时间序列分类
我第一次遇到时间序列分类的概念时,我最初的想法是:我们如何对时间序列进行分类?时间序列分类的数据是什么样子的?
可以想象,时间序列分类数据不同于常规分类问题,因为属性具有有序的序列。让我们来看看一些时间序列分类用例来理解这种差异。
1) ECG/EEG信号分类
心电图(ECG,Electrocardiogram)记录着心脏的电活动,被广泛地用于诊断各种心脏问题。这些心电信号是用外部电极捕捉的。例如,考虑下面的信号样本,它表示一个心跳的电活动。左边的图像表示正常的心跳,而右边的图像表示心肌梗死。
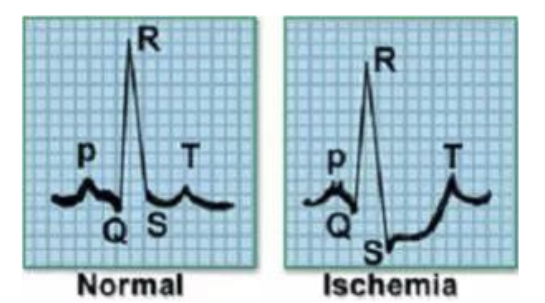
- 从电极上采集的数据是时间序列形式的,信号可以分为不同的类别。我们还可以对记录大脑电活动的脑电波(EEG)信号进行分类。
2) 图像数据
图像也可以是时间序列相关的格式。考虑以下场景:
作物生长在特定的领域取决于天气条件、土壤肥力、水的可用性和其他外部因素。这片土地的照片是连续5年每天拍摄的,并标有种植在这片土地上的作物的名称。数据集中的图像是在固定的时间间隔后拍摄的,并且有一个确定的序列,这是对图像进行分类的一个重要因素。
3) 动作传感器数据分类
传感器产生高频数据,可以识别出物体在其范围内的运动。通过设置多个无线传感器,观察传感器信号强度的变化,可以识别出物体的运动方向。
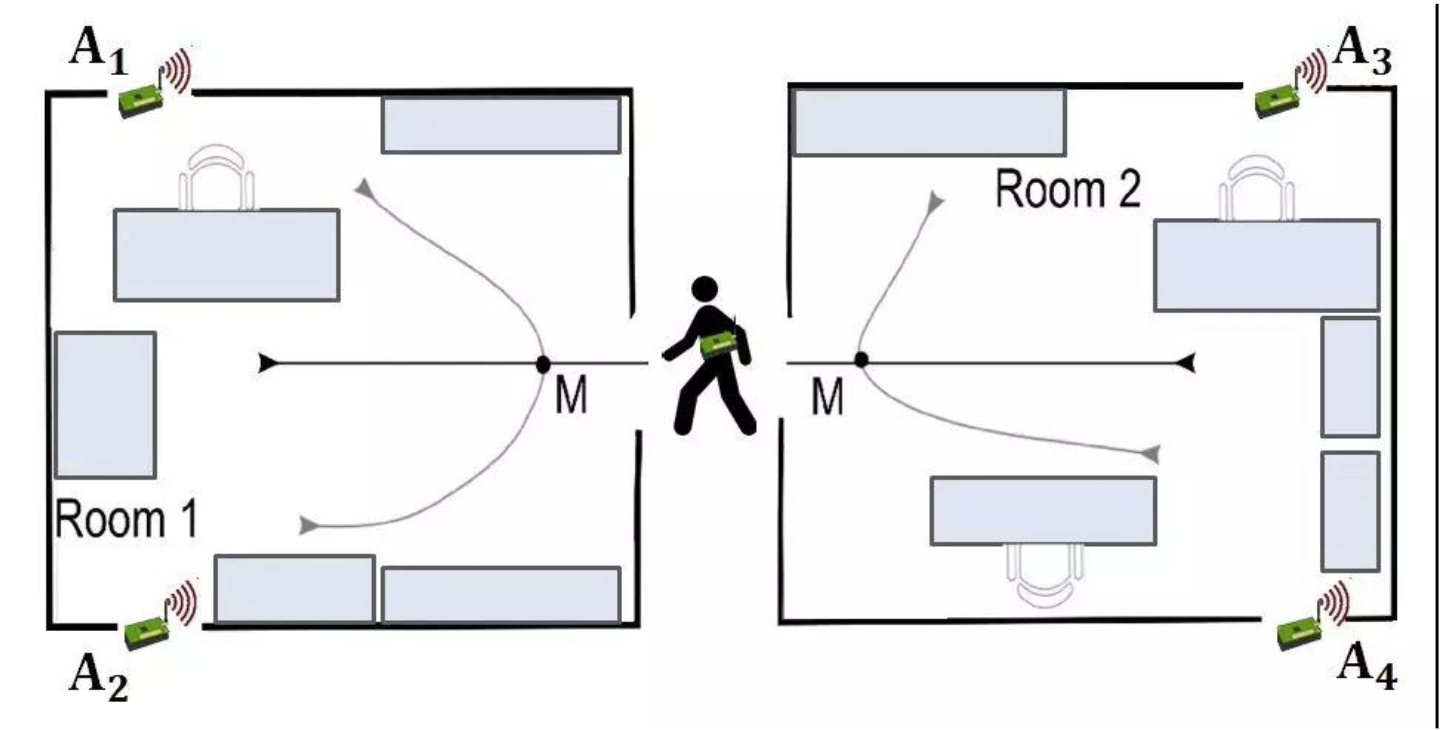
下面我们以“室内用户运动预测”这个问题为例。
在这个挑战中,多个运动传感器被放置在不同的房间中,目标是根据从这些运动传感器捕捉到的频率数据来识别一个人是否在房间中移动过。一共有四个运动传感器(A1、A2、A3、A4)分布在两个房间。请看下图,它说明了传感器在每个房间的位置。这两个房间的设置是在3对不同的房间组中创建的(group1、group2、group3)。
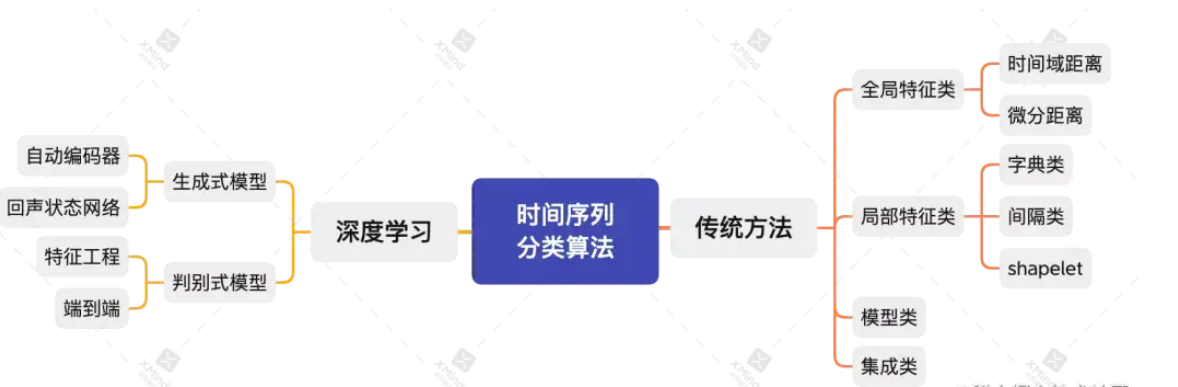
传统方法
全局特征分类算法将完整时间序列作为特征,计算时间序列间的相似性来进行分类,通常采用距离度量函数与1-NN相结合的方式。该类方法的研究方向为用于度量完整时间序列相似性的距离度量函数。
