Introduction
There is a new movement around mobile applications and deep learning.
- Apr 2017: Google released MobileNets which is a light weight neural network intended to be used in computationally limited environment.
- Jun 2017: Apple released Core ML which enables machine learning model to run in mobile device.
Further more, recent high-end mobile devices have GPU tip inside it. Actually, they work faster than my Mac Book Pro for computation of machine learning.

Deep learning on the edge is coming to everywhere.
In this article, I would like to introduce a real world usage of them and report how fast it can work.
Application of MobileNets
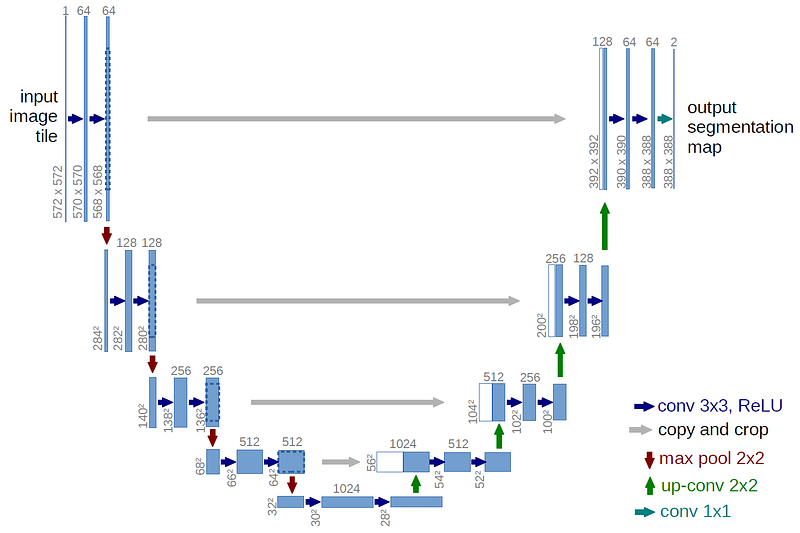
We have recently developed a new deep neural network called MobileUNet which is used for semantic segmentation problem. I won’t talk detail about the network in this article, but I just mention that it has a pretty simple design. As the name shows, it uses MobileNets in U-Net (Fig 1.). You can see more details in Github repository. Keep note only a few points about it at this time.
- It consists of encoder part and decoder part with skips as usual in some deep neural networks for semantic segmentation.
- The encoder part is MobileNets itself, which lacks fully connected layers for classification.
- The decoder part does upsampling by using Convolutional Transpose.
When we started developing it, our primary concern is inference speed. We know that deep neural network works slightly fast with GPU. But what about running it in mobile device?
This is the reason we adopted the idea of MobileNets. Here is the points of MobileNets.
- It introduces depthwise conv block to speed up inference speed.
- It shows high accuracy vs inference speed ratio.
- It has some parameters to control the trade-off between accuracy and speed.
We could get fairly satisfactory result. Here is the example.
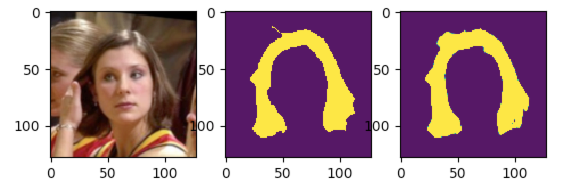
I would like to report more details about speed and accuracy in subsequent chapters.
Speed vs Accuracy in Mobile device
Before talking about the performance of our network, I would like to make more general aspects clear at first.
Does every Convolutions such as Conv2D, DepthwiseConv2D and Conv2DTranspose shows a similar trend of speed in different processors?
The answer is No. If processor is different, some operations can be fast, but some other operations can be slow. The difference between CPU and GPU is easy to follow. Even among in GPU, how they are optimized can be vary.
Fig 3. shows the speed of normal conv block and depthwise conv block. Gist is available here.
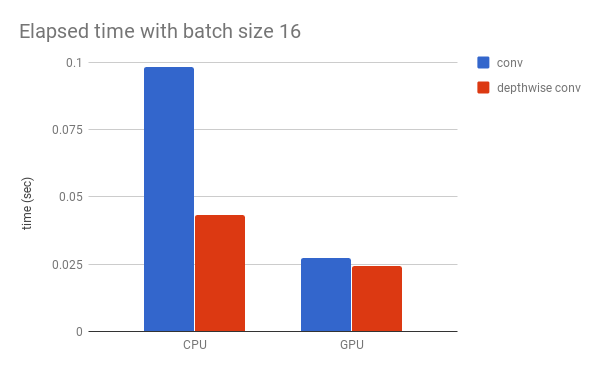
Though the depthwise conv block is much faster than conv block in CPU as theoretically expected, there is not so much difference in the case of GPU.
So, if you want to publish your application using deep learning in mobile device, it’s highly recommended to measure the speed by using some major devices. Now, I would like to share our measurement results of MobileUNet.
I focus on following devices in this article.
