如何找出模型需要的特征?首先要找到该领域的业务专家,让他们给一些建议。比如我们需要解决一个药品疗效的分类问题,那么先找到领域专家,向他们咨询哪些因素(特征)会对该药品的疗效产生影响,较大影响和较小影响的因素都要。这些因素就是我们特征的第一候选集。(摘自:https://www.cnblogs.com/pinard/p/9032759.html)
以上是从业务角度对特征进行的选择,这也是最重要的方法。
除此之外,从技术角度考虑,特征选择的方法主要分为3大类:
- 过滤法(Filter):针对单个特征的统计学特性进行筛选。按照发散性或者相关性对各个特征进行评分,通过设定阈值选择特征。
- 包裹法(Wrapper):本质是用迭代法。根据模型的预测效果进行评分,每次向模型添加一个特征,或者删除一个特征,直到达到特定的停止条件。
- 嵌入法(Embedded):是一种基于模型的方法。使用模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。特征选择本身融合在模型训练的过程中。
过滤法(Filter)
(以下内容部分摘自:https://www.zhihu.com/question/28641663/answer/110165221)
1,方差法
基本原理是:移除方差较低的特征。如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,那么这个特征对于样本的区分并没有什么用。具体方法是:计算各个特征的方差,选择方差大于阈值的特征。
用sklearn中feature_selection库的VarianceThreshold类来选择特征的代码如下:
from sklearn.feature_selection import VarianceThreshold
#方差选择法,返回值为特征选择后的数据
#参数threshold为方差的阈值
VarianceThreshold(threshold=3).fit_transform(iris.data)
2,皮尔逊相关系数法
基本原理是:移除和目标y不相关的特征。具体方法是:计算各个特征对目标值的皮尔逊相关系数以及相关系数的p值,选择显著相关的特征。
用sklearn中feature_selection库的SelectBest(选择k个最强大的特征)类结合相关系数来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
#选择K个最好的特征,返回选择特征后的数据
#第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量,输出二元组(评分,P值)的数组,数组第i项为第i个特征的评分和P值。在此定义为计算相关系数
#参数k为选择的特征个数
SelectKBest(lambda X, Y: array(map(lambda x:pearsonr(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
此外,还可以用SelectPercentile类选择最强大的k%特征。(下同)
需要注意的是:皮尔逊相关系数只能衡量x和y之间是否线性相关。
3,卡方检验
基本原理是:运用卡方检验中的独立性检验,如果两类别型变量之间有关联,那么说明彼此之间不独立。具体方法是:假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量。
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#选择K个最好的特征,返回选择特征后的数据
SelectKBest(score_func=chi2, k=2).fit_transform(iris.data, iris.target)
注:卡方检验只能用于x和y都是类别型变量的情况。
4,F检验
基本原理是:运用单因素方差分析,在变量总离差平方和中,如果组间方差所占比例较大,说明观测变量的变动主要是由控制变量引起的。具体方法是:将组间均方差除以组内均方差,构建统计量。
用sklearn中feature_selection库的SelectBest(选择k个最强大的特征)类结合f_classif来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_classif
SelectKBest(score_func=f_classif, k=4).fit_transform(iris.data, iris.target)
注:f_classif用于y是类别型变量的情况,如果y是数值型变量,那么用f_regression,此时和用皮尔逊相关系数一样。
5,互信息法
互信息也能评价定性自变量和定性因变量之间的相关性,从信息增益的角度来看,互信息表示由于x的引入而使y的不确定性减少的量。互信息值越大,说明该自变量和因变量之间的相关性越大。互信息计算公式如下: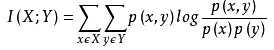 。
。
用sklearn中feature_selection库的SelectBest(选择k个最强大的特征)类结合mutual_info_classif来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import mutual_info_classif
SelectKBest(score_func=mutual_info_classif, k=4).fit_transform(iris.data, iris.target)
但是将互信息直接用于特征选择其实不是太方便:1、它不属于度量方式,也没有办法归一化,在不同数据及上的结果无法做比较;2、对于连续变量的计算不是很方便,通常变量需要先离散化,而互信息的结果对离散化的方式很敏感。
因此为了处理定量数据,最大信息系数法(Mutual information and maximal information coefficient,MIC)被提出。它首先寻找一种最优的离散化方式,然后把互信息取值转换成一种度量方式,取值区间在[0,1]。
使用sklearn中feature_selection库的SelectKBest类结合最大信息系数法(minepy 提供了MIC功能)来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest
from minepy import MINE
#由于MINE的设计不是函数式的,定义mic方法将其为函数式的,返回一个二元组,二元组的第2项设置成固定的P值0.5
def mic(x, y):
m = MINE()
m.compute_score(x, y)
return (m.mic(), 0.5)
#选择K个最好的特征,返回特征选择后的数据
SelectKBest(lambda X, Y: array(map(lambda x:mic(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
注:互信息法可以衡量x和y之间的非线性关系。
包裹法(Wrapper)
1,递归特征消除法(Recursive Feature Elimination, RFE)
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。首先,在原始特征上训练模型,每个特征得到一个权重。之后,那些拥有最小绝对值权重的特征被踢出特征集。如此往复递归,直至剩余的特征数量达到所需的特征数量。RFE的表现如何很依赖于基模型,如果基模型稳定那么特征选择的质量也稳定。
之前所说的逐步回归法(请见:https://www.cnblogs.com/HuZihu/p/12329998.html)就是递归特征消除法的一种,之前文章是针对线性回归模型来说的,如果要扩展到其他模型,那么使用交叉验证预测误差来衡量模型。
使用sklearn中feature_selection库的RFE类来选择特征的代码如下:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
#递归特征消除法,返回特征选择后的数据
#参数estimator为基模型
#参数n_features_to_select为选择的特征个数
RFE(estimator=LogisticRegression(), n_features_to_select=2).fit_transform(iris.data, iris.target)

嵌入法(Embedded)
1,基于树模型的特征选择法
目前对于分类问题来说一般使用基尼系数或信息增益,对回归问题来说一般使用RMSE(均方根误差)或MSE(平方误差)。
使用sklearn中feature_selection库的SelectFromModel类结合GBDT模型来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import GradientBoostingClassifier
#GBDT作为基模型的特征选择
SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target)
2,正则化
这里指L1正则方法,其本质是将某些特征对应的权重置零。使用带惩罚项的基模型,除了能筛选出特征外,同时也训练出了模型。
使用sklearn中feature_selection库的SelectFromModel类结合带L1惩罚项的逻辑回归模型来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
#带L1惩罚项的逻辑回归作为基模型的特征选择
SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(iris.data, iris.target)
这三大类特征选择方法的优缺点:
- 过滤式方法运用统计指标来为每个特征打分并筛选特征,其聚焦于数据本身的特点。其优点是计算快,不依赖于具体的模型。缺点是选择的统计指标不是为特定模型定制的,因而最后的准确率可能不高。而且因为进行的是单变量统计检验,没有考虑特征间的相互关系,并且不能对交互项进行选择。
- 包裹式方法使用模型来筛选特征,通过不断地增加或删除特征,在验证集上测试模型准确率,寻找最优的特征子集。包裹式方法因为有模型的直接参与,因而通常准确性较高,但是因为每变动一个特征都要重新训练模型,因而计算开销大,其另一个缺点是容易过拟合。
- 嵌入式方法利用了模型本身的特性,将特征选择嵌入到模型的构建过程中。典型的如 Lasso 和树模型等。准确率较高,计算复杂度介于过滤式和包裹式方法之间,但缺点是只有部分模型有这个功能。