在本文中,我们介绍一个动态主题模型,该模型捕获了顺序组织的文档语料库中主题的演变。 我们通过分析由Ed Edi-son于1880年创立的Jour-nal Science的100多年的OCR文章来证明其适用性。在这种模式下,文章按年份分组,每年的艺术作品都来自于去年主题演变而来的一系列主题。
在随后的部分,我们扩展了经典状态空间模型,以指定主题演化的统计模型。然后,我们开发了有效的近似后验推理技术,用于从一系列文档中确定不断变化的主题。最后,我们提供了定性结果,展示了动态主题模型如何以新的方式探索大型文档集合,以及定量结果,与静态主题模型相比,它们具有更高的预测准确性。
一、Dynamic Topic Models
传统的时间序列建模主要关注连续数据,而主题模型则是针对分类数据而设计的。 我们的方法是在底层主题多项式的自然参数空间上使用状态空间模型,以及用于对文档特定主题比例建模的逻辑正态分布的自然参数。
首先,我们回顾静态主题模型的基本统计假设,例如潜在狄利克雷分配,也叫三层贝叶斯概率模型(LDA,Latent Dirichlet Allocation)。设![]() 为K个主题,每个主题都是固定词汇表的分布。 在静态主题模型中,假设每个文档都来自以下生成过程:
为K个主题,每个主题都是固定词汇表的分布。 在静态主题模型中,假设每个文档都来自以下生成过程:

此过程隐含地假定文档是从同一组主题交换绘制的。然而,对于许多集合,文档的顺序反映了一组不断变化的主题。 在动态主题模型中,我们假设数据按时间片划分,例如按年。 我们使用K分量主题模型对每个切片的文档建模,其中与切片t相关联的主题从与切片t-1相关联的主题演变而来。
对于具有V项的K分量模型,令![]() 表示切片t中主题k的自然参数的V向量。 多项分布的通常表示是通过其均值参数化。 如果我们用π表示V维多项式的平均参数,则自然参数的第i个分量由映射
表示切片t中主题k的自然参数的V向量。 多项分布的通常表示是通过其均值参数化。 如果我们用π表示V维多项式的平均参数,则自然参数的第i个分量由映射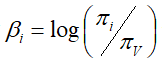 给出。 在典型的语言建模应用中,Dirichlet分布用于模拟关于字的分布的不确定性。 但是,Dirichlet不适合顺序建模。 相反,我们在一个随高斯噪声演化的状态空间模型中链接每个主题
给出。 在典型的语言建模应用中,Dirichlet分布用于模拟关于字的分布的不确定性。 但是,Dirichlet不适合顺序建模。 相反,我们在一个随高斯噪声演化的状态空间模型中链接每个主题![]() 的自然参数; 这种模型最简单的版本是:
的自然参数; 这种模型最简单的版本是:

因此,我们的方法是通过在动态模型中链接高斯分布并将发射值映射到单纯形来对组成随机变量的序列进行建模。这是正态分布对时间序列单纯形数据的扩展。
在LDA中,文档特定主题比例θ来自Dirichlet分布。 在动态主题模型中,我们使用具有平均值α的逻辑法线来表示比例的不确定性。 使用简单的动态模型再次捕获模型之间的顺序结构:
![]()
为简单起见,我们不对主题相关性的动态建模,就像Blei和Lafferty对静态模型所做的那样。
通过将主题和主题比例分布链接在一起,我们按顺序绑定了一组主题模型。 因此,序列语料库的生成过程如下:

请注意,π将多项自然参数映射到平均参数:![]()
这个生成过程的图形模型如下图所示。当水平箭头被移除时,打破时间动态,图形模型简化为一组独立的主题模型。 利用时间动态,切片t处的第k个主题从切片t-1处的第k个主题平滑演化。

