说明:本手册所列包来自Awesome-Python ,结合GitHub 和官方文档,参考 SeanCheney 大神在简书上翻译的《利用Python进行数据分析·第2版》,整理所得。
时间序列(time series)数据是一种重要的结构化数据形式,具体的应用场景,主要有以下几种:
- 时间戳(timestamp),特定的时刻。
- 固定时期(period),如2007年1月或2010年全年。
- 时间间隔(interval),由起始和结束时间戳表示。时期(period)可以被看做间隔(interval)的特例。
- 实验或过程时间,每个时间点都是相对于特定起始时间的一个度量。例如,从放入烤箱时起,每秒钟饼干的直径。
Part 1 概述
pandas最基本的时间序列类型就是以时间戳(通常以Python字符串或datatime对象表示)为索引的Series。
NaT(Not a Time)是pandas中时间戳数据的null值。
下表显示了pandas可以处理的时间相关类的类型以及如何创建它们:
| Class | Remarks | How to create |
|---|---|---|
| Timestamp | Represents a single timestamp | to_datetime, Timestamp |
| DatetimeIndex | Index of Timestamp | to_datetime, date_range, bdate_range, DatetimeIndex |
| Period | Represents a single time span | Period |
| PeriodIndex | Index of Period | period_range, PeriodIndex |
Part 2 时间戳和时间区间
pd.Timestamp and pd.Period
pandas用NumPy的datetime64数据类型以纳秒形式存储时间戳
# pd.Timestamp
In [8]: pd.Timestamp(datetime(2012, 5, 1))
In [9]: pd.Timestamp('2012-05-01')
In [10]: pd.Timestamp(2012, 5, 1)
# Out : Timestamp('2012-05-01 00:00:00')
# pd.Period
In [11]: pd.Period('2011-01')
Out[11]: Period('2011-01', 'M')
In [12]: pd.Period('2012-05', freq='D')
Out[12]: Period('2012-05-01', 'D')DatetimeIndex and PeriodIndex
pd.Timestamp and pd.Period对象是以DatetimeIndex and PeriodIndex的格式存储在Series的索引中
In [13]: dates = [pd.Timestamp('2012-05-01'), pd.Timestamp('2012-05-02'), pd.Timestamp('2012-05-03')]
In [14]: ts = pd.Series(np.random.randn(3), dates)
In [16]: ts.index
Out[16]: DatetimeIndex(['2012-05-01', '2012-05-02', '2012-05-03'], dtype='datetime64[ns]', freq=None)pd.to_datetime(Converting to Timestamps)
pd.to_datetime(arg)
arg : integer, float, string, datetime, list, tuple, 1-d array, Series or DataFrame/dict-like
# Providing a Format Argument
>>> pd.to_datetime('2010/11/12', format='%Y/%m/%d')
>>> pd.to_datetime('13000101', format='%Y%m%d', errors='ignore')
datetime.datetime(1300, 1, 1, 0, 0)
# from Multiple DataFrame Columns
>>> df = pd.DataFrame({'year': [2015, 2016],
'month': [2, 3],
'day': [4, 5]})
>>> pd.to_datetime(df)
# integer, float
>>> pd.to_datetime(1490195805, unit='s')
Timestamp('2017-03-22 15:16:45')
# Using the origin Parameter(default,origin=970-01-01 00:00:00)
>>> pd.to_datetime([1, 2, 3], unit='D',
