Learning to Segment Instances in Videos with Spatial Propagation Network
Jingchun Cheng Sifei Liu Yi-Hsuan Tsai Wei-Chih Hung Shalini De Mello
Jinwei Gu Jan Kautz Shengjin Wang Ming-Hsuan Yang
Tsinghua University University of California Merced 3NVIDIA Research
一、摘要
提出了一个基于深度学习的实例对象分割。
具体分为三步:
1、基于ResNet-101训练了一个通用模型用于前景背景传播;
2、通过在测试视频的第一帧使用增强对象注释微调模型以此训练实例模型和单个对象分割;
为了在视频中区分不同的实例,把实例中的每个对象都计算了像素级score map,每个score map 表明了对象的相似性并且仅在第一步中获得的前景掩模内计算。为精炼score map ,训练了空间传播网络。空间传播网络旨在训练如何基于每个帧中的成对相似性在空间传播粗分割掩码,以外还应用了滤波器,在视频中时间和空间的一致性下识别一个最好的连通区域。
3、通过比较不同实例的得分图确定每个视频中的实例对象分割。
二、介绍
关注的问题是多实例分割问题。
面临两个挑战:
1、不确定性;处理非刚性物体(例如,人类,动物)时,因为这些物体通常具有各种视角,姿势的个体运动。
2、遮挡;
2.1由于前景对象可能在某些帧中完全被遮挡
2.2不同实例之间的遮挡
解决方法:
目前大多数是CNN解决。具体讲是,CNN被训练为遵循视频序列中每帧的FCN结构输出前景/背景分割图。无监督可以训练前景模型,半监督,通过测试视频的第一帧的分割掩码微调模型到特定的前景区域。
问题:
由于前向传播的池化操作,网络生成的分段通常不与实际对象边界对齐。
解决方法:
许多现有的方法应用条件随机场(CRF)作为后处理模块来细化对象边界。
方法的缺陷:
密集连接的CRF需要复杂的潜在功能设计和精细调整的超参数。如端到端可训练的CRF,经常会引入大量内存和计算。
进一步解决的方法:
提出空间传播网络(SPN),分割概率是训练逐像素引导线性2D传播模块。为进一步调整时域中不一致的段,提出了连通区域感知过滤器(CRAF)来消除不一致的标签。
贡献:
•通过将任务分解为前景分割和实例识别,来扩展分段网络同时处理多个实例。
•提出空间传播网络(SPN)通过学习空间亲和力来细化对象分割。
•提出连接区域感知滤器(CRFA)以消除不一致的段。
三、 相关工作
3.1 视频目标分割
无监督和半监督学习
无监督学习:旨在不知道对象知识的情况下分割前景对象。
缺陷:(1)计算量太大;
(2)仅仅应用在离线。
半监督学习:假设视频第一帧的对象掩码是可知的,且在整个视频中被跟踪。最近有CNN的方法将静态图像的离线和在线结合起来。
3.2 实例分割
缺点:遮挡问题对其影响很大
方法:dense CRF
本文的方法:SPN直接从数据本身以端到端的方式学习像素 affinity。
优点:轻量级,计算上有效的细化模块。
四、训练实例分割
给定实例级别的第一帧的对象掩码,我们的目标是在整个视频中分割此实例。
首先训练通用前景/背景分割模型来定位对象,然后微调这个通用模型以学习实例级模型。
4.1 前景分割
构建了基于ResNet-101架构的前景/背景分割网络,并对像素分割预测进行了修改。
如下:1)删除用于分类的完全连接层;
2)将不同级别的卷积模块的特征融合在一起,以便在上采样期间获得更多细节。
