FastDVDnet: Towards Real-Time Deep Video Denoising Without Flow Estimation
原文: https://ieeexplore.ieee.org/document/9156652
由于视频有着较强的时间相关性,那么一个好的视频去噪算法必将要充分利用这一特点。利用时间相关性主要体现为两个方面:
- 对于给定的patch,不仅要在同一帧的相邻区域搜索像素的patch,也要在时间相近的frame上进行搜索;
- 使用相邻时间的frame还可以有效减少flockering,因为每一帧之间的残余就会是相关的。
为了解决motion带来的对齐困难问题,DVDNet中使用光流进行了显式的估计,但是光流的计算是比较耗时的,即便是快速算法也是如此。对于encoder-decoder结构的U-Net,其本身具有在感受也范围内对齐的功能,因此,在FastDVDNet中采用了这种做法,也就提高了性能。
摘要
FastDVDNet:a state-of-the-art video denoising algorithm based on a convolutional neural network architecture.
优势1. handle a wide range of noise levels with a single network model
优势2. avoid using a costly motion compensation stage
优势3. The combination between its denoising performance and lower computational load
优势4:outputs high quality denoised videos,featuring very fast running times
介绍
- 图像去噪
一直备受欢迎,最好性能的方法还是基于深度学习的方法。这些算法执行受一定条件约束:
(1)需要具备特定形势的先验;
(2)或者针对不同级别的噪声设定不同的权重。
另一种是基于CNN的网络架构,这种架构仅使用一次训练模型可以去除多种级别噪声。目前,DnCNN是一种端到端的可训练深度CNN,其中最主要的特征是其使用了residual learning,即是用于估计图像中存在的噪声而不是进行去噪。
- 视频去噪
目前大部分方法是patch-based的,例如BM3D/V-BM4D/VNLB等等。如今,最先进的技术由 DVDnet、VNLnet 和 VNLB 定义。 VNLB 和 VNLnet 对较小的噪声值表现出最佳性能,而 DVDnet 对较大的噪声值产生更好的结果。 DVDnet 和 VNLnet 的推理时间都比 VNLB 快得多。
FastDVDnet
引入
影响感知去噪结果的关键点:temporal coherence and flickering removal are crucial aspects 时间一致性和消除闪烁
因此,要充分用相邻帧之间的信息进行去噪。之前基于深度学习的算法没能利用这一点,因此,成功算法主要
通过这两点加强时间相关性temporal coherence :
(1) the extension of search regions from spatial neighborhoods to volumetric neighborhoods
将搜索域 从最初的空间领域 扩展到体积域(时空领域)
when denoising a given pixel (or patch), the algorithm is going to look for similar pixels (patches) not only in the reference frame, but also in adjacent frames of the sequence.
这样的优势(1)增加了可用的额外信息用于参考帧的去噪 (2)使用时间域上相邻帧减少闪烁,因为每帧的残差都是相关的
(2)the use of motion estimation
利用运动估计
视频沿motion trajectories 运动轨迹具有很强的temporal redundancy 时间冗余。这一事实应该有助于对图像去噪的视频进行去噪。然而,时间维度中的这些附加信息也会产生额外的复杂性,这可能难以解决。在这种情况下,运动估计和/或补偿已被用于许多视频去噪算法中,以帮助提高去噪性能和时间一致性[22、38DVDnet、2、25、4]。
网络架构
我们将这两个元素合并incorporated集成到我们的架构中,然而,算法不包括explicit 明确的运动估计/补偿阶段。处理对象运动的能力固有地嵌入到所提出的架构中。事实上,我们的架构由许多修改后的 U-Net [29] 块组成。