origin=pd.Timestamp('1960-01-01'))Part 3 索引和切片
DatetimeIndex 可以像常规索引一样使用
>>> ts['2011-01-05':]日期和解析为时间戳的字符串可以作为索引参数传递
>>> ts['1/10/2011']
>>> ts['20110110']对于较长的时间序列,只需传入“年”或“年月”即可轻松选取数据的切片:
>>> longer_ts['2001']
>>> longer_ts['2001-05']datetime对象也可以进行切片:
>>> ts[datetime(2011, 1, 7):]截断方法
ts.truncate(before=None, after=None, axis=None, copy=True)
>>> ts.truncate(after='1/9/2011')Part 4 日期范围
date_range (日历日) and bdate_range(工作日)
pd.date_range(start=None, end=None, periods=None, freq='D', tz=None, normalize=False, name=None, closed=None, **kwargs)
pd.bdate_range(start=None, end=None, periods=None, freq='B', tz=None, normalize=True, name=None, closed=None, **kwargs)
返回DatetimeIndex对象
默认会保留起始和结束时间戳的时间信息(如果有的话)
normalize参数:被规范化(normalize)到午夜的时间戳。
In [50]: start = datetime(2011, 1, 1)
In [51]: end = datetime(2012, 1, 1)
In [52]: index = pd.date_range(start, end)
In [56]: pd.date_range(start, periods=100, freq='M')
In [58]: pd.date_range(start, end, freq='BM')
# 自定义频率
In [62]: weekmask = 'Mon Wed Fri'
In [63]: holidays = [datetime(2011, 1, 5), datetime(2011, 3, 14)]
In [64]: pd.bdate_range(start, end, freq='C', weekmask=weekmask, holidays=holidays)Part 5 DateOffset Objects
前面的DatetimeIndex通过将频率字符串( 如’M’,’W’和’BM’)传递给freq参数来创建各种频率的对象。这些频率字符串被翻译成一个DateOffset实例,代表一个常规的频率增量。(from pandas.tseries.offsets)
| 别名 | Offset类型 | 描述 |
|---|---|---|
| B | BDay | 工作日 |
| C | CDay | 定制工作日 |
| D | Day | 日历日 |
| W | Week | 每周 |
| M | MonthEnd | 每月最后一个日历日 |
| SM | SemiMonthEnd | 每月15日和最后一个日历日 |
| BM | BMonthEnd | 每月15日和最后一个工作日 |
| CBM | CBMonthEnd | 定制每月最后一个日历日 |
| MSS | MonthBegin | 每月第一个日历日 |
| SMS | SemiMonthBegin | 每月1日和15日 |
| BMS | BMonthBegin | 每月第一个工作日 |
| CBMS | CBMonthBegin | 定制每月第一个工作日 |
| Q | QuarterEnd | 每季度最后一个日历日 |
| BQ | BQuarterEnd | 每季度最后一个工作日 |
| QS | QuarterBegin | 每季度第一个日历日 |
| BQS | BQuarterBegin | 每季度第一个工作日 |
| A,Y | YearEnd | 每年最后一个日历日 |
| BA,BY | BYearEnd | 每年最后一个工作日 |
| AS,YS | YearBegin | 每年第一个日历日 |
| BAS,BYS | BYearBegin | 每年第一个工作日 |
| H | Hour | 每小时 |
| BH | BusinessHour | 每工作小时 |
| T,min | Minute | 每分钟 |
| S | Second | 每秒 |
| L,ms | Milli | 毫秒 |
| U,us | Micro | 微秒 |
| N | Nano | 纳秒 |