典型全局特征算法-dtw
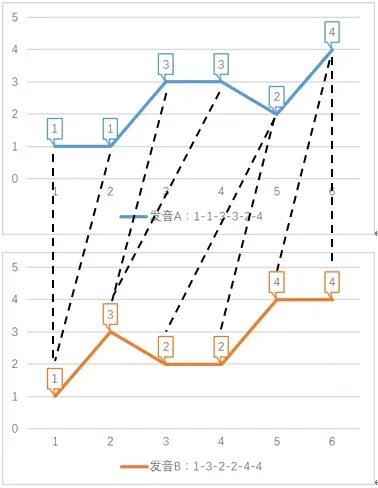
如果我们允许序列的点与另一序列的多个连续的点相对应(相当于把这个点所代表的音调发音时间延长),然后再计算对应点之间的距离之和,这就是dtw算法。dtw算法允许序列某个时刻的点与另一序列多个连续时刻的点相对应,称为时间规整(Time Warping)
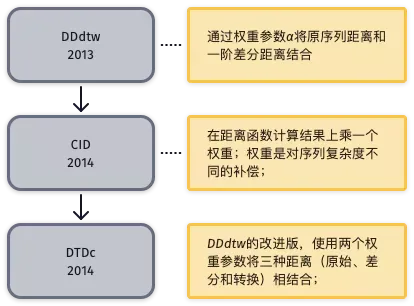
典型全局特征算法-差分距离法
- 差分距离法计算原始时间序列的一阶微分,然后度量两个时间序列的微分序列的距离,即微分距离。
- 差分法将微分距离作为原始序列距离的补充,是最终距离计算函数的重要组成部分。
- 差分距离法将位于时间域的原时间序列和位于差分域的一阶差分序列相结合,提升分类效果。
研究方向主要是如何将原序列和差分序列合理结合,差分距离法的演进过程如图所示。
局部特征
局部特征类分类算法,将时间序列中的一部分子序列作为特征用于时间序列分类。该类算法的关键在于寻找能够区分类别的局部特征。由于子序列更短,因此构建的分类器速度更快,但需要一定的时间来寻找局部特征。
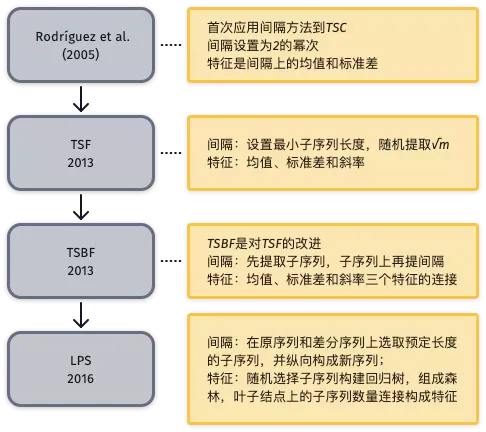
典型局部特征算法-间隔(interval)
局部特征类中的间隔法将时间序列划分为几个间隔区间(interval),从每个区间中提取特征。
- 该类方法适用于长序列中带有相位依赖并具有区分度的子序列,以及噪声。
基于间隔的时间序列分类算法发展历程如图所示。
TSF
TSF(Time Series Forest)算法是一种用于时间序列分类的集成学习算法。该算法通过将时间序列数据转化为特征向量,并采用随机森林的方法进行分类。
TSF通过使用随机森林方法(以每个间隔的统计信息作为特征)来克服间隔特征空间巨大的问题。训练一棵树涉及选择根号m 个随机区间,生成每个系列的随机区间的均值,标准差和斜率,然后在所得的3根号m 个特征上创建和训练一棵树。
TSF算法的主要步骤如下:
特征提取:将原始时间序列数据转化为特征向量。常用的特征提取方法包括傅里叶变换、小波变换等。
数据集划分:将提取得到的特征向量划分为若干子集。
随机选择子集:从划分得到的子集中随机选择一部分进行训练。
随机选择特征:从特征向量中随机选择一部分特征进行训练。
构建决策树:根据选择的子集和特征构建决策树模型。
集成决策树:重复步骤3-5,构建多棵决策树,并将它们集成为随机森林模型。
进行分类:使用构建好的随机森林模型对新的时间序列数据进行分类。
TSF算法的优点:
- 是能够处理大规模的时间序列数据,并且具有较好的分类性能。
- 它能够通过随机选择子集和特征来减少计算量,并且通过集成多棵决策树来提高分类准确性。
但是,TSF算法也存在一些限制:
1)它对于时间序列数据的长度敏感,较短的时间序列可能会导致分类性能下降。
2) 此外,TSF算法对于时间序列数据的分布假设较强,如果数据不满足这些假设,算法的性能可能会受到影响。
shapelet
shapelet其实就是一段时间序列数据中的某个子序列,这个子序列是这段时间序列数据的最显著的特点(显然,shapelet和趋势,周期分量一样,也是时序数据本身的一种特别的分量),其提出主要是为了解决早期使用KNN解决时间序列分类的问题而提出的。
- KNN
- 时间序列分类中,knn的思路很简单,一条样本的m个时间步的数据就是这条样本的m个特征,然后使用knn来跑即可,当然时间序列分类的knn应用中,使用欧式距离这类常规的距离计算显然丢弃了时序数据本身的序列依赖性的信息,因此会使用到DTW这种特殊的用于时序数据距离计算的距离公式来度量时序数据的远近
shapelet的思路则非常简单直观,降低了计算开销,并且可解释性很好,具体的,文中给了一个例子:
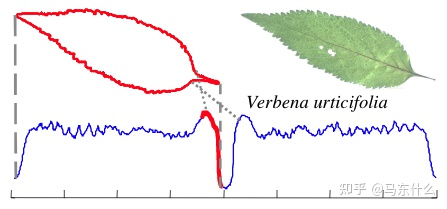
现在我们把这个叶子的轮廓转化为时序数据(叶子的轮廓对应的点坐标都在一个x-y平面坐标系中),然后我们要对这两个叶子对应的时序数据进行分类。
从上图可以看到,shapelet是蓝色曲线中标红的部分,即为左边这个叶子对应的时序数据最显著的特点,我们可以直接只用这段数据来代替左边叶子全量的序列数据,然后使用基于DTW距离的KNN算法。