多尺度、类似 U-Net 的架构已被证明具有学习错位的能力 [42, 12]。我们的级联架构进一步提高了这种处理运动的能力。与 [38] 相比,我们的架构是在没有光流对齐的情况下端到端训练的,这避免了由于错误流导致的失真和伪影。因此,我们能够在不牺牲性能的情况下消除昂贵的专用运动补偿阶段。这导致运行时间显着减少

采用two-stage两级架构,由不同的空间/时间Denoising block去噪块构成。block构成类似,是由修改后的U-net模型组成。
五个连续的帧用于对中间帧进行去噪。这些帧被视为连续帧的三元组并输入到Fisrt Denoising,第一阶段的三个block共享相同的权重(内存减少利于训练);一阶段输出作为二阶段的输入,送入Second Denoising,输出对中心帧t的去噪结果。
与[44,14]类似,
noise map噪声图也被包括在内作为输入,它允许处理空间变化的噪声 [37]。具体来说,噪声图是一个单独的输入,它向网络提供有关输入处噪声分布的信息。该信息被编码为该噪声的预期每像素标准偏差。例如,在对高斯噪声进行去噪时,噪声图将是恒定的;在去噪泊松噪声时,噪声图将取决于图像的强度。事实上,噪声图可以用作用户输入参数来控制噪声去除与细节保留之间的权衡(参见例如 [37] 中的在线演示)。在其他情况下,例如 JPEG 去噪,可以通过额外的 CNN [15] 来估计噪声图。噪声图的使用已被证明可以提高去噪性能,特别是在处理空间变化噪声时 [3]。与其他去噪算法相反,我们的去噪器除了图像序列和输入噪声的估计外,不接受其他参数作为输入
请注意,本文介绍的实验集中在加性高斯白噪声 (AWGN) 的情况下。然而,该算法可以扩展到其他类型的噪声,例如空间变化的噪声(例如Poissonian 泊松噪声)。
去噪块设计Denoising block
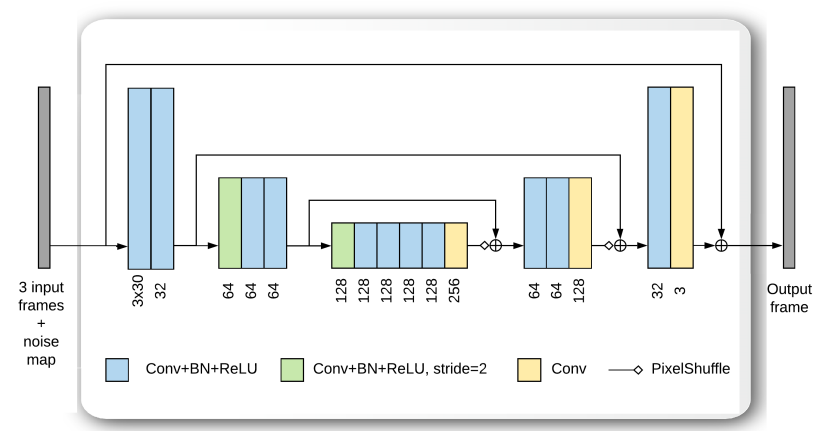
U-Nets are essentially a multi-scale encoder-decoder architecture, with skip-connections [16] that forward the output of each one of the encoder layers directly to the input of the corresponding decoder layers.
U-Net 本质上是一种多尺度编码器-解码器架构,具有跳跃连接 [16],可将每个编码器层的输出直接转发到相应解码器层的输入。
本文与U-net差异:
- 输入调整为三个帧和一个noise map
- 解码器中上采样使用的是PixelShuffle layer [34] ,帮助reduce gridding artifacts伪影
- The merging of the features of the encoder with those of the decoder is done with a pixel-wise addition operation instead of a channel-wise concatenation. This results in a reduction of memory requirements
编码器和解码器的特征合并是像素级的加法实现,而不是通道级别的实现,这样减少内存需求
- 块实现
residual learning残差学习——在中心噪声输入帧和输出之间有一个残差连接——据观察,这可以简化训练过程 [37]
The design characteristics of the denoising blocks :在性能和运行时间上做了折中
- 去噪块由D=16个卷积层Conv组成
- 大多数层中,卷积层输出之后是逐点ReLU激活函数
- 除最后一层外,批量归一化BN位于卷积层和ReLu层之间
细节讨论
FastDVDnet 中避免了显式流量估计。然而,为了保持性能,我们需要引入一些技术来处理运动并有效地利用时间信息。
两步架构设计原因
若该two-stage结构对于去噪任务是冗余的,那么,将two-stage结构改为single-stage后,模型性能应几乎保持不变。假设采用下图所示single-stage结构,即五帧图像连接在一起作为一个Block模块的输入,这无疑在很大程度上减少学习参数。
与 DVDnet 和 ViDeNN 类似,FastDVDnet 具有两步级联架构。目的是为了:
- 有效利用
the temporal neighbors的信息 - 加强输出帧中剩余噪声的时间相关性
新的架构设计如图:
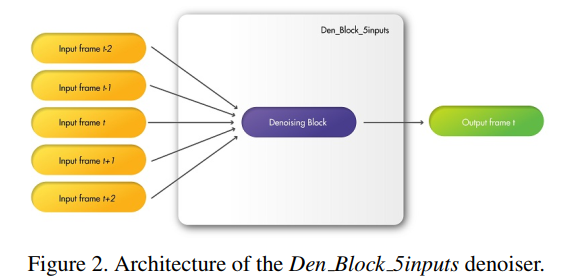
新的模块会考虑相同数量的相邻时间帧(5帧输入),并同样步骤处理信息,根据实验,输入的结果显示时间伪影(闪烁)急剧增加。尽管它是一个多尺度架构,但 Den Block 5inputs 不能像 FastDVDnet 的两步架构那样处理序列中对象的运动。总体而言,两步架构相对于一步架构显示出优越的性能。
设计多规模架构和端到端设计的原因
Multi-scale architecture and end-to-end training
encoder-decoder结构是一种典型的multi-scale结构,可以在不同的scale提取图像的特征,增大图像感受野。在近年来对于图像去噪的研究中,encoder-decoder结构的模型也占了多数,但是也不乏有single-scale结构的网络,如经典的DnCNN也有着很好的性能。
实验设计:将模型的Denoising block更改的DVDnet的Denoising block,这导致了一个两步级联架构,具有单尺度去噪块(因为是CONV+BN+RELU架构),端到端训练,并且在场景中没有运动补偿。在我们的测试中,观察到多尺度去噪块的使用显着改善了去噪结果。
我们还尝试在 FastDVDnet 的每个步骤中分别训练多尺度去噪块——就像在 DVDnet 中所做的那样。尽管相对于上述单尺度去噪块的情况,这种情况下的结果肯定有所改善,但输出中仍然存在明显的闪烁。从这种单独的训练切换到端到端训练有助于显着减少时间伪影
运动信息的处理
通过避免使用光流进行运动补偿还有一个额外的好处:由于显式运动估计的算法通常在一些具有挑战场景下由于错误光流而出现伪影,例如遮挡occlusions或者 strong noise 强噪声。
本节讨论的技术采用a multi-scale of the denoising blocks, the cascaded two-step denoising architecture,end-to-end training 不仅为 FastDVDnet 提供了处理运动的能力,还有助于避免相关的伪影错误的流量估计。此外,与 [43, 38, 37] 类似,FastDVDnet 的去噪块实现了残差学习,这有助于进一步提高结果的质量。


由于遮挡导致的运动伪影。 “超平滑”序列结果的三个连续帧,上图噪声参数σ = 50
(a) V -BM4D (b) VNLB © DVD net (d) FastDVDnet
显式依赖于运动估计技术的视频去噪算法通常会由于具有挑战性的情况下的错误流而出现伪影。在上面的示例中,前面建筑物的遮挡导致 V-BM4D、VNLB 和 DVDnet 的结果中出现运动伪影。 FastDVDnet 的架构中避免了显式运动补偿。实际上,由于其设计特征,网络能够隐式处理运动。最好以数字形式观看
训练细节
数据集是成对的,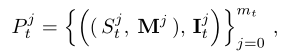
其中S表示在5个连续帧中相同位置裁剪的空间块,I表示输出的干净块,这些都是通过加入了既定的σ ∈ ∈ ∈[5,50]参数的AWGN进行生成的序列,M表示噪声图,其是一个常数。
这些Spatio-temporal patches时空补丁块是在训练数据集中随机找的采样序列机型随机裁剪的。
训练集共计采样来源于the DAVIS database的384000训练样本,patch大小96
至于选择96,是因为The spatial size of the patches was chosen such that the resulting patch size in the coarser scale of the Denoising Blocks is 32 × 32
损失函数: L ( θ ) = 1 2 m t ∑ j = 1 m t ∥ I ^ t j − I t j ∥ 2 \mathcal{L}(\theta)=\frac{1}{2 m_{t}} \sum_{j=1}^{m_{t}}\left\|\hat{\mathbf{I}}_{t}^{j}-\mathbf{I}_{t}^{j}\right\|^{2} L(θ)=2mt1∑j=1mt I^tj−Itj 2, I ^ t j = F ( ( S t j , M j ) ; θ ) \hat{\mathbf{I}}_{t}^{j}=\mathcal{F}\left(\left(S_{t}^{j}, \mathbf{M}^{j}\right) ; \theta\right) I^tj=F((Stj,Mj);θ) 表示网络的输出,$\theta $表示网络的学习参数
Adam优化器优化最小损失函数,默认参数设置
