目录
为什么需要State
与批计算相比,State是流计算特有的,批计算没有failover机制,要么成功,要么重新计算。流计算在 大多数场景 下是增量计算,数据逐条处理(大多数场景),每次计算是在上一次计算结果之上进行处理的,这样的机制势必要将上一次的计算结果进行存储(生产模式要持久化),另外由于 机器,网络,脏数据等原因导致的程序错误,在重启job时候需要从成功的检查点(checkpoint,后面篇章会专门介绍)进行state的恢复。增量计算,Failover这些机制都需要state的支撑。
State 实现
Apache Flink内部有四种state的存储实现,具体如下:
- 基于内存的HeapStateBackend - 在debug模式使用,不 建议在生产模式下应用;
- 基于HDFS的FsStateBackend - 分布式文件持久化,每次读写都产生网络IO,整体性能不佳;
- 基于RocksDB的RocksDBStateBackend - 本地文件+异步HDFS持久化;
- 还有一个是基于Niagara(Alibaba内部实现)NiagaraStateBackend - 分布式持久化- 在Alibaba生产环境应用;
一、状态类型
1.基本类型划分
在Flink中,按照基本类型,对State做了以下两类的划分:
a.Keyed State,和Key有关的状态类型,它只能被基于KeyedStream之上的操作,方法所使用。我们可以从逻辑上理解这种状态是一个并行度操作实例和一种Key的对应, <parallel-operator-instance, key>。
b.Operator State(或者non-keyed state),它是和Key无关的一种状态类型。相应地我们从逻辑上去理解这个概念,它相当于一个并行度实例,对应一份状态数据。因为这里没有涉及Key的概念,所以在并行度(扩/缩容)发生变化的时候,这里会有状态数据的重分布的处理。
2.组织形式划分
但是在这里还有一种按照组织形式的划分,也可以理解为按照runtime层面的划分,又可以分为一下两类:
a.Managed State,这类State的内部结构完全由Flink runtime内部来控制,包括如何将它们编码写入到checkpoint中等等。
b.Raw State,这类State就比较显得灵活一些,它们被保留在操作运行实例内部的数据结构中。从Flink系统角度来观察,在checkpoint时,它只知道的是这些状态数据是以连续字节的形式被写入checkpoint中。等待进行状态恢复时,又从字节数据反序列化为状态对象。
Managed State可以在所有的data stream相关方法中被使用,官方也是推荐优先使用这类State,因为它能被Flink runtime内部做自动重分布而且能被更好地进行内存管理。
3. 举例:托管的Keyed State
ValueState<T> getState(ValueStateDescriptor<T>)ReducingState<T> getReducingState(ReducingStateDescriptor<T>)ListState<T> getListState(ListStateDescriptor<T>)AggregatingState<IN, OUT> getAggregatingState(AggregatingState<IN, OUT>)FoldingState<T, ACC> getFoldingState(FoldingStateDescriptor<T, ACC>)MapState<UK, UV> getMapState(MapStateDescriptor<UK, UV>)
二、State checkpoint
State操作都是在内存中,如果遇到错误,会导致数据丢失,任务失败,可以通过代码或者配置文件的方式,为State配置不同的Checkpoint方式。
1.Filesystem State Backend
一般常见的都是比较简单的基于内存的state backend,在实际生产中是不太可行的。因此一般会使用filesystem或者rocksdb的state backend。我们先讲一下基于filesystem的state backend。
基于内存的state backend实现为MemoryStateBackend,基于文件系统的state backend的实现为FsStateBackend。FsStateBackend有一个策略,当状态的大小小于1MB(可配置,最大1MB)时,会把状态数据直接存储在meta data file中,避免出现很小的状态文件。
FsStateBackend另外一个成员变量就是basePath,即checkpoint的路径。实际做checkpoint时,生成的路径为:<base-path>/<job-id>/chk-<checkpoint-id>/。
而且filesystem推荐使用分布式文件系统,如HDFS等,这样在fail over时可以恢复,如果是本地的filesystem,那恢复的时候是会有问题的。
回到StreamTask,在做checkpoint的时候,是通过CheckpointStateOutputStream写状态的,FsStateBack会使用FsCheckpointStreamFactory,然后通过FsCheckpointStateOutputStream去写具体的状态,这个实现也比较简单,就是一个带buffer的写文件系统操作。最后向上层返回的StreamStateHandle,视状态的大小,如果状态特别小,则会直接返回带状态数据的ByteStreamStateHandle,否则会返回FileStateHandle,这个state handle包含了状态文件名和大小。
