>Spider
之前提到一个完整的Spider应该有两部分功能:抓取网页数据+解析、提取数据。
>上一篇<利用python标准库中的“urllib+正则表达式”的方式提取了B站首页的部分数据,这一篇将利用上一篇介绍过的requests以及BeautifulSoup的方式进行另一个爬虫的实现。
>环境搭建
由于lxml远快与BeautifulSoup,加之后者似乎已经停更了,但由于BS相当盛行,有大量教程依赖于BS,所以就算lxml可以替代BeautifulSoup,但BeautifulSoup还是很有学习和使用的价值的。另外,BeautifulSoup也可以依赖于使用lxml作为引擎进行解析,所以此处一并安装lxml。
安装方法:
pip install beautifulsoup4 pip install requests pip install lxml
>爬虫实现
任意打开一个歌单:http://music.163.com/#/playlist?id=2208261223,先随便抓取一下,发现抓下来的内容实际上包含了大量JS脚本,整个页面是异步动态加载的,因此直接抓取这个URL并没有价值。(并不是完全没有价值,实际上可以用Phantomjs来模拟浏览器并执行JS脚本来获取数据)
按F12打开浏览器控制台,找到下面这个请求playlist?id=2208261223,发现这个请求的返回结果中有我们需要的结果:
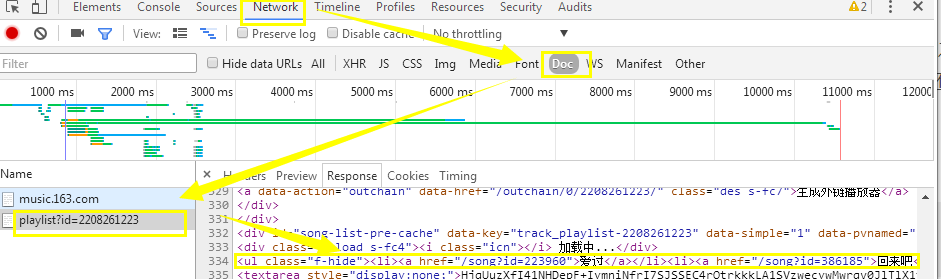
查看这个请求的Headers和实际URL:http://music.163.com/playlist?id=2208261223。虽然这个URL和上面那个URL只有一个#之差,然而内容确是天差地别的。

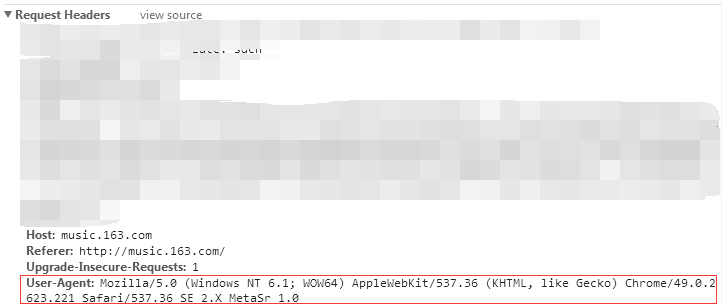
因此,我们将模拟相应的Headers,向这个URL直接请求数据:
nn163_cloud_url = 'http://music.163.com/playlist?id=2208261223'
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
request = urllib2.Request(nn163_cloud_url)
request.add_header('User-Agent', user_agent)
res = urllib2.urlopen(request, timeout=10)
root = re.search(r'<ul class="f-hide">(.*?)</ul>', res.read(), re.S|re.M).group(1)
musics = re.findall(r'<a href="/song.*?">(.*?)</a>', root, re.S|re.M)
for i in musics:
print i
这里依旧采用的是urllib2+regex的方式提取了信息,如果采用requests+BeautifulSoup,我们能够更方便的提取信息:
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
}
nn163_cloud_url = 'http://music.163.com/playlist?id=2208261223'
s = requests.session()
bs = BeautifulSoup(s.get(nn163_cloud_url, headers=headers).content, "lxml")
for i in bs.ul.children:
print i.string
是不是更加简洁?
>帮助文档