剑指offer 33.二叉搜索树的后续遍历
题目描述:
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。
示例
参考以下二叉树:

示例1
输入:[1,6,3,2,5]
输出:false
示例2
输入:[1,3,2,6,5]
输出:true
解题思路:
- 根据二叉树后序遍历顺序“左,右,中”,对数组进行划分[left | right | root]。
- 二叉搜索树的定义:左子树的所有节点的值小于根节点的值,右子树的左右节点的值,大于根节点的值,并且左右子树也是搜索树。
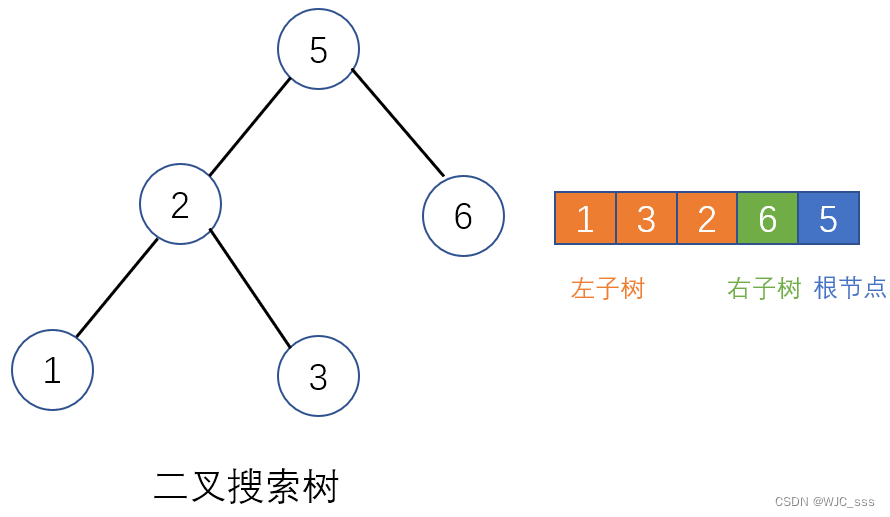
方法一:递归,分治
思路
-
根据二叉搜索树的定义,通过递归遍历,判断所有子树的正确性,
递归解析: -
终止条件:当 i > = j i >= j i>=j,说明此子树节点数量<= 1,无需判别正确性,直接返回 t r u e true true,
-
递推工作:
1.划分左右子树:从左向右遍历后续遍历的[i,j]区间元素,寻找第一个 大于根节点的元素,索引记为 m m m。此时,可划分出左子树区间 [ i , m − 1 ] [i,m-1] [i,m−1],右子树区间 [ m , j − 1 ] [m,j-1] [m,j−1],根节点索引为 j j j。
2.判断是否为二叉搜索树:(根据二叉搜索树的定义)- 左子树区间 [ i , m − 1 ] [i,m-1] [i,m−1]内所有节点都应 < p o s t e r d e r [ j ] <posterder[j] <posterder[j]。第一步在寻找第一个大于根节点的值索引的过程中,已经将左子树的节点值,判断完毕,因此接下来,不需要再重新比较。
- 右子树区间 [ m , j − 1 ] [m,j-1] [m,j−1],内所有节点值应$ > posterderp[]j , 从 索 引 ,从索引 ,从索引m+1$ 开始向右遍历,遇到第一个小于等于 p o s t e r d e r [ j ] posterder[j] posterder[j]的值,返回其索引 p p p,判断 p = = j p ==j p==j,若满足,则此区间为二叉搜索树。
-
所有子树都需判定正确,最后才能返回true;,因此使用&& 逻辑符连接:
1. p = = j p==j p==j,判断当前区间子树满足定义
2. t r a v e r s a l ( i , m − 1 ) traversal(i,m-1) traversal(i,m−1):判断此树的左子树是否正确。
3. t r a v e r s a l ( m , j − 1 ) traversal(m,j-1) traversal(m,j−1):判断右子树是否正确。
只有三者都为true时,才返回true。
代码段
class Solution{
public:
bool traversal(vector<int>& posterder,int i,int j){
if(i >= j) return true;
int p = i;
while(posterder[p] < posterder[j]) p++;
int m = p;
while(posterder[p] > posterder[j]) p++;
return (p==j) && traversal(posterder,i,m-1) && traversal(posterder,m,j-1);
}
bool verifyPosterder(vector<int>& posterder){
if(posterder.size() <= 1) return true;
return traversal(posterder,0,posterder.size()-1);
}
}
复杂度分析
- 时间复杂度: O ( N 2 ) O(N^2) O(N2):每次调用递归减去一个根节点,因此递归占用 O ( N ) O(N) O(N);最差情况下,当树退化为链表,每轮递归都需要遍历树的的所有节点,占用 O ( N ) O(N) O(N).