epoch=80 ,min-batch-size=96,learning-rate前50轮 1 e − 3 1e-3 1e−3,50-60轮 1 e − 4 1e-4 1e−4,最后 1 e − 6 1e-6 1e−6
关于
learning-rate:学习速率衰减和自适应速率混合方法也被应用到其他深度学习项目中[36,41],通常都取得了积极的结果
data augment 数据增强:通过引入不同的比例因子和随机翻转来扩大数据。
在前60个epoch,the orthogo- nalization of the convolutional kernels 卷积核的正交化被用作正则化的一种手段。
有人观察到,用正交化来初始化训练可能有助于提高成绩[44,37]。
测试集:the DAVIS-test testset, and Set8
比较方法:DVDNET V-BM4D VNLB VNL_net
结果分析
两个不同的测试集用于对我们的方法进行基准测试:DA VIS 测试集和 Set8(它由 Derf 的测试媒体集合 1 中的 4 个颜色序列和用 GoPro 相机捕获的 4 个颜色序列组成)

(a) 原始 (b) 噪声帧 σ = 40 © V -BM4D (d) VNLB
(e) NV一款商业化去噪软件) (f) VNL net (g) DVD net (h) FastDVDnet。
一般来说,DVDnet 和 FastDVDnet 输出序列都具有显着的时间连贯性。我们的方法呈现的闪烁非常小,尤其是在平坦区域,基于补丁的算法通常会留下低频残留噪声。可以在图 4 中观察到一个示例(最好以数字格式查看)。平坦区域中的时间去相关低频噪声对观看者来说显得特别麻烦。更多视频示例可以在补充材料和算法网站上找到。鼓励读者观看这些示例,以比较我们方法结果的视觉质量。

基于补丁的方法在具有大量重复结构的序列中易于超越 DVDnet 和 FastDVDnet,因为这些方法利用了非局部相似性先验。另一方面,我们的算法可以很好地处理非重复纹理,参见例如图 5 中去噪文本和植被的清晰度
The SpatioTemporal Reduced Reference Entropic Differences (STRRED) is a high performing reduced-reference video ity assessment metric [35]. This metric not only takes into account image quality, but also temporal distortions in the video. We computed the ST-RRED scores with the implementation provided by the scikit-video library2.
该指标不仅考虑了图像质量,还考虑了视频中的时间失真。我们使用 scikit-video 库提供的实现计算了 ST-RRED 分数
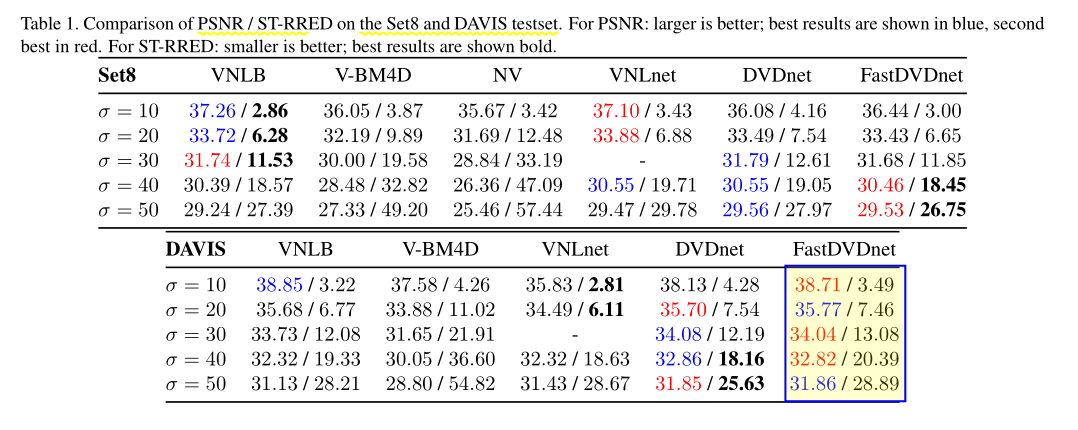
可以观察到,对于较小的噪声值,VNLB 在 Set8 上表现更好。事实上,DVDnet 在某些情况下往往会过度降噪。 FastDVDnet 和 VNLnet 分别是 DAVIS 上在 PSNR 和 ST-RRED 方面表现最好的小 sigma 算法。然而,对于较大的噪声值,DVDnet 超过了 VNLB。最重要的是,方法的使用不涉及手动调整参数,因为它们仅将图像序列和输入噪声的估计作为输入。
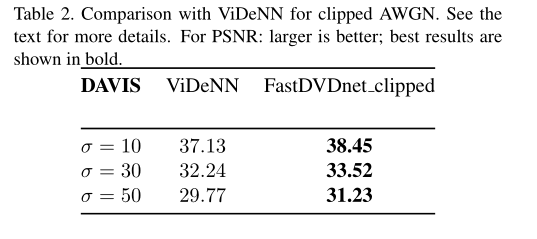
Videnn算法实际上并未针对 AWGN 进行过训练,而是针对裁剪后再加入 AWGN 进行了训练。我们按照同样步骤进行,称之为 FastDVDnet_clipped 。可以观察到,FastDVDnet_clipped 的性能大大优于 ViDeNN 的性能。
运行时间
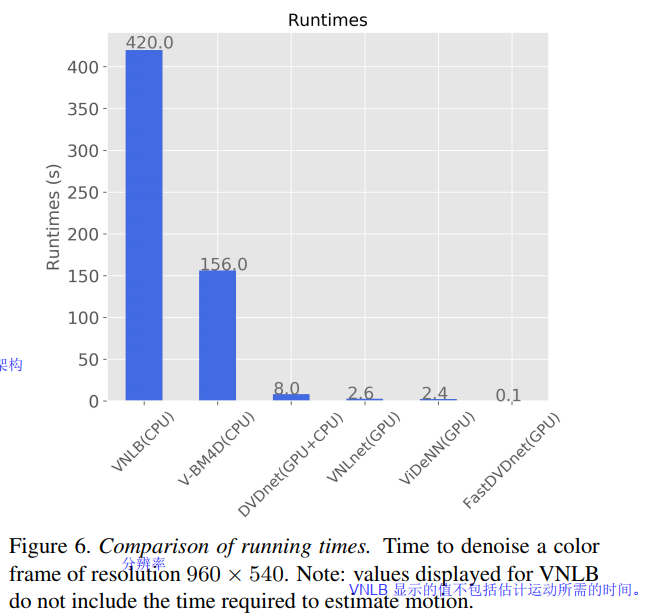
7结论
在本文中,我们介绍了 FastDVDnet,一种最先进的视频去噪算法。 FastDVDnet 的去噪结果具有显着的时间相关性、极低的闪烁和出色的细节保留。即使没有流量估计步骤,也能达到这种性能水平。该算法的运行速度比其他最先进的竞争对手快一到三个数量级。从这个意义上说,我们的方法向高质量实时深度视频降噪迈出了重要一步。尽管本文提出的结果适用于高斯噪声,但我们的方法可以扩展到去噪其他类型的噪声
参考文献
