导读
在不断发展的人工智能(AI)领域中,数据一直被视为最宝贵的资源之一。数据驱动的AI正以前所未有的方式塑造着未来,尤其在XR(扩展现实)领域,其中硬件和算法快速迭代。在这个领域,数据的效率、质量和可扩展性对于开发交互式AI算法至关重要。
我们是PICO交互数据实验室团队,负责构建以数据为中心的人工智能。在 XR(扩展现实)互动领域,高精度和强鲁棒性的3D互动是提供卓越用户体验的基础。这也意味着我们对支持算法模型的数据标签提出了更高的要求,包括更高的准确性和更好的泛化性能。
在过去一年多的时间里,我们专注于解决数据相关的问题,特别关注了:
- 高效数据获取 (
HaMuCo: Hand Pose Estimation via Multiview Collaborative Self-Supervised Learning) - 高精度数据标注(
Decoupled Iterative Refinement Framework for Interacting Hands Reconstruction from a Single RGB Image,Reconstructing Interacting Hands with Interaction Prior from Monocular Images) - 数据应用 (
Realistic Full-Body Tracking from Sparse Observations via Joint-Level Modeling)
在这里,我们非常高兴与大家分享我们四项被 ICCV2023 录取的工作成果。
HaMuCo
论文标题:《HaMuCo: Hand Pose Estimation via Multiview Collaborative Self-Supervised Learning》
项目链接:https://zxz267.github.io/HaMuCo
论文链接:https://arxiv.org/abs/2302.00988
近些年来,3D 手部姿态估计的研究取得了显著的进展,然而这些进展很大程度上依赖于大规模带有 3D 标注的数据集。构建这样的数据集是一个费时又费力的过程。为了避免对 3D 标注的依赖,本研究提出一种全新的手部多视角协同自监督学习方法 HaMuCo,该方法利用可学习的跨视角交互网络对单视角网络进行监督,从而在标签噪声较大的情况下,稳定地实现有效的自监督训练。

HaMuCo 采用两阶段的网络结构,包含单视角网络以及跨视角交互网络。单视角网络使用基于模型(MANO)的方法来提供手部先验知识,从而在仅基于带有噪声的伪标签训练的基础上得到相对鲁棒的手部姿态估计结果;并为多视角网络提供多种丰富有效的手部特征。跨视角交互网络首先利用每一个视角提供的手部特征构建多视角图结构特征;其次利用双分支跨视角交互模块进行多视角的特征交互,从而使每一个视角可以捕获其他视角的互补特征来回归出更准确的 3D 手部姿态估计结果;最后对跨视角交互模块的输出结果进行多视角融合,用更准确的融合结果对单视角网络进行自蒸馏。由于缺乏准确的标签监督,本研究设计了两种多视角一致性损失函数来引导跨视角网络的自监督学习。
本研究通过大量实验验证了 HaMuCo 中的各项设计均对手部自监督学习有正向效果;同时该方法可以应用于多种场景(有/无外参,单/多视角),且在各种场景下的自监督表现均优于现有方法。此项工作还获得 ECCV HANDS22 Challenge 第一名。
DIR
论文标题:《Decoupled Iterative Refinement Framework for Interacting Hands Reconstruction from a Single RGB Image》
项目链接:https://pengfeiren96.github.io/DIR
论文链接:https://arxiv.org/abs/2302.02410
紧密交互的双手三维重建是一个极具挑战性的任务。一方面,对于紧密交互的双手,双手关节点之间具有多样的空间依赖关系,手部姿态的解空间复杂,这显著地增加了手部姿态预测的难度;另一方面,双手局部外观相似性高并且紧密交互双手之间往往存在严重的互遮挡,网络提取的视觉特征易混淆,这导致重建的手模型与图像的不对齐问题。
为了解决这些问题,我们提出了一种解耦合地迭代修正框架(DIR),能够同时实现精确的手部姿态预测和图像对齐。DIR构建了一个二维视觉特征空间和一个三维节点特征空间。DIR在三维节点空间中进行短距-长距双手关系建模,在二维视觉特征空间中进行局部视觉特征去混淆。DIR通过二维和三维之间的空间映射关系,以节点特征为媒介沟通这两个空间,实现迭代地特征增强和手部姿态修正。DIR在目前最具挑战性的双手数据集上实现了远超SOTA的手部重建精度和像素对齐效果;同时,DIR在不需要虚拟数据辅助训练的情况下,表现出了强大的泛化能力。此工作入选 ICCV2023 Oral。