池化之后的多尺度融合
优化使用具有softmax函数E的逐像素交叉熵损失。为了克服前景和背景区域之间的不平衡像素数,使用https://arxiv.org/pdf/1504.06375.pdf 整体嵌套边缘检测 中采用的加权版本,并将损失函数定义为:

4.2 实例识别
采用和前景分割一样的方法适用具有softmax函数E的逐像素交叉熵损失,对其微调,用于对象实例和背景。
由于每个视频可能具有多个对象实例,并且不同的实例级模型可能彼此不一致,因此我们开发了一种方法来解决这种混淆,例如,两个对象彼此接近。从实例级模型的输出计算每个对象的逐像素分数图,其中该分数图指示实例分割的可能性。为了利用前景模型并减少噪声段,强制仅在前景分割中得分图为非零。一旦得到了来自不同实例的得分图,就会通过标记每个像素的最高得分来确定最终的实例级细分结果
4.3 网络实施和训练
为了训练前景通用模型,首先使用来自DAVIS训练集的注释,然后使用DAVIS测试集的第一帧中的增强对前景进行微调。
在训练前景通用模型时,使用来自ResNet-101的权重作为初始化。使用批量大小为1的随机梯度下降(SGD)优化器和学习率1e-8的100,000次迭代。
在训练实例级模型时,通过在测试集上使用增强的实例级注释来微调此通用模型。对于实例级模型,使用批量大小1,从学习速率1e-8开始,并且每10,000次迭代将其减少一半,总共30,000次迭代。由于总训练样本的数量相对较少,我们采用仿射变换(即移位,旋转,翻转)来生成一千个样本每一帧。
五、Mask Refinement
以逐帧方式细化mask,这是通过空间传播网络(SPN)完成的,该网络在原始帧的引导下将对象形状从粗略形状改进为更精细的形状,用连接区域感知滤波器(CRAF)消除不一致区域。注意到这两个细化过程独立于实例,其中学习的SPN可以应用于任何实例。
5.1 空间传播网络(SPN)
SPN包含用于学习亲和实体的deep CNN,以及用于细化粗掩模的空间线性传播模块。 对于任何像素对,在亲和力、学习的成对关系的指导下细化粗掩模。 所有模块都是可区分的,并使用SGD方法进行联合培训。 由于循环架构的线性时间复杂性,空间线性传播模块在计算上对于推理是有效的。
SPN = CNN + 空间线性传播
5.1.1 定理
SPN包含一个传播模型,这个模型是通过2D图的线性传播构建可学习的图形。
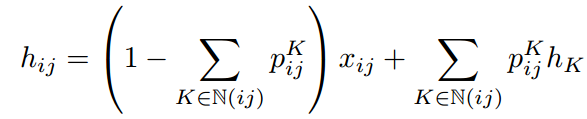
H被定义为m×n特征图顶部的传播隐藏层。
逐列过渡执行,P是一个过渡矩阵。
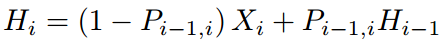
反向传播,导数是从顶部流回H的误差。

5.1.2 网络实施
SPN = CNN + 空间线性传播
CNN:输出传播矩阵的所有要素;
空间传播模型:精细化分割;
引导网络的下采样部分采用VGG-16做1-5层的池化,上采样部分使用对齐结构,接着多尺度融合。
引导网络通常采用RGB图像。它输出每个像素的所有连接权重w.r.t,其中每个像素都有3×4个参数要训练。 传播模块采用前一步骤产生的粗分段掩码,以及引导网络生成的权重。 假设有一个输入传播模块的大小为n×n×c的地图,引导网络需要输出尺寸为n×n×c×(3×4)的权重图,即每个像素在输入映射与每个方向的3个标量权重配对,总共4个方向。 传播模块包含4个用于不同方向的独立隐藏层,其中每个层将输入映射与其各自的权重映射组合。使用节点式最大池来集成隐藏层并获得最终的传播结果。
5.1.3 网络训练
训练SPN有两个要求。