| 锚定偏移量 | 这些频率所描述的时间点并不是均匀分隔的 | |
| W-SUN,W-MON,…,W-SAT | Week | 每周从指定日期算起(MON,TUE,WEN,THU,FRI,SAT,SUN) |
| WOM-1MON,WOM-2MON,… | WeekOfMonth | 每月第x个星期y |
| Q-JAN,Q-FEB,… | QuarterEnd | 以指定月份(最后一个日历日)结束季度 |
| BQ-JAN,BQ-FEB,… | BQuarterBegin | 以指定月份(最后一个工作日)结束季度 |
| QS-JAN,QS-FEB,… | QuarterBegin | |
| BQS-JAN,BQS-FEB,… | BQuarterBegin | |
| A-JAN,A-FEB,… | YearEnd | 以指定月份(最后一个日历日)结束年度 |
| BA-JAN,BA-FEB,… | BYearEnd | 以指定月份(最后一个工作日)结束年度 |
| AS-JAN,AS-FEB,… | YearBegin | |
| BAS-JAN,BAS-FEB,… | BYearBegin |
offset基本用法
Examples
In [112]: d = datetime(2008, 8, 18, 9, 0)
In [114]: from pandas.tseries.offsets import *
In [82]: hour = Hour()
In [84]: four_hours = Hour(4) # 传入一个整数即可定义偏移量的倍数
# 一般来说,无需明确创建这样的对象,只需使用诸如"H"或"4H"这样的字符串别名即可
In [86]: pd.date_range('2000-01-01', '2000-01-03 23:59', freq='4h')
In [87]: Hour(2) + Minute(30) # 数学运算
Out[87]: <150 * Minutes>
pd.date_range('2000-01-01', periods=10, freq='2h30min') # 字符串"2h30min"WOM日期
WOM(Week Of Month)是一种非常实用的频率类,它以WOM开头。它使你能获得诸如“每月第3个星期五”之类的日期。
pd.date_range('2012-01-01', '2012-09-01', freq='WOM-3FRI')Part 6 移动(超前和滞后)数据
shift方法
ts.shift(periods=1, freq=None, axis=0)
In [91]: ts = pd.Series(np.random.randn(4),
....: index=pd.date_range('1/1/2000', periods=4, freq='M'))
In [94]: ts.shift(-2)
In [96]: ts.shift(3, freq='D')通过Offset对日期进行位移
In [98]: from pandas.tseries.offsets import Day, MonthEnd
In [99]: now = datetime(2011, 11, 17)
In [100]: now + 3 * Day()
Out[100]: Timestamp('2011-11-20 00:00:00')
# 如果加的是锚定偏移量(比如MonthEnd),第一次增量会将原日期向前滚动到符合频率规则的下一个日期
In [102]: now + MonthEnd(2)
Out[102]: Timestamp('2011-12-31 00:00:00')
# 锚定偏移量的rollforward和rollback方法,可明确地将日期向前或向后“滚动”
In [103]: offset = MonthEnd()
In [104]: offset.rollforward(now)
Out[104]: Timestamp('2011-11-30 00:00:00')
In [105]: offset.rollback(now)
Out[105]: Timestamp('2011-10-31 00:00:00')Part 7 时期及其算术运算
Period
pd.Period(value=None, freq=None, ordinal=None, year=None, month=None, quarter=None, day=None, hour=None, minute=None, second=None)
时期(period)表示的是时间区间,比如数日、数月、数季、数年等。
In [149]: p = pd.Period(2007, freq='A-DEC')
In [150]: p
Out[150]: Period('2007', 'A-DEC')
In [151]: p + 5
Out[151]: Period('2012', 'A-DEC')
In [153]: pd.Period('2014', freq='A-DEC') - p