- 空间复杂度 O ( N ) O(N) O(N):最差情况下,当树退化为链表,递归深度达到 N N N。
方法二:单调栈
思路
- 此方法倒叙遍历数组,即[root | right | left]。
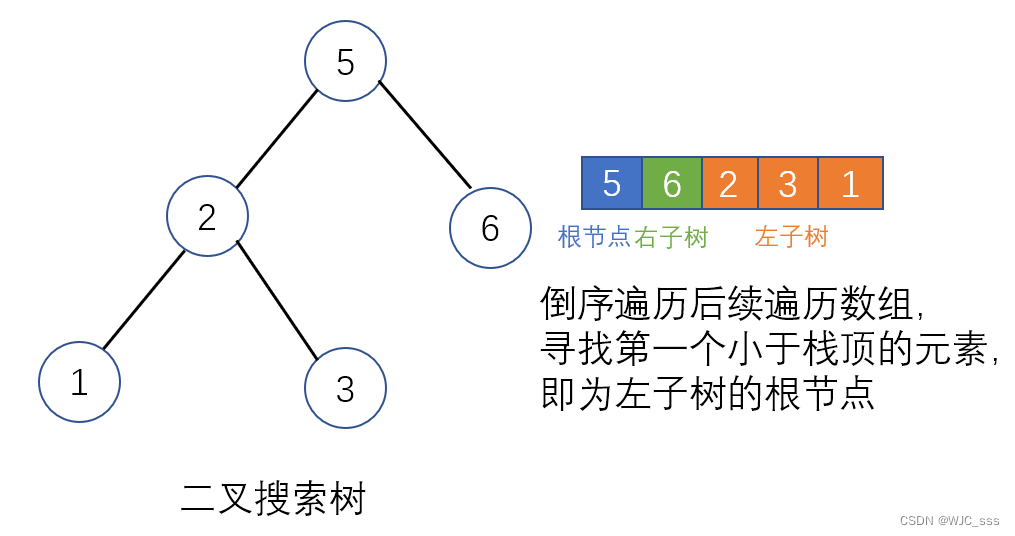
-
设后续遍历倒序 [ r n , r n − 1 , . . . r 1 ] [r_n,r_{n-1},...r_1] [rn,rn−1,...r1],遍历列表,设索引为 i i i,若为二叉搜索树,则有:
- 当节点值 r i > r i + 1 r_i >r_{i+1} ri>ri+1时:节点值 r i r_i ri一定是节点 r i + 1 r_{i+1} ri+1的右子节点。
- 当节点值 r i < r i + 1 r_i<r_{i+1} ri<ri+1时:节点值 r i r_i ri一定是root的左子节点,且root为节点值 r i + 1 , r i + 2 , . . . . r n r_{i+1},r_{i+2},....r_n ri+1,ri+2,....rn中的值大于且最接近 r i r_i ri的节点。
-
对于 r i < r i + 1 r_ i<r_{i+1} ri<ri+1,若为二叉搜索树,则 r i r_i ri右边的所有节点 [ r i − 1 , r i − 2 , . . . r 1 ] < r o o t [r_{i-1},r_{i-2},...r_1]<root [ri−1,ri−2,...r1]<root。
-
根据以上特点,使用单调栈作为辅助:
1.借助一个单调栈 s t a c k stack stack存储值递增的节点;
2.当遇到值递减的接单 r i r_i ri,则通过出栈来更新 r i r_i ri的父节点 r o o t root root;
3.每轮判断 r i r_i ri和 r o o t root root的值关系:
(1)若 r i > r o o t r_i >root ri>root,则不满足二叉树定义,返回false;
(2)若 r i < r o o t r_i<root ri<root,则继续遍历。
算法流程
1.初始化:单调栈stack,初始根节点为 r o o t = + ∞ root = +\infty root=+∞。(把树的根节点看作此无穷节点的左孩子);
2.倒序遍历 p o s t e r d e r posterder posterder记每个节点为 r i r_i ri;
- 判断,若 r i > r o o t r_i>root ri>root则不满足二叉搜索树的定义,返回false;
- 更新父节点 r o o t root root:当栈不为空,且 r i < s t a c k . t o p ( ) r_i<stack.top() ri<stack.top()时,循环执行出栈,并将出栈节点赋值给 r o o t root root。
- 入栈:将当前节点 r i r_i ri入栈。
3.遍历完成,返回true;
复杂度分析
- 时间复杂度 O ( N O(N O(N:遍历 p o s t e r d e r posterder posterder所有节点,各节点均入栈,/出栈一次,使用 O ( N ) O(N) O(N)时间。
- 空间复杂度 O ( N ) O(N) O(N):最差情况下,单调栈 s t a c k stack stack存储所有接单。使用 O ( N ) O(N) O(N)额外空间。
代码段
class Solution{
public:
bool verifyPostorder(vector<int> & postorder){
stack<int> st;
int root = INT_MAX;
for (int i = postorder.size()-1;i >= 0;i--){
if (postorder[i] > root) return false;
while(!st.empty() && st.top() > postorder[i]){
root = st.top();
st.pop();
}
st.push(postorder[i]);
}
return true;
}
};