图形解释:动态主题模型的图形表示(用于三个时间片)。 每个主题的自然参数![]() 随着时间演变,以及主题比例的逻辑正态分布的平均参数
随着时间演变,以及主题比例的逻辑正态分布的平均参数![]() 。
。
二、近似推理
使用自然参数的时间序列可以使用高斯模型来计算时间动态; 然而,由于高斯和多项式模型的非共轭性,后验推断是难以处理的。 于是,我们提出了一种近似后推理的变分方法。 我们使用变分方法作为随机模拟的确定性替代方法,以处理典型的文本分析的大数据集。 虽然Gibbs采样已经有效地用于静态主题模型,但非共轭性使得采样方法对于这种动态模型更加困难。
变分方法背后的思想是优化潜在变量上的分布的自由参数,使得分布在Kullback-Liebler(KL)发散到真实后验时接近; 然后,这种分布可以用作真正后验的替代。在动态主题模型中,潜在变量是主题![]() ,混合比例
,混合比例![]() 和主题指标
和主题指标![]() 。变分分布反映了潜在变量的群体结构。 每个主题的多项参数序列都有变化参数,每个文档级潜在变量都有变化参数。 近似变分后验是:
。变分分布反映了潜在变量的群体结构。 每个主题的多项参数序列都有变化参数,每个文档级潜在变量都有变化参数。 近似变分后验是:
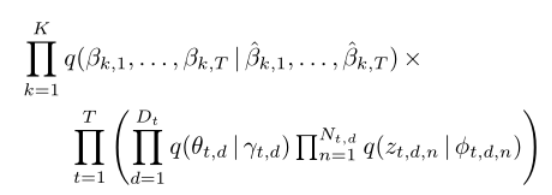
在常用的平均场近似中,每个潜在变量被认为独立于其他潜变量。 然而,在![]() 的变分分布中,我们通过设置具有高斯“变分观测值”
的变分分布中,我们通过设置具有高斯“变分观测值”![]() 的动态模型来保留主题的顺序结构。 这些参数适合于最小化得到的后验(即高斯)和真实后验(非高斯)之间的KL发散。
的动态模型来保留主题的顺序结构。 这些参数适合于最小化得到的后验(即高斯)和真实后验(非高斯)之间的KL发散。
文档级潜变量的变分分布遵循与Blei等人相同的形式。 每个比例向量![]() 被赋予自由度Dirichlet参数
被赋予自由度Dirichlet参数![]() ,每个主题指示符
,每个主题指示符![]() 被赋予自由多项式参数
被赋予自由多项式参数![]() ,并且优化通过坐标上升进行。文档级变分参数的更新具有封闭形式; 我们使用共轭梯度法来优化主题级变分观测。由此得到的自然主题参数
,并且优化通过坐标上升进行。文档级变分参数的更新具有封闭形式; 我们使用共轭梯度法来优化主题级变分观测。由此得到的自然主题参数![]() 的变分近似结合了时间动态; 我们描述了两种方法,一种基于卡尔曼滤波器的近似,另一种是基于小波回归。
的变分近似结合了时间动态; 我们描述了两种方法,一种基于卡尔曼滤波器的近似,另一种是基于小波回归。
2.1 Variational Kalman Filtering(变分卡尔曼滤波器)
变分参数作为输出的视图基于高斯密度的对称性,![]() ,这使得能够使用线性状态空间模型的标准前向-后向计算。 图形模型及其变分近似如下图所示。这里三角形表示变分参数; 它们可以被认为是卡尔曼滤波器的“假设输出”,以便于计算。
,这使得能够使用线性状态空间模型的标准前向-后向计算。 图形模型及其变分近似如下图所示。这里三角形表示变分参数; 它们可以被认为是卡尔曼滤波器的“假设输出”,以便于计算。

图形解释:本文第一幅图的时间序列主题模型的变分近似的图形表示。变分参数β和α被认为是卡尔曼滤波器的输出,或者是非参数回归设置中的观测数据。
为了在更简单的设置中解释这种技术背后的主要思想,考虑unigram模型![]() (在自然参数化中)随时间演变的模型。 在该模型中没有主题,因此没有混合参数。 计算是我们对更一般的潜变量模型所需的那些更简单的版本,但展示了基本特征。我们的状态空间模型是:
(在自然参数化中)随时间演变的模型。 在该模型中没有主题,因此没有混合参数。 计算是我们对更一般的潜变量模型所需的那些更简单的版本,但展示了基本特征。我们的状态空间模型是:

我们形成变分状态空间模型:
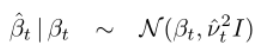
变分参数是![]() 和
和![]() 。使用标准卡尔曼滤波器计算(Kalman,1960),变分后验的前向均值和方差由下式给出:
。使用标准卡尔曼滤波器计算(Kalman,1960),变分后验的前向均值和方差由下式给出:

初始条件由固定的![]() 和
和![]() 指定。然后,后向递归计算给定
指定。然后,后向递归计算给定![]() 的
的![]() 的边际均值和方差:
的边际均值和方差:

初始条件为![]() 且
且![]() 。我们使用状态空间后验
。我们使用状态空间后验![]() 来近似后验
来近似后验![]() 。从Jensen的不等式来看,对数似然从下面被限制为:
。从Jensen的不等式来看,对数似然从下面被限制为:

2.2 Variational Wavelet Regression(变分小波回归)
变分卡尔曼滤波器可以用变分小波回归代替。 我们重新调整时间,使其在0和1之间。对于128年的科学,我们采用![]() 。为了与我们之前的符号一致,我们假设:
。为了与我们之前的符号一致,我们假设:

我们的变分小波回归算法估计 ,我们将其视为观测数据,就像在卡尔曼滤波器方法中一样,以及噪声水平ν。
,我们将其视为观测数据,就像在卡尔曼滤波器方法中一样,以及噪声水平ν。
为了具体,我们使用Haar小波基来说明该技术; Daubechies小波在我们的实际例子中使用。 然后是模型:

我们对后验均值的变分估计变为:
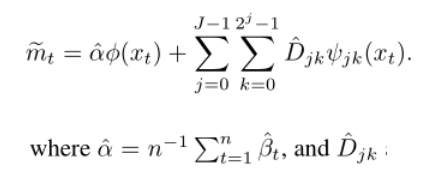
通过对系数进行阈值处理得到:
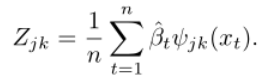
为了估计![]() ,我们使用梯度上升,对于卡尔曼滤波器近似,需要导数
,我们使用梯度上升,对于卡尔曼滤波器近似,需要导数 。如果使用软阈值,那么我们就有了:
。如果使用软阈值,那么我们就有了:

另请注意![]() 当且仅当
当且仅当![]() 这些衍生物可以使用现成的软件在任何标准小波基中进行小波变换计算。
这些衍生物可以使用现成的软件在任何标准小波基中进行小波变换计算。
下图中给出了运行此算法和卡尔曼变分算法以逼近单字母模型的样本结果。两个变分近似消除了单字组计数中的局部波动,同时保留了可能表明期刊内容发生重大变化的尖峰。 虽然拟合类似于使用标准小波回归到(正常化)计数所获得的拟合,但是通过最小化KL分歧来获得估计,如在标准变分近似中那样。

图形解释:卡尔曼滤波器(上)和小波回归(下)变分近似与单字母模型的比较。 变分近似(红色和蓝色曲线)平滑了所示单词的单字组计数(灰色曲线)中的局部波动,同时保留了可能表明日志中内容发生重大变化的尖峰。 小波回归能够“解析”20世纪20年代爱因斯坦出现的双峰值。
三、科学的分析
我们分析了来自Science的30,000篇文章的子集,来自1881年至1999年的120年中的250篇。我们的数据由JSTOR(www.jstor.org)收集,JSTOR是一个非营利组织,维护着一个在线学术档案库。 通过在原始印刷期刊上运行光学字符识别(OCR)引擎。 JSTOR对生成的文本进行索引,并通过关键字搜索提供对原始内容的扫描图像的在线访问。
我们的语料库由大约750万个单词组成。 我们通过将每个术语插入其根,删除函数术语以及删除少于25次的术语来修剪词汇表。 总词汇量为15,955。 为了探索语料库及其主题,我们估计了一个20分量的动态主题模型。 在1.5GHZ PowerPC Macintosh笔记本电脑上进行后推理约需4小时。 结果中的两个主题如图4所示,根据使用卡尔曼滤波器变分近似估计的后验平均出现次数,显示每十年中这些主题的前几个单词。 还示出了几十年来展示这些主题的示例文章。 如下图所示,该模型捕获不同的科学主题,并可用于检查其中的单词使用趋势。

图形解释:来自Science corpus估计的20主题动态模型的后验分析的例子。 对于两个主题,我们说明:(a)十年滞后推断的后验分布中的前十个词(b)来自同一两个主题的几个单词的年度函数的频率的后验估计(c)示例文章 整个集合展示了这些主题。 请注意,绘图是为了给出单词“后验概率”轨迹形状的概念。
为了定量验证动态主题模型,我们考虑了前几年所有文章预测下一年的科学任务。 我们比较了三个20个主题模型的预测能力:从前几年估计的动态主题模型,从前几年估计的静态主题模型,以及从单个前一年估计的静态主题模型。 估计所有模型具有相同的收敛标准。 从所有先前数据和动态主题模型估计的主题模型在同一点初始化。
动态主题模型表现良好; 与其他两个模型相比,它总是为下一年的文章指定更高的可能性,如下图所示。 有趣的是,多年来每种模型的预测能力都在下降。 我们可以暂时将其归因于科学语言专业化率的提高。

图形解释:该图说明了使用动态主题模型和静态主题模型进行预测的性能。 对于1900年到2000年之间的每年(以5年为增量),我们估计了那一年的三个模型。 然后,我们计算了在得到的模型下明年文章的负对数可能性的变分界限(较低的数字更好)。 DTM是动态主题模型; LDA-prev是仅在前一年的文章中估计的静态主题模型; LDA-all是所有先前文章中估计的静态主题模型。