两个叶子对应的时序数据有很多个时间步都是类似的,那么基于距离的计算很明显会收到大部分相似的时间点对应的数据的影响,但是现在我们提取出其中最明显的部分,那么显然模型能够更加关注不同时序样本之间显著的不同
- 两个叶子的最显著特点的DTW距离如果很大则显然就不一样嘛,很好理解。
多标签分类问题
多标签的分类不平衡问题:https://discuss.pytorch.org/t/multi-label-multi-class-class-imbalance/37573
多分类:
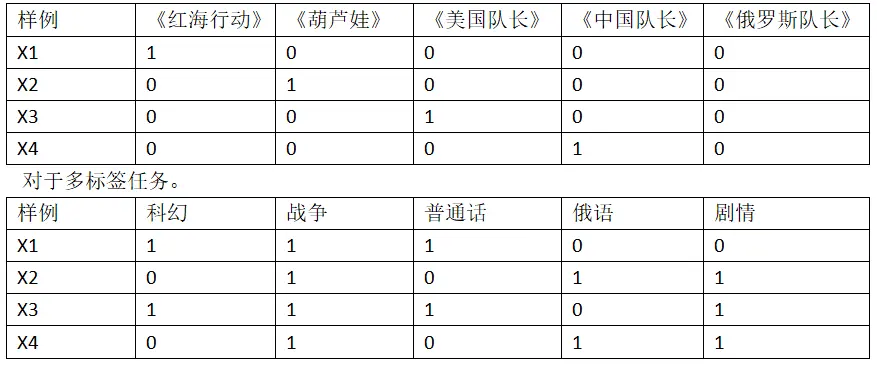
多标签:
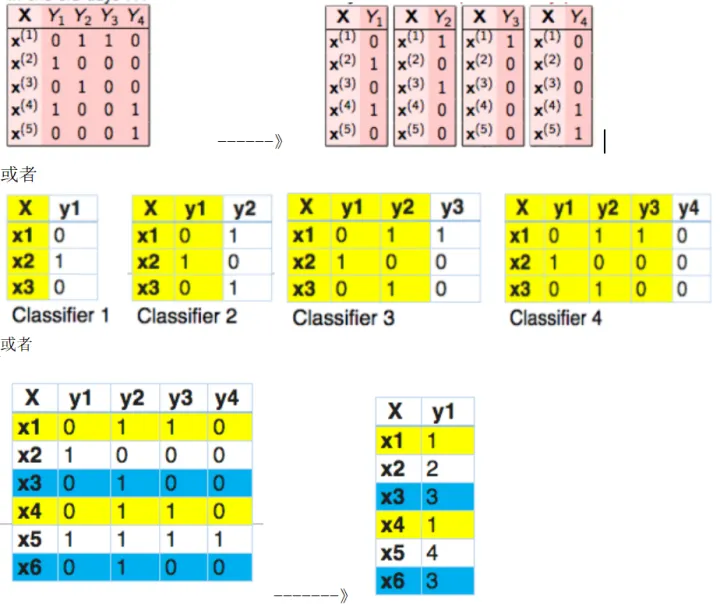
先来解释一下,什么叫做多标签(multi-label)文本分类问题。
这里咱们结合一个 Kaggle 上的竞赛实例。
竞赛的名字叫做:恶毒评论分类挑战(Toxic Comment Classification Challenge)
- 链接在这里:kaggle
Keras sample weight for imbalance multilabel datasets:
from sklearn.utils import class_weight
list_classes = ["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"]
y = train[list_classes].values
sample_weights = class_weight.compute_sample_weight('balanced', y)
model.fit(X_t, y, batch_size=batch_size, epochs=epochs,validation_split=0.1,sample_weight=sample_weights, callbacks=callbacks_list)
模型部署相关
知乎文章:https://zhuanlan.zhihu.com/p/195750736