前言

论文地址:https://aclanthology.org/2021.naacl-main.16.pdf
代码地址:https://github.com/alexandra-chron/lexical_xlm_relm
前人工作&存在问题
在双语翻译情境中,前人工作发现BLI指标(bilingual lexicon induction)和翻译结果关系很强,而《Probing Pretrained Language Models for Lexical Semantics》一文发现静态的cross-lingual词向量的BLI会比LM预训练出来的更好,换句话说,预训练语言模型得到的对齐太弱。
本文贡献
本文在语言模型预训练之前,先用词向量的对齐方法得到对齐的词向量,对语言模型的embedding层做了初始化,得到了更好的UNMT结果。
具体方法
第一步:为语言A+语言B进行BPE分词、为语言A和语言B分别学FT(fasttext)token向量、用VecMap(《A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings》)做了空间的对齐,来对语言模型的embedding做初始化。
第二步:在语言A+语言B上做MLM pretrain、做DAE+Online-BT的UNMT train。
具体实验
所提方法用于两个baseline
- 用于XLM:就是“具体方法”
- 用于RE-LM:A分词、在语言A(高资源)上做语言模型的MLM pretrain、A+B分词、扩充总体词表来加入语言B,语言B中的token embedding不做随机初始化,而是先学习语言B的FT,然后和语言模型embedding层已有的语言A的token embedding用VecMap做对齐,初始化语言B的token embedding,接着再在语言A+语言B上…(“具体方法的第二步”)
和baseline的比较?
文中说:EN-MK两语种更加不同,所以方法得到了更好的结果。

双语的单词级别的induction
用了NN和CSLS两种相似度度量。同样的,En-MK更加不同。

单词级别的翻译指标—BLEU 1-gram
果然,方法的指标更高,且EN-MK的效果更好。

token embedding是否需要finetune?
finetune更好。

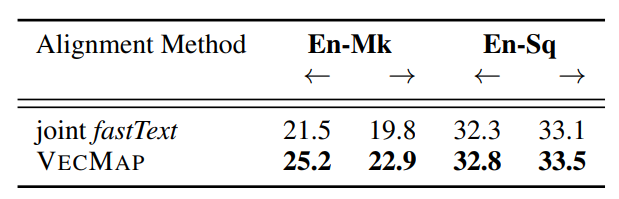
各自学FT embedding然后显式对齐,还是直接学习joint FT embedding做对齐更好?
前者更好,尤其对于En-MK,没有很多重叠词汇。
疑问
- 对语言A+语言B进行jointly BPE,语言A和语言B各自得到的token有重复,重复token的embedding到底是语言A的还是语言B的?----> VecMap就是利用了重复的token,去看原文!