单视图中重建双手
论文标题:《Reconstructing Interacting Hands with Interaction Prior from Monocular Images》
项目链接:https://github.com/binghui-z/InterPrior_pytorch
论文链接:https://arxiv.org/abs/2308.14082
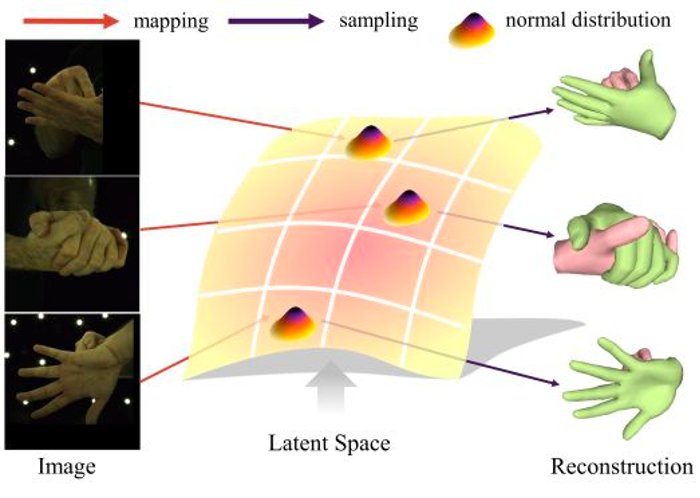
相比于单视图的单手重建任务,从单视图中重建双手面临更大的挑战,因为单视角固有的歧义性以及双手具有相似的外观、自遮挡严重等问题,要从单视角输入图像中准确地定位每个关节的位置是一项具有挑战性的任务。为了解决这些问题,我们提出了一种全新解决问题的路径:首先构建了一个双手互动的先验,将互动重建任务定义为从这个先验中进行条件采样的任务。
双手互动先验的成功构建来源于两方面:我们基于MoCap系统,构建了一个大规模的双手交互数集,获取交互双手的MANO参数模型;利用这些数据,我们构建了基于变分编码器的双手交互先验网络,包括均值编码模块、方差编码模块和重采样模块等用于预测均值和方差,并在重采样后通过解码器输出期望的交互结果。最终,我们利用ViT提取单视角图像的特征,并充分融合其交互先验的相关性,最终获取双手重建的 SOTA 结果。在双手交互重建方面具有巨大的潜力,将为AR/VR领域的发展提供重要的贡献。
Realistic Full-Body Tracking
论文标题:《Realistic Full-Body Tracking from Sparse Observations via Joint-Level Modeling》
项目链接:https://zxz267.github.io/AvatarJLM
论文链接:https://arxiv.org/abs/2308.08855
在VR/AR场景下更自然和准确地驱动数字人有益于给用户带来更加沉浸式的体验。在VR/AR场景下,最容易获取的输入是头戴设备和手柄的跟踪信息。通过这些有限的跟踪信息来驱动数字人是一个受限且极具有挑战的任务。对此,本研究提出了一个能够建模关节点相关性的两阶段框架,从而基于三个跟踪信息序列回归出准确、平滑和合理的全身姿态序列。

第一阶段
在第一阶段中,该方法先通过多层感知机得到初始的全身关节点信息,并基于此信息和输入跟踪信号构建关节点级别特征序列(包括:关节点位置特征、关节点旋转特征以及输入特征)。
第二阶段
在第二阶段中,该方法将关节点级别特征序列输入时空 Transformer 中捕获关节点之间的时空关系,从而得到更准确的全身姿态序列结果。
此外,该方法利用了多种损失函数(手部对齐损失函数,动态相关损失函数以及物理相关损失函数)来在这样受限的任务中更好地训练此两阶段框架。
最终,通过在虚拟数据集(AMASS)和实采数据集上的大量实验均证明了该方法可以取得比现有方法更好的准确率、平滑性以及物理合理性。
写在最后
欢迎大家对论文交流讨论,有任何问题可联系: