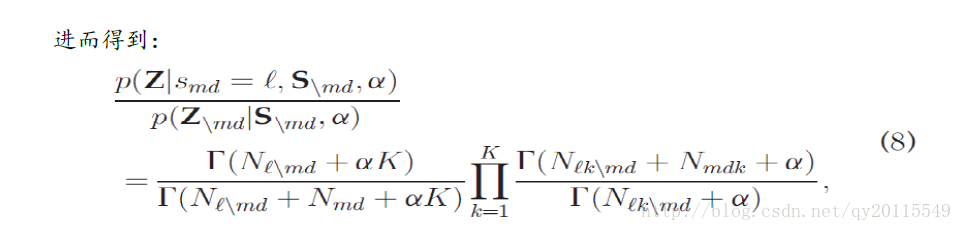本文作者:合肥工业大学 管理学院 钱洋 email:[email protected] 内容可能有不到之处,欢迎交流。
未经本人允许禁止转载。
论文来源
Iwata T, Hirao T, Ueda N. Topic Models for Unsupervised Cluster Matching[J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(4): 786-795.
作者是日本人Iwata T,也是个机器学习大牛,每年都有一系列的文章出来,还是很厉害的。这篇文章是作者18年在TKDE上发表的。
论文简介
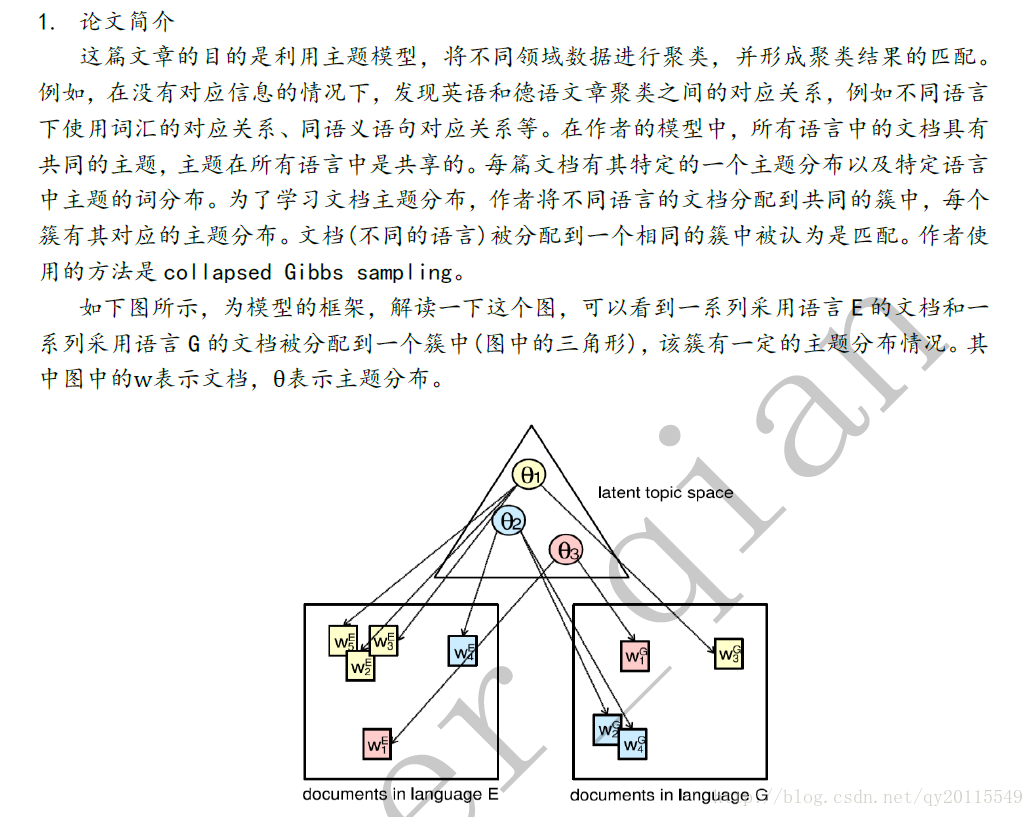
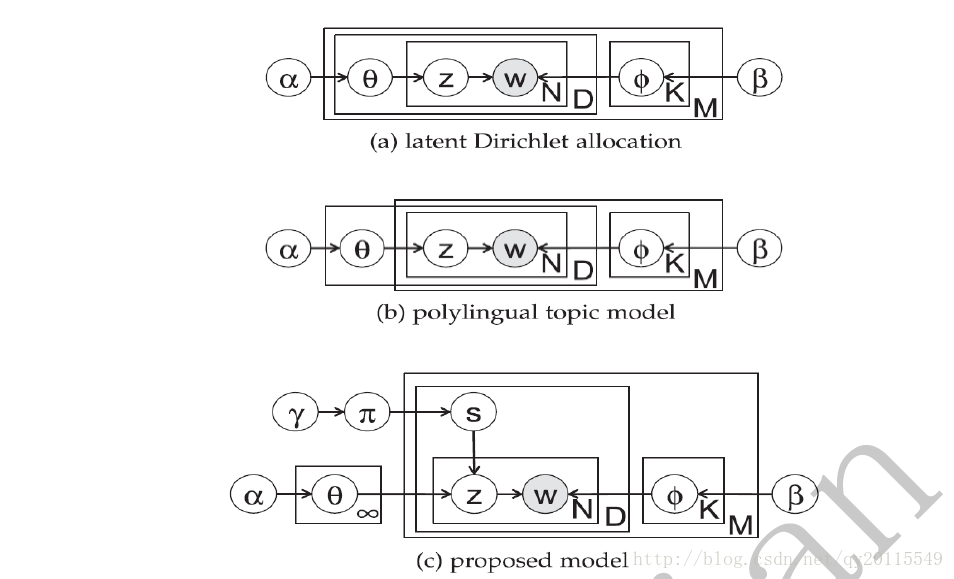
这篇文章的目的是利用主题模型,将不同领域数据进行聚类,并形成聚类结果的匹配。例如,在没有对应信息的情况下,发现英语和德语文章聚类之间的对应关系,例如不同语言下使用词汇的对应关系、同语义语句对应关系等。在作者的模型中,所有语言中的文档具有共同的主题,主题在所有语言中是共享的。每篇文档有其特定的一个主题分布以及特定语言中主题的词分布。为了学习文档主题分布,作者将不同语言的文档分配到共同的簇中,每个簇有其对应的主题分布。文档(不同的语言)被分配到一个相同的簇中被认为是匹配。作者使用的方法是collapsed Gibbs sampling。
论文详细介绍