0 Clip简介
参考:https://zhuanlan.zhihu.com/p/493489688
https://zhuanlan.zhihu.com/p/477760524?utm_campaign=shareopn&utm_medium=social&utm_oi=1495143076113260544&utm_psn=1621916856541024256&utm_source=wechat_session
论文:http://arxiv.org/abs/2112.05139
code:https://github.com/cassiePython/CLIPNeRF
CLIP(Contrastive Language–Image Pre-training)是OpenAI的第一篇多模态预训练的算法,是一个基于图像和文本并行的多模态模型,然后通过两个分支的特征向量的相似度计算来构建训练目标。为了训练这个模型,OpenAI采集了超过4亿的图像-文本对。CLIP在诸多多模态任务上取得了非常好的效果,例如图像检索,地理定位,视频动作识别等等,而且在很多任务上仅仅通过无监督学习就可以得到和主流的有监督算法接近的效果。CLIP的思想非常简单,但它仅仅通过如此简单的算法也达到了非常好的效果,这也证明了多模态模型强大的发展潜力。
数据集
为了学习到通用的图像-文本多模态通用特征,必须采集足够覆盖开放计算机视觉领域的数据集。OpenAI采集了一个总量超过4亿图像-文本对的数据集WIT(WebImage Text)。为了尽可能的提高数据集在不同场景下的覆盖度,WIT的首先使用在英文维基百科中出现了超过100次的单词构建了50万个查询,并且使用WordNet进行了近义词的替换。为了实现数据集的平衡,每个查询最多取2万个查询结果。
算法介绍
CLIP的核心思想是将图像和文本映射到同一个特征空间,希望通过对比学习,模型能够学到文本-图像对的匹配关系。这个特征空间是一个抽象的概念,例如当我们看到一条狗的图片的时候,我们心中想的是狗,当我们读到狗的时候我们想的也是狗,那么我们心中想象的狗,便是“特征空间”。
所以CLIP也是由两个编码器组成,如下图所示:
- 图像编码器 Image Encoder:用于将图像映射到特征空间,可以采用NLP中常用的text transformer模型;
- 文本编码器 Text Encoder:用于将文本映射到相同的特征空间,可以采用常用CNN模型或者vision transforme
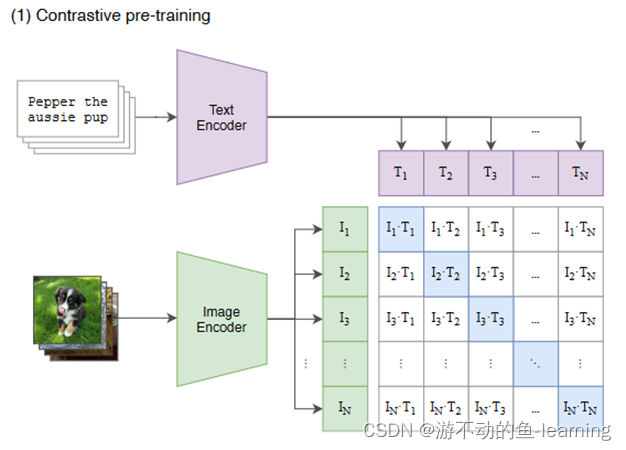
在模型训练过程中,我们取到的每个batch由N 个图像-文本对组成。这N 个图像送入到图像编码器中会得到 N 个图像特征向量 ( I 1 , I 2 , . . . , I N ) (I_1,I_2,...,I_N) (I1,I2,...,IN),同理将这 N 个文本送入到文本编码器中我们可以得到N个文本特征向量 ( T 1 , T 2 , . . . , T N ) (T_1,T_2,...,T_N) (T1,T2,...,TN)。因为只有在对角线上的图像和文本是一对,所以CLIP的训练目标是让是一个图像-文本对的特征向量相似度尽可能高,而不是一对的相似度尽可能低,这里相似度的计算使用的是向量内积,计算文本特征和图像特征的余弦相似性(cosine similarity)。通过这个方式,CLIP构建了一个由 N个正样本和 N 2 − N N^2-N N2−N 个负样本组成的损失函数。另外,因为不同编码器的输出的特征向量长度不一样,CLIP使用了一个线性映射将两个编码器生成的特征向量映射到统一长度。
优缺点
优点
- 训练高效
- 方便迁移
- 全局学习
缺点
- 数据集构建不全面,且未开源
- 通用效果
- 过分夸大zero-shot 学习能力
为什么可以用clip约束nerf的编辑?
验证clip提供的embedding是不是3D awareness,
实验:先针对两辆不同的车render出不同视角的图片,然后用clip计算图片间的cosine distance,发现同类型的车的cosine distance 距离更小,不同类型的车cosine distance更大。说明clip知道3D视角下的语义,即可以用来约束nerf。

1. 摘要
提出了一种神经辐射场(NeRF)的多模态3D目标操控方法,CLIP-NeRF。通过利用最近的对比文本-图像预训练(CLIP)模型的联合文本-图像嵌入空间,提出了一个统一的框架,可以用短文本提示或示例图像以用户友好的方式操控NeRF。
结合NeRF的新视图合成能力和生成模型潜表示的可控操纵能力,提出一种解缠的条件NeRF架构,允许对形状和外观进行单独控制。
这是通过对位置编码应用学习到的变形场来执行形状调节,并将颜色调节推迟到体积渲染阶段来实现的。
为了将这种解耦的潜在表示与CLIP嵌入连接起来,设计了两个代码映射器,它们将CLIP嵌入作为输入并更新潜在代码以反映目标编辑。映射器使用基于clip的匹配损失进行训练,以确保操作精度。
此外,论文提出了一种逆优化方法,准确地将输入图像投影到潜在代码中进行操作,以实现对真实图像的编辑。
实现流程

1.Introduction
神经辐射场(neural radiance fields, NeRF)利用体绘制技术渲染神经隐式表示,实现高质量的新视图合成,为3D内容提供了理想的表示。
编辑NeRF(例如,变形形状或改变外观颜色)极具挑战性,主要原因:
- NeRF是每个场景优化的隐式函数,不能使用直观的工具直接编辑形状来实现显式表示;
- 与单视图信息就足以指导编辑的图像操作不同,NeRF的多视图依赖性使得没有多视图信息的操作方式更难控制。
Condition nerf(条件nerf)在一类形状上训练NeRF,并利用预先训练的模型通过潜在空间插值进行操作。编辑给定用户涂鸦的NeRF的形状和颜色。然而,由于它在形状操作方面的能力有限,只允许添加或删除对象的局部部分。
1.1 主要贡献
贡献点:
- 提出第一种NeRF的文本和图像驱动的操作方法,使用统一的框架为用户提供使用文本提示或示例图像对3D内容的灵活控制。
- 通过引入形状码来变形体积场和外观代码来控制发出的颜色,设计了一种解缠的条件NeRF架构。
- 与基于优化的编辑方法相比,前馈代码mapper能够快速推理编辑同一类别中的不同对象。
- 提出一种反演方法,从真实图像中推断形状和外观代码,允许编辑现有数据的形状和外观。
1.2 相关工作
NeRF在捕捉高分辨率几何图形和渲染照片逼真的新视图方面能力十分强大,目前已扩展到动态场景、新光照条件下的重光照、生成模型等等。
1.2.1 nerf 相关
- DietNeRF 设计了CLIP语义一致性损失来改善少射NeRF,并给出了令人印象深刻的结果;
- GRAF 首先采用形状和外观代码有条件地合成NeRF;
- EditNeRF 定义了一个条件NeRF,其中由NeRF编码的3D对象以形状代码和外观代码为条件。通过优化这两个潜码的调整,可以实现用户对形状和外观颜色的编辑。然而,这种方法在形状操作方面的能力有限,因为它只支持添加或删除对象的局部部分,而且编辑速度很慢。
1.2.2 本文工作与EditNeRF的区别
- 提供了更自由的形状操作和支持全局变形;
- 通过学习两个前馈网络将用户编辑映射到潜在代码,我们的方法可以快速推断交互编辑;
- 与EditNeRF中使用的用户涂鸦不同,我们介绍了两种直观的NeRF编辑方法:使用短文本提示或示例图像,这对新手用户更友好。
1.2.3 clip 相关
clip以一种对比学习的方式,将文本和图像在共享的潜在空间中更紧密地连接起来。
- **StyleClip ** 结合CLIP和StyleGAN,根据CLIP空间中定义的文本条件,通过优化预训练StyleGAN的潜在代码来合成图像。StyleCLIP没有从头生成图像,而是为StyleGAN引入了一个基于文本的接口,允许使用文本提示操作真实图像。
- **DiffusionCLIP **将扩散模型与CLIP结合起来进行文本驱动的图像处理。该方法的性能与基于gan的图像处理方法相当,具有较大的模式覆盖率和训练稳定性。
上述操作都只利用了clip的文本引导能力,本文工作将文本驱动和图像驱动操作统一在一个模型中,且上述模型都局限于图像处理,缺乏3D信息,不能促进多视图一致性研究,本文工作结合nerf和clip,可以以视图一致的方式编辑3D模型。
2 方法
2.1 Conditional NeRF
建立在原始的每个场景NeRF之上,conditional NeRF service作为特定对象类别的生成模型,以专门控制形状和外观的潜向量为条件。conditional NeRF表示为一个连续的体函数 F θ F_θ Fθ ,它将5D坐标(空间位置 X (x, y, z)和视图方向V(φ, θ)),以及形状代码 z s z_s zs和外观代码 z a z_a za映射到体密度 σ 和依赖于视图的辐射度 c(r, g, b),由多层感知器(MLP)参数化。其简单公式为:

其中⊕是连接运算符。
Γ ( p ) = { Γ ( p ) ∣ p ∈ p } Γ (p) = \left\{Γ (p) | p∈p\right\} Γ(p)={
Γ(p)∣p∈p}是将向量p的每个坐标p分别投影到高维空间的正弦位置编码。编码函数 γ ( ⋅ ) : R → R 2 m γ(·):R→R^{2m} γ(⋅):R→R2m的每个输出维数定义为:

其中k∈{0,…, 2m−1},m是控制频带总数的超参数。
2.2 Disentangled Conditional NeRF
conditional NeRF确实为NeRF架构引入了条件生成功能,但其易受到形状和外观条件之间的相互干预,例如,操纵形状代码也可能导致颜色变化。为此,论文提出解纠缠条件NeRF架构,通过适当解纠缠条件机制来实现对形状和外观的单独控制。
2.2.1 Conditional Shape Deformation
不直接将潜在的形状代码与编码的位置特征连接,而是通过对输入位置的显式体积变形来表达形状条件。这种条件形状变形不仅提高了操作的鲁棒性,而且通过正则化输出形状为基本形状的平滑变形,尽可能地保留了原始形状的细节,更重要的是完全隔离了形状条件对外观的影响。
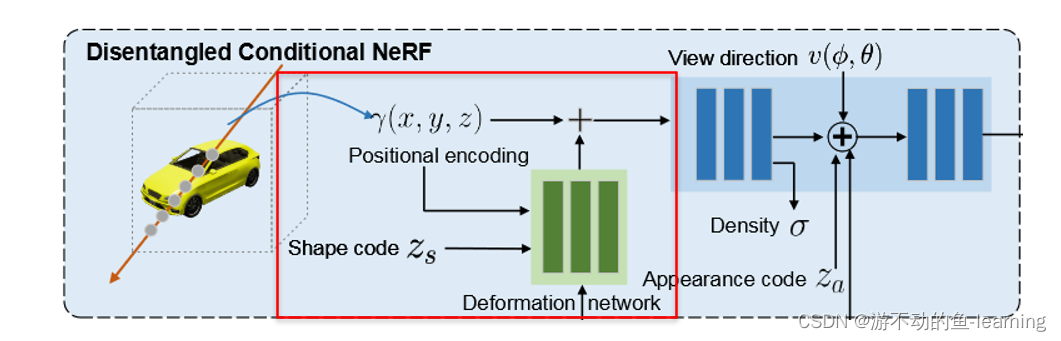
shape deformation network
Γ : ( x , z s ) → Δ x \Gamma : (x,z_s) \to \Delta x Γ:(x,zs)→Δx将位置x 和输入 z s z_s zs 投射到与位置编码 Γ ( x ) \Gamma(x) Γ(x)是对应位置编码的位移向量 Δ x ∈ R 3 × 2 m Δx∈R^{3×2m} Δx∈R3×2m
deformed positional encoding
Γ ∗ ( P , z s ) = γ ∗ ( p , Δ p ) ∣ p ∈ P , Δ p ∈ Γ ( p , z s ) Γ^∗(P,z_s)={γ^∗(p,Δp)∣p∈P,Δp∈Γ(p,z_s)} Γ∗(P,zs)=γ∗(p,Δp)∣p∈P,Δp∈Γ(p,zs),
其中标量p和向量 ∆ p ∈ R 2 m ∆p∈R^{2m} ∆p∈R2m, p和∆p都属于同一轴。使用双曲正切函数tanh(·)将位移约束在[- 1,1]范围内,避免了大运动导致的局部极小值较差,提高了训练的鲁棒性。
Deferred Appearance Conditioning(延迟外观调节)
在NeRF中,密度首先作为位置的函数进行预测,然后从位置和视图方向预测颜色。与Graf和EditNeRF类似,我们也延迟外观调节,将外观代码与视图方向连接起来,作为颜色预测网络的输入,这允许在不触及形状信息(即密度)的情况下操纵外观。

解纠缠的条件NeRF Fθ(·)定义为:

为了简便起见,使用 F θ ( v , z s , z a ) = { F θ ( x , v , z s , z a ) ∣ x ∈ R } F_θ (v, z_s, z_a) =\left\{F_θ (x, v, z_s, z_a) | x∈R\right\} Fθ(v,zs,za)={
Fθ(x,v,zs,za)∣x∈R}来表示整个图像在窗口R下的渲染。
2.3 CLIP-Driven Manipulation
用解耦的条件nerf eq4 作为生成器,同时优化每个目标样本的形状和外观代码往往是通用的和耗时的,为避免这个问题,我们采用前馈方法,直接从输入文本提示符更新条件代码。
给定输入文本提示 t 和 初始形状/外观代码 z s ′ / z a ′ z'_s/z'_a zs′/za′,训练形状mapper M s M_s Ms和外观mapper(映射器) M a M_a Ma

ε^(⋅)是预训练的CLIP文本编码器,将文本投影到CLIP嵌入特征空间,两个mapper都将该CLIP嵌入映射到更新原始形状和外观代码的位移向量。
CLIP包括一个图像编码器和一个映射到联合嵌入空间的文本编码器,使用 跨模态 cross-modal CLIP距离函数 D C L I P ( ⋅ , ⋅ ) D CLIP (·,·) DCLIP(⋅,⋅)来衡量输入文本和已渲染图像块之间的嵌入相似性:

ε ^ i ( ⋅ ) \hat{\varepsilon}_i(\cdot) ε^i(⋅)和 ε ^ t ( ⋅ ) \hat{\varepsilon}_t(\cdot) ε^t(⋅)是预训练的剪辑图像和文本编码器,I 和 t 是输入图像块和文本,<·,·>是余弦相似度算子。

要使用图像级CLIP模型进行NeRF操作,一个自然的问题是CLIP特征在不同视角上是否稳定(是否具有3Dawareness ),以及它是否能区分对象差异。
做上图所示验证,先针对两辆不同的车render出不同视角的图片,然后用clip计算图片间的cosine distance,发现同类型的车的cosine distance 距离更小,不同类型的车cosine distance更大。说明clip知道3D视角下的语义,即可以用来约束nerf。
2.4 训练过程
训练过程分两步:
- 首先训练解纠缠的条件NeRF,包括conditional NeRF生成器和deformation network;
- 固定生成器的权重,训练包括形状和外观mapper的CLip操作部分
2.4.1 Disentangled Conditional NeRF
条件NeRF生成器 F θ F_\theta Fθ与deformation network一起训练,使用非饱和(non-saturatong)GAN目标和鉴别器D,其中 f ( x ) = − l o g ( 1 + e x p ( − x ) ) f (x) =−log (1 + exp(−x)) f(x)=−log(1+exp(−x))和 λ r λ_r λr是正则化权值。假设实景图像i形成d的训练数据分布,我们分别从 Z s 、 Z a Z_s、Z_a Zs、Za和 Z v Z_v Zv中随机采样形状代码 z s z_s zs、外观代码 z a z_a za和摄像机姿态,其中 Z s Z_s Zs和 Z a Z_a Za为正态分布, Z v Z_v Zv为摄像机坐标系的上半球。

2.4.2 CLIP Manipulation Mappers
使用预训练的NeRF生成器Fθ, CLIP编码器 { ε ^ i , ε ^ t } \left\{\hat{\varepsilon}_i, \hat{\varepsilon}_t\right\} {
ε^i,ε^t}和鉴别器D来训练CLIP形状映射器Ms和外观映射器Ma。除了映射器之外,所有的网络权重都是固定的,记为 { ⋅ ^ } \left\{\hat{\cdot} \right\} {
⋅^}。与第一阶段类似,我们从它们各自的分布中随机采样形状代码zs、外观代码za和相机姿态v。此外,我们从预定义的文本库t中采样文本提示符t。通过使用权重为λc的 CLIP distance DCLIP ,用以下损失来训练映射器:

2.5 Inverse Manipulation (逆操作)
要将操作应用于属于同一训练类别的输入图像 I r I_r Ir,关键是首先优化所有生成条件,以将图像反向投影到生成流形,类似于latent image manipulation方法。在EM算法的基础上,设计了一种迭代算法来交替优化形状码zs,外观码za,和相机姿态v。
具体而言,在每次迭代中,我们首先优化v,同时保持zs和za固定,使用以下损失:

接着优化形状码zs

其中za和v固定,zn为每一步采样的随机标准高斯噪声向量,以提高优化的鲁棒性,λn在整个优化迭代过程中从1线性衰减到0。
同理优化外观码za

3 实验
3.1 数据集
使用两个公开数据集:
- Photoshapes 在128x128渲染150k椅子
- carla 在256x256上渲染10k汽车
每个对象在一个随机视图中呈现,不提供任何相机姿态参数
3.2 实现细节
- 条件NeRF结构
8层MLP,每层包含256个隐藏单元,输入维数为64。遵循NeRF的默认架构,其中也使用了ReLU激活函数。
- deformation network
具有ReLU激活和每层256个隐藏单元的4层MLP。它以128维形状代码zs作为输入,zs∈R128。我们也用128维表示外观代码za,za∈R128。
- 形状和外观映射器
都是带有ReLU激活的2层mlp。每个mapper的通道大小分别为128、256和128。
- 鉴别器D
基于patchGAN
- 超参数设置
使用Adam优化器 , 初始学习率为10−4 ,学习率每50K步衰减0.5
λr = 0.5, λv = 0.1,λs = λa = 0.2。所有模型都在NVIDIA V100 GPU平台上进行训练。
3.3 与EditNERF比较
如图3 对两个数据集的形状和外观颜色的编辑进行对比
对于Photoshapes数据集,EditNeRF使用600个实例训练,每个实例有40个视图,而我们的只使用一个视图。对于Carla数据集,EditNeRF使用10K汽车,每个实例有一个视图,与我们的相同。另外,EditNeRF训练过程中需要的摄像机位姿参数是我们不知道的。

对于颜色编辑, 我们观察到EditNeRF的编辑结果出现了不自然的颜色效果(例如车门上的不连续),生成的颜色并不完全符合于目标颜色。相比之下,我们允许用户通过提供文本提示来更简单地更改颜色,并且我们的方法产生了更自然的编辑结果
对于形状编辑,EditNeRF只能支持局部形状编辑,例如形状部分删除。给定用户的编辑涂鸦,例如,指示删除椅子的腿(在红色矩形中),EditNeRF优化网络中的几个层以适应输入视图中的形状,但它不能确保成功传播到未见的视图(在蓝色矩形中),并保持其他部分的结构完整(在绿色矩形中)。与之相比,我们的方法支持较大程度的形状变形,并很好地推广到未见的视图。
此外,EditNeRF作为一种基于优化的方法,需要花费大量的时间进行优化,而我们的前馈代码映射器可以更快地推断目标形状和外观(见下表)。

3.4 消融实验
- editnerf
- 无解纠缠(w/o disen)
- 基线方法(w/o CLIP)
- clip-nerf


我们的方法支持使用文本编辑对象的形状或外观。在操作形状时,我们保持外观代码不变,这同样适用于外观编辑。
实景图像处理
为了评估我们的模型在处理训练集中不存在的单个实景图像时的泛化能力,我们对实景图像进行实验,将其转化为形状代码和外观代码,然后应用它们进行编辑。我们将颠倒和编辑的结果显示在图8中。我们观察到,颠倒椅子比颠倒汽车更具挑战性,因为椅子的结构很精致,比如办公椅的轮子。然而,即使办公椅没有被完美地重建,我们的方法的编辑能力也不受影响。我们的方法仍然确保在形状和外观上的准确编辑。

4 扩展讨论
- Continuous Manipulation
给定单个文本提示或示例,本文的方法支持编辑形状和外观,这可以通过连续编辑形状和外观来实现,即,首先编辑形状,然后编辑颜色,反之亦然。
- Fine-grained appearance manipulation within a same color category
不能处理限制中所述的细粒度局部部件形状和外观编辑,但它支持整个对象级别的细粒度外观操作,
- Necessity of latent space
本文算法使用设计的CLIP约束对条件NeRF模型的潜在空间执行形状和外观编辑。一个问题出现了,潜在空间是否必要,即,是否有可能直接编辑单个NeRF模型的形状和外观,而不是一个有条件的NeRF?
5 局限性
通过对各种文本提示和示例图像的广泛实验来评估我们的方法,并为交互式编辑提供了直观的编辑界面。
但是,由于潜在空间和预训练clip的表现能力有限,本文方法无法处理局部细粒度和域外的形状和外观编辑。如下图所示;