[12] Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Hausser, Caner Hazirbas, Vladimir Golkov, Patrick van derSmagt, Daniel Cremers, and Thomas Brox. Flownet: Learning optical flow with convolutional networks. pages 2758–
\2766. IEEE, Dec 2015. 2
[14] Michael Gharbi, Gaurav Chaurasia, Sylvain Paris, and Fr ¨ edo ´ Durand. Deep joint demosaicking and denoising. ACM Transactions on Graphics, 35(6):1–12, Nov 2016. 3
[16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. 2, 4
[29] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. UNet: Convolutional Networks for Biomedical Image Segmentation, volume 9351 of Lecture Notes in Computer Science, chapter chapter 28, pages 234–241. Springer International
Publishing, 2015. 2
[34] Wenzhe Shi, Jose Caballero, Ferenc Huszar, Johannes Totz, Andrew P. Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. pages 1874–1883. IEEE, Jun 2016. 4
[35] Rajiv Soundararajan and Alan C. Bovik. Video quality assessment by educed reference spatio-temporal entropic differencing. IEEE Transactions on Circuits and Systems for Video Technology, 2013. 6
[37] Matias Tassano, Julie Delon, and Thomas Veit. An analysis and implementation of the ffdnet image denoising method. Image Processing On Line, 9:1–25, Jan 2019. 3, 4, 5
[38] Matias Tassano, Julie Delon, and Thomas Veit. DVDnet: A fast network for deep video denoising. In IEEE International Conference on Image Processing, Sep 2019. 1, 2, 5
[42] Shangzhe Wu, Jiarui Xu, Yu-Wing Tai, and Chi-Keung Tang. Deep High Dynamic Range Imaging with Large Foreground Motions. In European Conference on Computer Vision (ECCV), pages 117–132, 2018. 2
[44] Kai Zhang, Wangmeng Zuo, and Lei Zhang. Ffdnet: Toward a fast and flexible solution for cnn-based image denoising. IEEE Transactions on Image Processing, 27(9):4608–4622, Sep 2018. 1, 2, 3, 5
借鉴参考:https://blog.csdn.net/weixin_30793735/article/details/95353530
and Lei Zhang. Ffdnet: Toward a fast and flexible solution for cnn-based image denoising. IEEE Transactions on Image Processing, 27(9):4608–4622, Sep 2018. 1, 2, 3, 5
借鉴参考:https://blog.csdn.net/weixin_30793735/article/details/95353530