- iPhone 6 plus
- iPhone 7 plus
- iPhone 8 plus
- Sony Xperia XZ (Snapdragon 820)
As mentioned already, MobileNets has a parameter, called alpha, to control the trade-off between speed and accuracy. It can be easily applied to MobileUNet, so that MobileUNet has also same parameter. I picked up 4 kinds of alpha (1, 0.75, 0.5 and 0.25) and 4 kinds of image size (224, 192, 160, 128).
Here is the overall speed of each conditions.
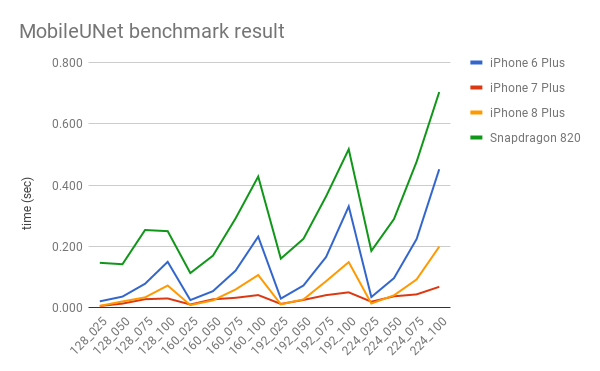
Surprisingly, iPhone 7 plus is the winner, not iPhone 8 plus. I will take a look into it more later. iPhone 7 plus is really fast. It has no problem for real time application in any conditions. While iPhone 6 plus and Snapdragon 820 are not so fast, especially with large alpha. So, we have to choose the best condition carefully with the consideration of accuracy.
Here is the accuracies for each conditions.
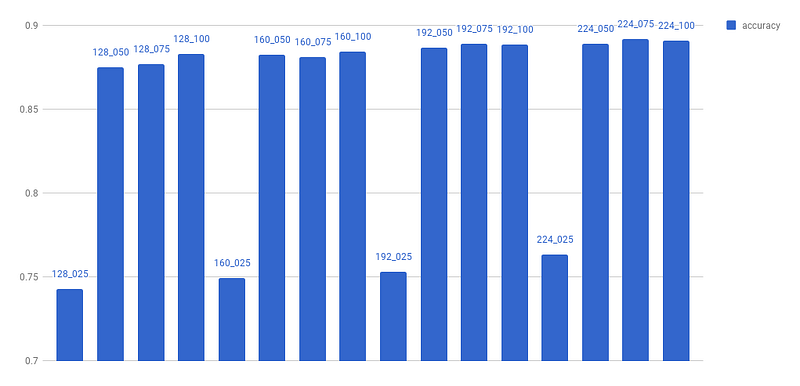
When the alpha is 0.25, the accuracies drop drastically. In other conditions, accuracy gradually decreases according to size and alpha. So, alpha 0.25 is rejected from our target.
This is the speed vs accuracy of Snapdragon 820.
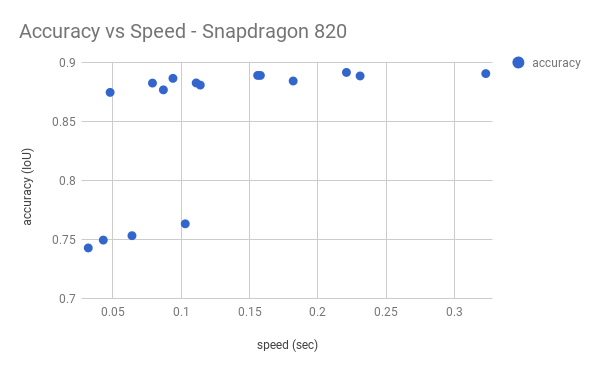
It shows us some options. If the speed is very important for our app, we can choose the left-top one which has 0.875 IoU under the condition of size 128 and alpha 0.5. If accuracy is important, choosing another condition is also possible, e.g. size 192 and alpha 0.5.
It’s also possible to use different model for each devices, if you want, though I do not recommend it for complexity.
Finally, let’s take a look at why iPhone 7 plus is faster than iPhone 8 plus.
As I have already written above, which operations are fast or not, it depends on each processors. It means that the GPU of iPhone 7 plus is fitted with our network better than the GPU of iPhone 8 plus. To figure out it, I made an easy experiment.
I have devided MobileUNet into encoder part and decoder part, and then measured the performance for each.

Apparently, decoder part is the performance bottleneck of iPhone 8 plus. Conv2DTranspose is used only in decoder part. So, the Conv2DTranspose would be the cause of this difference. The GPU of iPhone 7 plus would optimize Conv2DTranspose whereas the GPU of iPhone 8 would not. In this case, other upsampling methods can be an option to improve performance more, though I have not tried it yet.
Scripts used for benchmark in Android and iOS are available at Gist.
Conclusion
The usage of deep learning in mobile device is ready to be spreaded. As a result, deep learning will be much more convenient in near future.
Still, not all of devices have high-spec GPU, so some kinds of performance tuning might be need. It’s important to use real device to measure the performance, because each processors can have different characteristics. The theoretical numbers of Multi-Add are not enough.
The measurement itself is not so difficult. It is not needed to use trained model. You can use non-trained model and identify the bottleneck of performance easily.