首先,SPN处理两级掩码细化。
其次,对于具有地面实况注释的每个训练图像,需要粗糙掩模。因此,在PASCAL VOC 2012的训练集上训练SPN,其中粗面由FCN生成。 对于每个图像,我们根据注释随机选择有效标签,同时将所有其他像素视为背景,以便从原始的21个类中生成两类训练样本。 在训练过程中,我们从图像,二进制标签和粗糙掩模中随机裁剪256×256个方块。注意到只有一个SPN作为一般的细化模块,没有对来自Davis 2017数据集的任何框架进行微调。
5.2 连接区域感知滤波器(CRFA)
再用SPN之后,因为分割是单一方式而不考虑其他帧的时间信息,所以会导致实例分割的混乱。故采用CRFA。
三步:
1、对于对象i,在应用SPN之后在它的特征图上提取连接域(CR1,CR2,…);然后把每个连接域的jaccard(J1,J2,…)相似性与之原帧的域进行比较计算,作为区域(A1,A2,…),定义CRS作为对象i的最佳连接域,如果连接域的jaccard多个值最大,取面积最大的。
2、计算每两个对象之间的覆盖率,公式如下:
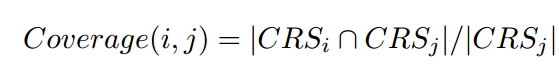
如果值大于0.9,删去对象i中的j,将i更新为CRSi = CRSi - CRSj
3、如果对象i的 CRSi < 0.1,检查未被选择为CRS的所有连通区域。然后,如果这些区域中的一个具有大于δ的jaccard相似性,将该连接区域选为CRSi并重复第2步。
将每个选定连接区域之外的分数设置为零。 为了获得最终实例分割,通过考虑所有实例的最大分数来确定每个像素的标签。
六、实验
6.1 数据集和评估指标
DAVIS基准测试是最近发布的高质量视频对象分割数据集。由多个对象和实例级像素注释的视频组成,共有150个序列(60个训练集,每个30个验证,测试开发和测试挑战集),10459个注释帧和376个对象。
首先使用训练集来训练模型并评估验证集。然后,最佳模型将接受培训和验证集的培训,并在2017年DAVIS挑战赛上进行测试。挑战使用所有对象实例的区域相似性(J均值)和等高线精度(F均值)的均值作为性能指标。 验证集中使用相同的算法(来自DAVIS网站的评估代码)来验证本文的方法。
6.2 实例识别比较
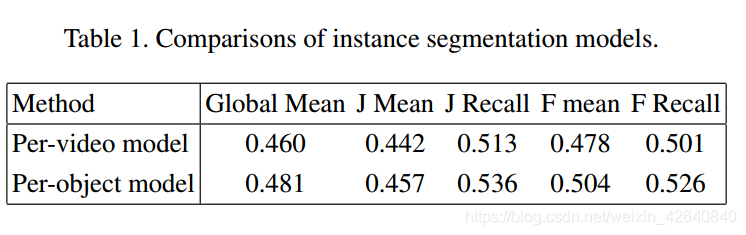
比较了两种不同的模型用于实例级分割:每视频和每对象设置。初始化来自前景模型的权重,每个视频对象识别网络具有softmax层,其具有N + 1维分数图作为输出,其中N表示数字视频中的对象,另外一个用于背景。每个得分图表示一个对象的概率。
在预测中,具有最大分数的像素是被视为该像素的标签。对于每个对象模型,只考虑一个对象每次都是前景。每个perobject模型的网络都有一个二维输出,其中包含背景和一个对象实例。在预测中,得分不同对象的地图连接在一起,如果最高分低于0.5,像素属于背景。否则,每个像素的对象标签由具有最大分数的实例确定。这两种方法的比较如表1所示,模型在训练集上进行训练并进行测试在验证集上。结果表明了每个对象
Global在全球范围内的表现优于每视频模型2.1%意思。因此,我们选择使用每个对象模型做以下实验。
6.3 Ablation Study
逐一比较
6.4 Runtime Analysis
七、总结
在这项工作中,我们建议使用空间传播网络(SPN)和连接区域感知过滤器(CRAF)来细化空间和时间域中的实例分段。 我们表明,在具有挑战性的DAVIS 2017数据集中,所提出的方法可以实现视频中多个实例分段的竞争性能。
