同步进行快照,并将自己的状态异步写入到持久化存储中
• 如果是增量 Checkpoint,则只是把最新的一部分更新写入到外部持久化存储中
• 为了下游尽快进行 Checkpoint,所以 task 会先发送 barrier 到下游,自身再同步进行快照; -
当 task 将状态信息完成备份后,会将备份数据的地址(state handle)通知给 JobManager 的CheckPointCoordinator,如果 Checkpoint 的持续时长超过了 Checkpoint 设定的超时时间CheckPointCoordinator 还没有收集完所有的 State Handle,CheckPointCoordinator 就会认为本次 Checkpoint 失败,会把这次 Checkpoint 产生的所有状态数据全部删除;
-
如果 CheckPointCoordinator 收集完所有算子的 State Handle,CheckPointCoordinator 会把整个 StateHandle 封装成 completed Checkpoint Meta,写入到外部存储中,Checkpoint 结束;