Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
0. Abstract
Problem introduction:
When training or testing images to observe scene content at different resolutions, NeRF may produce blurred or aliased rendering.
Solutions:
Mip-NeRF renders anti-aliased conical frustums(锥形视锥体) instead of rays.
Effect(Experiment):
- Be 7% faster than NeRF and half the size
- Reduces average error rates by 17% on the dataset presented with NeRF and by 60% on a challenging multiscale variant of that dataset that we present.
- Able to match the accuracy of a brute-force supersampled NeRF on our multiscale dataset while being 22× faster.(It’s a traditional method we may first think to solve the problem of blurred rendering caused by different resolutions.)
5. Conclusion
The process: Mip-NeRF casts cones, encodes the positions and sizes of conical frustums, and trains a single neural network that models the scene at multiple scales.
1. Introduction
Problem introduction:
When the training images observe scene content at multiple resolutions, renderings from the recovered NeRF appear excessively blurred in close-up views and contain aliasing artifacts in distant views.
The input contains different scales so there are some problems in rendering.
Traditional method:
A straightforward solution is to adopt the strategy used in offline raytracing: supersampling each pixel by marching multiple rays through its footprint.
This paper:
Take inspiration from the mipmapping approach: A mipmap represents a signal (typically an image or a texture map) at a set of different discrete downsampling scales and selects the appropriate scale to use for a ray based on the projection of the pixel footprint onto the geometry intersected by that ray.
传统方法和mip的方法都出自图形学的知识[1]. Mip来源于拉丁语*multum in parvo:放置很多东西的小空间 。*在 computer graphics中mipmapping是一种加快渲染速度、减少图像锯齿的贴图渲染技术。简单说,mipmapping就是把主图缩小成一系列依次缩小的小图片,并把这些更低解析度的小图片保存起来,这种策略被称为pre-filtering。抗锯齿的计算负担都集中在预处理上:不论之后需要对一个texture做多少次渲染,都只需要预处理一次即可。
3. Method
对于Mip-NeRF而言,主要的创新点分为三个方面:
- Mip-NeRF的渲染过程是基于抗锯齿的圆锥体(anti-aliased conical frustums);
- Mip-NeRF提出了新的位置编码的方法——IPE(Integrated Positional Encoding);
- Mip-NeRF将coarse和fine的MLP减少到一个单一的多尺度MLP(a single multiscale MLP);
3.1. Cone Tracing and Positional Encoding
3.1.1 Cone Tracing

给定相机中心 o \mathbf{o} o与相机方向 d \mathbf{d} d,根据图片中待求的像素点向外发出圆锥,圆锥的大小被像素大小限制,在像素平面上定义为: r ˙ = 2 12 ∗ the width of the pixel \dot{r}=\frac{2}{\sqrt{12}}*\text{the width of the pixel} r˙=122∗the width of the pixel
我们可使用下面的公式判断查询点是否位于圆锥内部(输入为边界 [ t o , t 1 ] [t_o,t_1] [to,t1]与限制半径 r ˙ \dot{r} r˙):
F ( x , o , d , r ˙ , t 0 , t 1 ) = 1 { ( t 0 < d T ( x − o ) ∥ d ∥ 2 2 < t 1 ) ∧ ( d T ( x − o ) ∥ d ∥ 2 ∥ x − o ∥ 2 > 1 1 + ( r ˙ / ∥ d ∥ 2 ) 2 ) } , \begin{gathered} \mathrm{F}(\mathbf{x},\mathbf{o},\mathbf{d},\dot{r},t_{0},t_{1})=1{\Bigg\{}\left(t_{0}<{\frac{\mathbf{d}^{\mathrm{T}}(\mathbf{x}-\mathbf{o})}{\left\|\mathbf{d}\right\|_{2}^{2}}}<t_{1}{\Bigg)}\right. \\ \left.\wedge\left({\frac{\mathbf{d}^{\mathrm{T}}(\mathbf{x}-\mathbf{o})}{\|\mathbf{d}\|_{2}\|\mathbf{x}-\mathbf{o}\|_{2}}}>{\frac{1}{\sqrt{1+(\dot{r}/\|\mathbf{d}\|_{2})^{2}}}}\right)\right\}, \end{gathered} F(x,o,d,r˙,t0,t1)=1{
(t0<∥d∥22dT(x−o)<t1)∧(∥d∥2∥x−o∥2dT(x−o)>1+(r˙/∥d∥2)21)},
这个公式有两个限制,第一部分是在 d d d方向上,即 x − o \mathbf{x}-o x−o在 d d d方向的投影不能超过 [ t o , t 1 ] [t_o,t_1] [to,t1]的限制;第二部分是在角度方向上,即不能超过锥形的角度限制。
之后我们讨论如何对这个圆台进行编码,作者说他们发现的最简单的是对于整个圆台的点求期望。
为了便于计算并且得到收敛解,首先使用三维高斯分布来拟合这样的一个圆台,使得我们仅使用平均值和协方差矩阵就能表征这样一个圆台。
这种高斯模型完全由3个值来表示: μ t \mu_t μt(沿射线的平均距离)、 σ t 2 \sigma^2_t σt2(沿射线方向的方差)、 σ r 2 \sigma^2_r σr2(沿射线垂直方向的方差)
μ t = t μ + 2 t μ t δ 2 3 t μ 2 + t δ 2 , σ t 2 = t δ 2 3 − 4 t δ 4 ( 12 t μ 2 − t δ 2 ) 15 ( 3 t μ 2 + t δ 2 ) 2 σ r 2 = r ˙ 2 ( t μ 2 4 + 5 t δ 2 12 − 4 t δ 4 15 ( 3 t μ 2 + t δ 2 ) ) . \begin{aligned}\mu_t&=t_\mu+\frac{2t_\mu t_\delta^2}{3t_\mu^2+t_\delta^2},\quad\sigma_t^2=\frac{t_\delta^2}{3}-\frac{4t_\delta^4(12t_\mu^2-t_\delta^2)}{15(3t_\mu^2+t_\delta^2)^2}\\\sigma_r^2&=\dot{r}^2\left(\frac{t_\mu^2}{4}+\frac{5t_\delta^2}{12}-\frac{4t_\delta^4}{15(3t_\mu^2+t_\delta^2)}\right).\end{aligned} μtσr2=tμ+3tμ2+tδ22tμtδ2,σt2=3tδ2−15(3tμ2+tδ2)24tδ4(12tμ2−tδ2)=r˙2(4tμ2+125tδ2−15(3tμ2+tδ2)4tδ4).
其中, t μ = ( t 0 + t 1 ) t_{\mu}=(t_{0}+t_{1}) tμ=(t0+t1), t δ = ( t 1 − t 0 ) / 2 t_\delta=(t_1-t_0)/2 tδ=(t1−t0)/2。
这样,给定输入(边界 [ t o , t 1 ] [t_o,t_1] [to,t1]与限制半径 r ˙ \dot{r} r˙),就可以求出用于近似此圆台的 μ \mu μ和 σ \sigma σ
紧接着可以将这个高斯模型从圆锥台的坐标系转换成世界坐标,得到最终的多元高斯模型:
μ = o + μ t d , Σ = σ t 2 ( d d T ) + σ r 2 ( I − d d T ∥ d ∥ 2 2 ) \mathbf{\mu}=\mathbf{o}+\mu_t\mathbf{d},\quad\mathbf{\Sigma}=\sigma_t^2(\mathbf{d}\mathbf{d}^\mathrm{T})+\sigma_r^2\bigg(\mathbf{I}-\frac{\mathbf{d}\mathbf{d}^\mathrm{T}}{\|\mathbf{d}\|_2^2}\bigg) μ=o+μtd,Σ=σt2(ddT)+σr2(I−∥d∥22ddT)
3.1.2 Positional Encoding
在Nerf中的位置编码为:
γ ( x ) = [ sin ( x ) , cos ( x ) , … , sin ( 2 L − 1 x ) , cos ( 2 L − 1 x ) ] T \gamma(\mathbf{x})=\left[\sin(\mathbf{x}),\cos(\mathbf{x}),\ldots,\sin(2^{L-1}\mathbf{x}),\cos(2^{L-1}\mathbf{x})\right]^\mathrm{T} γ(x)=[sin(x),cos(x),…,sin(2L−1x),cos(2L−1x)]T
我们用矩阵的形式重新表示一下:
P = [ 1 0 0 2 0 0 ⋯ 2 L − 1 0 0 0 1 0 0 2 0 ⋯ 0 2 L − 1 0 0 0 1 0 0 2 ⋯ 0 0 2 L − 1 ] T , γ ( x ) = [ sin ( P x ) cos ( P x ) ] . \mathbf{P}=\begin{bmatrix}1&0&0&2&0&0&\cdots&2^{L-1}&0&0\\0&1&0&0&2&0&\cdots&0&2^{L-1}&0\\0&0&1&0&0&2&\cdots&0&0&2^{L-1}\end{bmatrix}^T,\gamma(\mathbf{x})=\begin{bmatrix}\sin(\mathbf{Px})\\\cos(\mathbf{Px})\end{bmatrix}. P=
100010001200020002⋯⋯⋯2L−10002L−10002L−1
T,γ(x)=[sin(Px)cos(Px)].
利用矩阵形式对之前的高斯模型进行位置编码,期望和方差变为:
μ γ = P μ , Σ γ = P Σ P T . \mu_{\gamma}=\mathrm{P}\mu,\quad\Sigma_{\gamma}=\mathrm{P}\Sigma\mathrm{P}^{\mathrm{T}}. μγ=Pμ,Σγ=PΣPT.
而初始的高斯分布下,sin(x)和cos(x)的期望可表示为:
E x ∼ N ( μ , σ 2 ) [ sin ( x ) ] = sin ( μ ) exp ( − ( 1 / 2 ) σ 2 ) , E x ∼ N ( μ , σ 2 ) [ cos ( x ) ] = cos ( μ ) exp ( − ( 1 / 2 ) σ 2 ) . \begin{aligned}\operatorname{E}_{x\sim\mathcal{N}(\mu,\sigma^2)}[\sin(x)]&=\sin(\mu)\exp\bigl(-(^1/2)\sigma^2\bigr),\\\operatorname{E}_{x\sim\mathcal{N}(\mu,\sigma^2)}[\cos(x)]&=\cos(\mu)\exp\bigl(-(^1/2)\sigma^2\bigr).\end{aligned} Ex∼N(μ,σ2)[sin(x)]Ex∼N(μ,σ2)[cos(x)]=sin(μ)exp(−(1/2)σ2),=cos(μ)exp(−(1/2)σ2).
在现有条件下,考虑到我们表示出的均值和协方差矩阵,最终的位置编码后的高斯模型(IPE)可表示为:
γ ( μ , Σ ) = E x ∼ N ( μ γ , Σ γ ) [ γ ( x ) ] = [ sin ( μ γ ) ∘ exp ( − ( 1 / 2 ) d i a g ( Σ γ ) ) cos ( μ γ ) ∘ exp ( − ( 1 / 2 ) d i a g ( Σ γ ) ) ] \begin{aligned} \gamma(\boldsymbol{\mu},\boldsymbol{\Sigma})& =\mathrm{E}_{\mathbf{x}\sim\mathcal{N}(\boldsymbol{\mu}_{\gamma},\boldsymbol{\Sigma}_{\gamma})}[\gamma(\mathbf{x})] \\ &=\begin{bmatrix}\sin(\boldsymbol{\mu}_\gamma)\circ\exp(-(1/2)\mathrm{diag}(\boldsymbol{\Sigma}_\gamma))\\\cos(\boldsymbol{\mu}_\gamma)\circ\exp(-(1/2)\mathrm{diag}(\boldsymbol{\Sigma}_\gamma))\end{bmatrix} \end{aligned} γ(μ,Σ)=Ex∼N(μγ,Σγ)[γ(x)]=[sin(μγ)∘exp(−(1/2)diag(Σγ))cos(μγ)∘exp(−(1/2)diag(Σγ))]
在计算时可进行简化:
