checkpoint是Flink容错的核心机制。它可以定期地将各个Operator处理的数据进行快照存储( Snapshot )。如果Flink程序出现宕机,可以重新从这些快照中恢复数据。
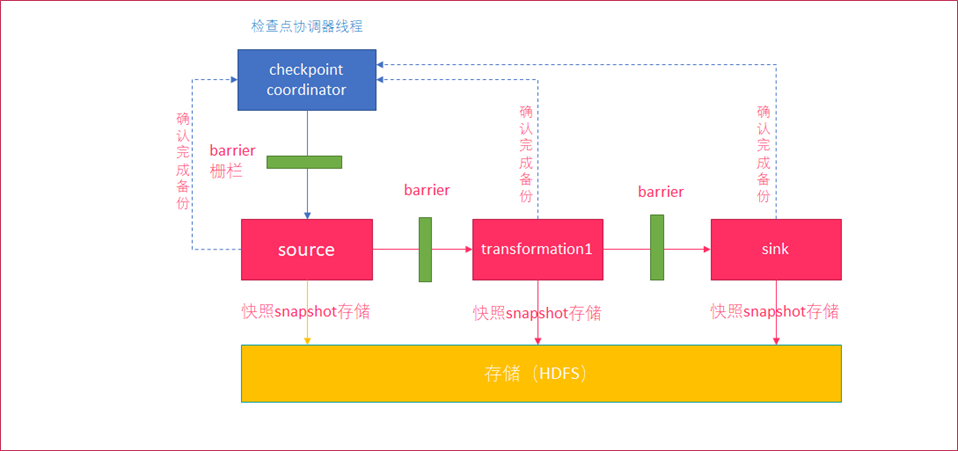
1. checkpoint coordinator(协调器)线程周期生成 barrier (栅栏),发送给每一个source
2. source将当前的状态进行snapshot(可以保存到HDFS)
3. source向coordinator确认snapshot已经完成
4. source继续向下游transformation operator发送 barrier
5. transformation operator重复source的操作,直到sink operator向协调器确认snapshot完成
6. coordinator确认完成本周期的snapshot
代码设置示例:
| // 5秒启动一次checkpoint env.enableCheckpointing(5000) // 设置checkpoint只checkpoint一次 env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) // 设置两次checkpoint的最小时间间隔 env.getCheckpointConfig.setMinPauseBetweenCheckpoints(1000) // checkpoint超时的时长 env.getCheckpointConfig.setCheckpointTimeout(60000) // 允许的最大checkpoint并行度 env.getCheckpointConfig.setMaxConcurrentCheckpoints(1) // 当程序关闭的时,触发额外的checkpoint env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpoin tCleanup.RETAIN_ON_CANCELLATION) // 设置checkpoint的地址 env.setStateBackend(new FsStateBackend("hdfs://cdh1:8020/flink-checkpoint/")) |
|