需要注意的是,虽然checkpoint是写入到文件系统中,但是基于FsStateBackend创建的keyed state backend,仍然是HeapKeyedStateBackend,也就是说,keyed state的读写仍然是会在内存中的,只有在做checkpoint的时候才会持久化到文件系统中。
2.RocksDB State Backend
RocksDB跟上面的都略有不同,它会在本地文件系统中维护状态,KeyedStateBackend等会直接写入本地rocksdb中。同时它需要配置一个远端的filesystem uri(一般是HDFS),在做checkpoint的时候,会把本地的数据直接复制到filesystem中。fail over的时候从filesystem中恢复到本地。
从RocksDBStateBackend创建出来的RocksDBKeyedStateBackend,更新的时候会直接以key + namespace作为key,然后把具体的值更新到rocksdb中。
如果是ReducingState,则在add的时候,会先从rocksdb中读取已有的值,然后根据用户的reduce function进行reduce,再把新值写入rocksdb。
做checkpoint的时候,会首先在本地对rockdb做checkpoint(rocksdb自带的checkpoint功能),这一步是同步的。然后将checkpoint异步复制到远程文件系统中。最后返回RocksDBStateHandle。
RocksDB克服了HeapKeyedStateBackend受内存限制的缺点,同时又能够持久化到远端文件系统中,比较适合在生产中使用。
3.Queryable State
Queryable State,顾名思义,就是可查询的状态,表示这个状态,在流计算的过程中就可以被查询,而不像其他流计算框架,需要存储到外部系统中才能被查询。目前可查询的state主要针对partitionable state,如keyed state等。
简单来说,当用户在job中定义了queryable state之后,就可以在外部,通过QueryableStateClient,通过job id, state name, key来查询所对应的状态的实时的值。
queryable state目前支持两种方法来定义:
- 通过
KeyedStream.asQueryableState方法,生成一个QueryableStream,需要注意的是,这个stream类似于一个sink,是不能再做transform的。 实现上,生成QueryableStream就是为当前stream加上一个operator:QueryableAppendingStateOperator,它的processElement方法,每来一个元素,就会调用state.add去更新状态。因此这种方式有一个限制,只能使用ValueDescriptor, FoldingStateDescriptor或者ReducingStateDescriptor,而不能是ListStateDescriptor,因为它可能会无限增长导致OOM。此外,由于不能在stream后面再做transform,也是有一些限制。 -
通过managed keyed state。
ValueStateDescriptor<Tuple2<Long, Long>> descriptor = new ValueStateDescriptor<>( "average", // the state name TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}), Tuple2.of(0L, 0L)); descriptor.setQueryable("query-name"); // queryable state name
这个只需要将具体的state descriptor标识为queryable即可,这意味着可以将一个pipeline中间的operator的state标识为可查询的。
首先根据state descriptor的配置,会在具体的TaskManager中创建一个KvStateServer,用于state查询,它就是一个简单的netty server,通过KvStateServerHandler来处理请求,查询state value并返回。
但是一个partitionable state,可能存在于多个TaskManager中,因此需要有一个路由机制,当QueryableStateClient给定一个query name和key时,要能够知道具体去哪个TaskManager中查询。
为了做到这点,在Job的ExecutionGraph(JobMaster)上会有一个用于定位KvStateServer的KvStateLocationRegistry,当在TaskManager中注册了一个queryable KvStateServer时,就会调用JobMaster.notifyKvStateRegistered,通JobMaster。
三、State 并行重分配
State分为Operator State和Keyed State,在并行度改变的时候,会遵循不同的规则,调整State,在调整的过程中,尽量保证State数据是在本地的,但是某些情况下会导致State数据在全局环境中,进行重新Shuffle导致性能损耗。
1. Operator State
我们选取Apache Flink中某个具体Connector实现实例进行介绍,以MetaQ为例,MetaQ以topic方式订阅数据,每个topic会有N>0个分区,以上图为例,加上我们订阅的MetaQ的topic有5个分区,那么当我们source由1个并发调整为2个并发时候,State是怎么恢复的呢?state 恢复的方式与Source中OperatorState的存储结构有必然关系,我们先看MetaQSource的实现是如何存储State的。