diag ( Σ γ ) = [ diag ( Σ ) , 4 diag ( Σ ) , … , 4 L − 1 diag ( Σ ) ] T \operatorname{diag}(\boldsymbol{\Sigma}_{\gamma})=\Big[\operatorname{diag}(\boldsymbol{\Sigma}),4\operatorname{diag}(\boldsymbol{\Sigma}),\ldots,4^{L\boldsymbol{-}1}\operatorname{diag}(\boldsymbol{\Sigma})\Big]^{\mathrm{T}} diag(Σγ)=[diag(Σ),4diag(Σ),…,4L−1diag(Σ)]T
diag ( Σ ) = σ t 2 ( d ∘ d ) + σ r 2 ( 1 − d ∘ d ∥ d ∥ 2 2 ) \operatorname{diag}(\boldsymbol{\Sigma})=\sigma_t^2(\mathbf{d}\circ\mathbf{d})+\sigma_r^2\biggl(\mathbf{1}-\frac{\mathbf{d}\circ\mathbf{d}}{\left\|\mathbf{d}\right\|_2^2}\biggr) diag(Σ)=σt2(d∘d)+σr2(1−∥d∥22d∘d)
3.2 Architecture
Mipnerf和Nerf仅有锥体追踪和IPE编码上的不同,现就这两方面进行对比:

3.2.1 Why Muti-resolution
在Nerf中,采样是基于射线上的点来的,之后查询点的信息即可进行渲染。在Mipnerf中,利用了锥形,而采样出来的点就是圆台的两个边界,如上图右边所示,在第一个点和第二个点之间建立圆台,图上是一个椭圆形状,这个就是三维高斯在这一方向上的分布。而这种编码及采样方式也就是mipnerf学习多尺度的能力:显式地将尺度编码到输入特性,进而让网络去学习。这也就是图里所说的mipnerf可以利用体积的这种能力,使他比nerf拥有更好的抗混叠效果。

3.2.2 High-frequency information
对于超参数 L L L的问题,体现了mipnerf对于高频信息的处理能力。

由图中可以看出,当L增大时,高频信息增加,Nerf效果也急剧下降了,然而mipnerf却能保持不变,这是因为随着采样空间的变大,高频信息会被平滑掉(具体原理我还不明白),可参照下面这张动图:
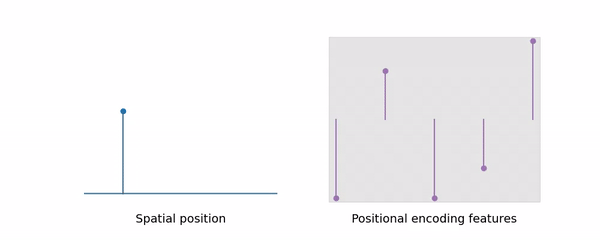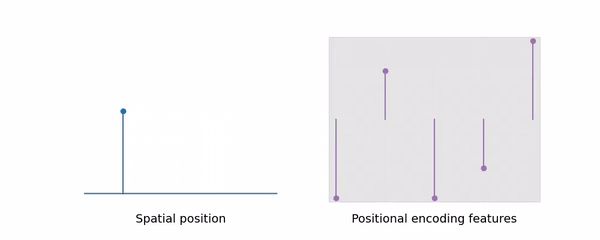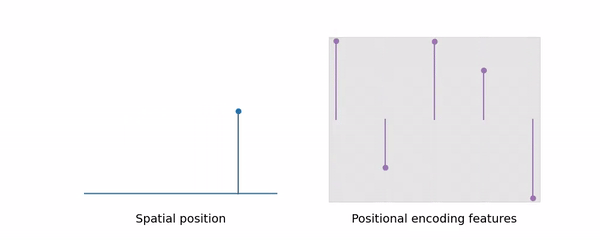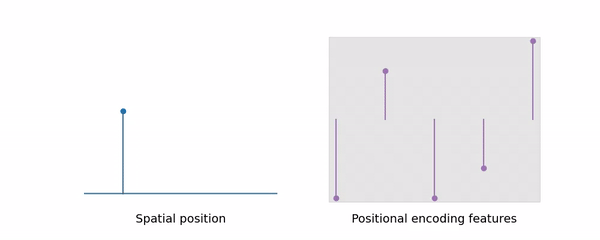

这种锥形的动态的设置,使得mipnerf处理远景自动过滤高频信息,缓解了锯齿现象(即去除了景象中的高频分量),处理近景时恢复对高频信息的处理。
3.2.3 Different sampling
在之前的Nerf中,需要进行粗细两层网络的采样,并放到两个MLP中计算得到统一的损失函数,现在借助于mipnerf处理多尺度的能力,只需要一个MLP就可以完成自适应的这个工作。
总的来说,Mipnerf借助锥形编码的体积可表示性,完成了对多尺度的学习,达到了更好的抗混叠效果
Reference
[1] 计算机图形学七:纹理映射(Texture Mapping)及Mipmap技术 - 知乎 (zhihu.com)
[2] Mip-NeRF论文笔记 - 知乎 (zhihu.com)
[3] [Review] Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields (velog.io)