Out[153]: 7PeriodIndex and period_range
pd.period_range(start=None, end=None, periods=None, freq='D', name=None)
pd.PeriodIndex(data=None, ordinal=None, freq=None, start=None, end=None, periods=None, copy=False, name=None, tz=None, dtype=None, **kwargs)
period_range函数可用于创建规则的时期范围,返回PeriodIndex对象
In [154]: rng = pd.period_range('2000-01-01', '2000-06-30', freq='M')
In [155]: rng
Out[155]: PeriodIndex(['2000-01', '2000-02', '2000-03', '2000-04', '2000-05', '20
00-06'], dtype='period[M]', freq='M')
# 作为时间序列索引引用
In [156]: pd.Series(np.random.randn(6), index=rng)
# pd.PeriodIndex
In [157]: values = ['2001Q3', '2002Q2', '2003Q1']
In [158]: index = pd.PeriodIndex(values, freq='Q-DEC')
In [159]: index
Out[159]: PeriodIndex(['2001Q3', '2002Q2', '2003Q1'], dtype='period[Q-DEC]', freq
='Q-DEC')时期的频率转换
Period和PeriodIndex对象都可以通过其asfreq方法被转换成别的频率。
p.asfreq(freq,how='end')
freq : string
how : {‘E’, ‘S’, ‘end’, ‘start’}, default ‘end’
Start or end of the timespan
In [160]: p = pd.Period('2007', freq='A-DEC')
In [162]: p.asfreq('M', how='start')
Out[162]: Period('2007-01', 'M')
In [163]: p.asfreq('M', how='end')
Out[163]: Period('2007-12', 'M')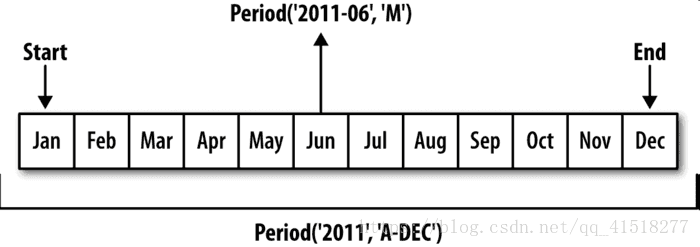
按季度计算的时期频率
# 2012Q4
In [175]: p = pd.Period('2012Q4', freq='Q-JAN')
In [176]: p
Out[176]: Period('2012Q4', 'Q-JAN')
# 2012Q4是从11月到1月( freq='Q-JAN')
In [177]: p.asfreq('D', 'start')
Out[177]: Period('2011-11-01', 'D')
In [178]: p.asfreq('D', 'end')
Out[178]: Period('2012-01-31', 'D')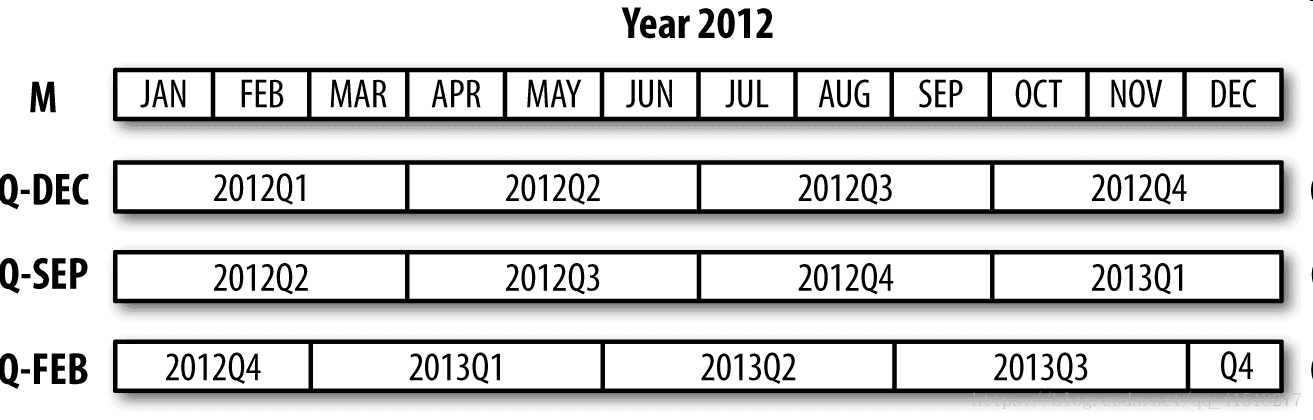
Timestamp和Period户型给转换
Timestamp.to_period(freq=None)
Period.to_timestamp(freq,how)
freq : string or DateOffset, default is ‘D’
how: str, default ‘S’ (start): ‘Start’, ‘Finish’, ‘Begin’, ‘End’
Part 8 重采样及频率转换
重采样(resampling)指的是将时间序列从一个频率转换到另一个频率的处理过程。将高频率数据聚合到低频率称为降采样(downsampling),而将低频率数据转换到高频率则称为升采样(upsampling)。
pandas对象都带有一个resample方法,它是各种频率转换工作的主力函数。resample有一个类似于groupby的API,调用resample可以分组数据,然后会调用一个聚合函数
ts.resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention='start', kind=None, loffset=None, limit=None, base=0, on=None, level=None)
Parameters:
rule : 表示重采样频率的字符串或Offset
axis : int, optional, default 0
fill_method: {”ffill,’bfill’},插值方法