下图为MetaQSource的一部分代码,为了实现State的错误恢复, 实现了ListCheckpointed<T extends Serializable>接口(上文提及),其中的T是Tuple2<InputSplit,Long>,我们在看ListCheckpointed接口的内部定义如下:
public interface ListCheckpointed<T extends Serializable>; {
//Operator state中使用,checkpoint时进行调用,可以讲缓存数据存储进托管的State进行备份
List<T> snapshotState(long var1, long var3) throws Exception;
//发生错误时,恢复数据调用的方法
void restoreState(List<T> var1) throws Exception;
} snapshotState方法的返回值是一个List<T>,T是Tuple2<InputSplit,Long>,这个类型说明state的存储是一个包含partiton和offset信息的列表,InputSplit代表一个分区,Long代表当前partition读取的offset。InputSplit我们可以理解为是一个Partition索引,有了这个数据结构我们在看看上面图所示的case是如何工作的?当Source的并行度是1的时候,所有打partition数据都在同一个线程中读取,所有partition的state也在同一个state中维护,State存储信息格式如下: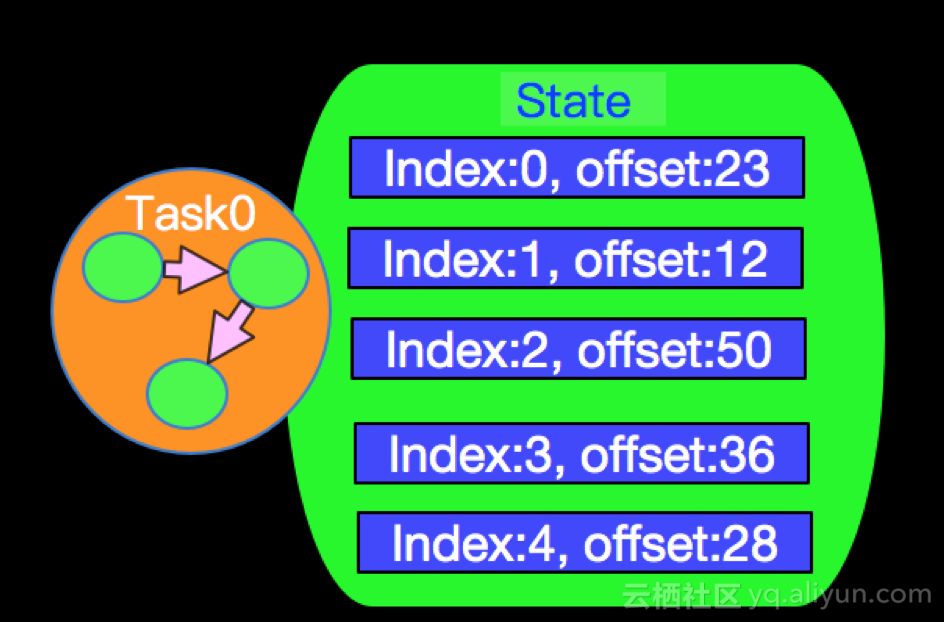

如果我们现在将并发调整为2,那么我们5个分区的State将会在2个独立的任务(线程)中进行维护,在内部实现中我们有如下算法进行分配每个Task所处理和维护partition的State信息,如下:
List<Integer> assignedPartitions = new LinkedList<>();
for (int i = 0; i < partitions; i++) {
if (i % consumerCount == consumerIndex) {
assignedPartitions.add(i);
}
}这个求mod的算法,决定了每个并发所处理和维护partition的State信息,针对我们当前的case具体的存储情况如下:

Source的扩容(并发数)是否可以超过Source物理存储的partition数量呢?答案是否定的,不能。目前Apache Flink的做法是提前报错,即使不报错也是资源的浪费,因为超过partition数量的并发永远分配不到待管理的partition。
2. Keyed State
因为数据流中key数据可能会非常多,所以在将key划分到某个并行实例的时候,并不是以key为单位进行划分,而是按照keyGroup为单位,keyGroup是一组Key的聚合,Key-Groups 是Apache Flink中对keyed state按照key进行分组的方式,每个key-group中会包含N>0个key,一个key-group是State分配的原子单位。
key-group数量:一般程序并行度不能超过 key-group 的个数,所以一般key-group个数和程序并行度相同。
如何划分:key.hashCode值与maxParallelism个数进行取余划分,注意,是按照maxParallelism进行划分,也就是如果程序在执行过程中修改了maxParallelism,将会打算所有的key和group的划分,而修改parallelism只会导致重新key-groups的重新分布,而且重分布的时候,会尽量划分到本地已有的数据,划分举例如下。

假设我们有2个并发实例,首先会计算,每个实例至少分配的key-group个数,然后不能整除的部分N个,平均分给前N个实例。最终每个Operator实例管理的Key-Groups会在GroupRange中表示,本质是一个区间值;下面我们就上图的case,说明一下如何进行分配以及扩容后如何重新分配。
假设上面的Stateful Operation节点的最大并行度maxParallelism的值是10,也就是我们一共有10个Key-Group,当我们并发是2的时候和并发是3的时候分配的情况如下图:

总结:
1.按照maxParallelism划分key-groups
2.按照Parallelism划分key-groups分布
3.遇到重新分布的情况,重新划分key-group即可
四、State 结合 Process Function使用
有时候需要对数据流中的数据,按照key进行数据统计和处理工作,一般会采用keyBy + windows的方式,但是,如果windows的数量过多可能会引发性能问题,在这这种情况下,可以更换process function和State的方式,使用Process Function处理每一个key化后的元素,并利用onTimer回调用函数,来触发下一次的数据处理(Windows),在其间所有的数据通过托管的State进行数据的存储任务,并可讲数据保存到db或者分布式FS。
KeyBy + Windows ——> Process function和State
引用文章链接:
金竹:https://yq.aliyun.com/articles/667562?spm=a2c4e.11163080.searchblog.9.7de32ec1f5Y0Dp
codyinnowhere:https://yq.aliyun.com/articles/225623