limit: 向前或向后填充的最大区间
kind: {‘period’,’timestamp’},默认聚合的时间序列的索引类型
closed : {‘right’, ‘left’},降采样中时间段的哪一端闭合
label : {‘right’, ‘left’},降采样中如何设置聚合值的标签
convention : {‘start’, ‘end’, ‘s’, ‘e’},低频周期到高频周期的惯用法
loffset : timedelta,面元标签的时间校正值
降采样
In [213]: rng = pd.date_range('2000-01-01', periods=12, freq='T')
In [214]: ts = pd.Series(np.arange(12), index=rng)
In [216]: ts.resample('5min', closed='right').sum()
# 通过loffset设置一个字符串或日期偏移量对索引进行位移
In [219]: ts.resample('5min', closed='right',
.....: label='right', loffset='-1s').sum()
Out[219]:
1999-12-31 23:59:59 0
2000-01-01 00:04:59 15OHLC重采样
金融领域中有一种无所不在的时间序列聚合方式,即计算各面元的四个值:第一个值(open,开盘)、最后一个值(close,收盘)、最大值(high,最高)以及最小值(low,最低)。传入how=’ohlc’即可得到一个含有这四种聚合值的DataFrame。整个过程很高效,只需一次扫描即可计算出结果:
In [220]: ts.resample('5min').ohlc()
Out[220]:
open high low close
2000-01-01 00:00:00 0 4 0 4
2000-01-01 00:05:00 5 9 5 9
2000-01-01 00:10:00 10 11 10 11升采样和插值
In [221]: frame = pd.DataFrame(np.random.randn(2, 4),
.....: index=pd.date_range('1/1/2000', periods=2,freq='W-WED'),
.....: columns=['Colorado', 'Texas', 'New York', 'Ohio'])
In [226]: frame.resample('D').ffill(limit=2)Part 9 移动窗口函数
移动窗口函数
ts.rolling(window, min_periods=None, freq=None, center=False, win_type=None, on=None, axis=0, closed=None)
window : int, or offset
ts.rolling(250).mean().plot() # 移动窗口平均值作图指数加权函数
另一种使用固定大小窗口及相等权数观测值的办法是,定义一个衰减因子(decay factor)常量,以便使近期的观测值拥有更大的权数。衰减因子的定义方式有很多,比较流行的是使用时间间隔(span),它可以使结果兼容于窗口大小等于时间间隔的简单移动窗口(simple moving window)函数。
ts.ewm(com=None, span=None, halflife=None, alpha=None, min_periods=0, freq=None, adjust=True, ignore_na=False, axis=0)
ts.ewm(span=30).mean().plot()二元移动窗口函数
有些统计运算(如相关系数和协方差)需要在两个时间序列上执行。
# 假设你想要一次性计算多只股票与标准普尔500指数的相关系数
In [262]: corr = returns.rolling(125, min_periods=100).corr(spx_rets)
In [263]: corr.plot()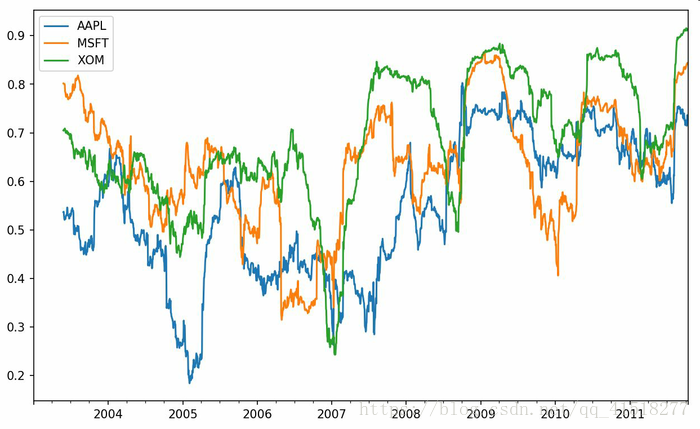
用户定义的移动窗口函数
rolling_apply函数使你能够在移动窗口上应用自己设计的数组函数。唯一要求的就是:该函数要能从数组的各个片段中产生单个值(即约简)。
In [265]: from scipy.stats import percentileofscore
In [266]: score_at_2percent = lambda x: percentileofscore(x, 0.02)
In [267]: result = returns.AAPL.rolling(250).apply(score_at_2percent)
In [268]: result.plot()Part 10 时区处理
请参考 SeanCheney 大神在简书上翻译的《利用Python进行数据分析·第2版》