题目:Removing Objects From NeRF 从神经辐射场中移除对象
论文:https://arxiv.org/abs/2212.11966
作者:Silvan Weder,Guillermo Niantic, ETH Zurich, University College London, nianticlabs.github.ionerf-object-removal
文章目录
摘要
nerf 正在成为一种常用的三维场景表示方法,允许新的视图合成。使用nerf进行三维重建时,需要删除个人信息或难看的对象。使用NeRF编辑框架并不容易实现这种删除,因此提出从RGBD序列创建的NeRF表示中删除对象。我们的NeRF绘制方法利用了最近在二维图像绘制中的工作,并由用户提供的mask 指导。我们的算法是基于一个基于置信度的视图选择程序。它选择在创建NeRF中使用哪个单独的2D绘制图像,以便生成的绘制NeRF是3D一致的。我们表明,我们的NeRF编辑方法是有效的合成可信的 inpainting 且多视角一致的方式。我们使用一个新的和仍然具有挑战性的数据集来验证我们的方法的NeRF内部绘制任务。
提示:以下是本篇文章正文内容
一、前言
自从神经辐射场首次发表以来,对原始框架的扩展出现了爆炸式增长。nerf的使用超出了新视图合成的最初任务。它已经融入了新手的应用程序手中,例如,在NeRF编辑或实时捕获和训练。其中,删除场景的部分是可取的。例如,在房产销售网站上共享的房屋扫描可能需要使用不具吸引力或个人可识别的物品来删除。类似地,在增强现实应用程序中,物体也可以被移除以被替换,例如,从扫描中移除一把椅子,看看一把新椅子如何适应环境。
一些对nerf 的编辑的工作已经出现。例如,以对象为中心的表示从背景中分离出有标记的对象,这允许使用user-guided transformations,来编辑训练过的场景;语义分解允许对场景的某些语义部分进行选择性编辑和透明化。然而,这些方法只是增加了来自输入扫描的信息,限制了它们的生成能力,即从任何角度都没有观察到的元素的错觉。去除物体同时,填充产生的空洞,解决这个问题需要: a)当场景的部分在某些帧中被观察到,但在其他帧中被遮挡时,能利用多视图信息,b)利用生成过程来填充从未被观察到的区域。为此,我们将nerf的多视图一致性与在大规模二维图像数据集上训练的二维内绘制模型的生成能力进行配对。这种二维内画不是多视图一致的结构,并可能包含严重的人工制品。这导致了损坏的重建,因此我们设计了一个新的基于置信度的视图选择方案,迭代地从优化中删除不一致的 inpainting,产生了多视图一致的结果。

贡献:
1.我们提出了第一种方法,通过利用单个图像 inpainting的力量来 inpainting NeRF。
2.一种新的视图选择机制,它可以自动从优化中删除不一致的视图。
3.提出了一个新的数据集来评估室内和室外的物体去除和绘画场景
二、相关工作
图像修复(inpainting)。其制解决了在单一图像中合理地填充缺失区域的问题。一种典型的方法是使用具有对抗性损失的image-to-image 网络,或使用扩散模型。人们提出了不同的方法来编码输入图像,例如,使用掩蔽或傅里叶卷积。然而,这些方法并没有给出视频帧之间的时间一致性,也没有合成新观点的能力。
从视频中删除移动的对象:虽然视频绘画是计算机视觉中一个很好的研究问题,但大多数工作集中在去除移动的物体。这通常是通过来自附近帧的引导来实现,例如,通过估计流,有时还使用深度。移动物体使任务变得更容易,因为它们的移动不遮挡背景,使场景的大部分在至少一个帧中可见。相比之下,要绘制静态场景的视频,需要生成方法,因为场景的大部分从未被观察到。
从视频中删除静态对象:当被遮挡的像素在序列中的其他帧中可见时,这些可以用于绘制区域。例如,从视频中删除静态的前景干扰物,如围栏和雨滴。然而,通常仍然有一些在其他视图中看不到的像素,因此需要一些其他的方法来填充它们。例如,将patches 从可见的像素传播到要绘制的区域,而通过patches 匹配来绘制缺失的像素。Kim等依赖于每个场景的预先计算的网格来去除对象。我们对这些方法的关键区别在于,我们的inpainting 可以被外推到新的视角中。
新视角的合成中的 inpainting。Inpainting 通常被用作新的视图合成的一个组成部分,以估计在输入中未观察到的区域的纹理,例如,对于全景生成。Philip等人允许从基于图像的渲染中去除对象,但假设背景区域是局部平面的。

2.1.新的视图合成和NeRF
NeRF是一种非常流行的基于图像的渲染方法,它使用可微的体积渲染公式来表示场景;多层感知器(MLP)被训练在给定三维坐标和光线观察方向的情况下回归颜色和不透明度。这结合了隐式3D场景表示,与光场渲染和新的视图合成。扩展包括减少混叠工件的工作,可以处理无界场景,仅从稀疏视图重建场景,或提高NeRF效率方法,例如,通过使用八叉树或其他稀疏结构
有深度感知的神经辐射场。为了克服NeRF 的一些限制,特别是对密集视图的要求和重建几何图形质量的限制,深度可以用于训练。这些可以是来自结构-运动的稀疏深度,或来自传感器的深度。
以对象为中心的语义NeRF 进行编辑。NeRF 的一个进展方向是将场景分解为其组成对象。这是基于动态场景的运动,或基于静态场景的实例分割。这两种工作也将场景背景作为一个单独的模型。然而,类似于视频内绘制,动态场景允许更好的背景建模,因为更多的背景是可见的。相比之下,视觉假象可以在的背景表示中看到,它建模了静态场景。基于语义分解场景的方法也可以用于删除对象。然而,当语义部分被删除时,他们不会试图完成场景。
用于新视角合成的生成模型。三维感知生成模型可用于从不同的视点合成一个对象或场景的视图,以一种三维一致的方式进行。与NeRF模型只有一个特定的场景相比,生成模型可以通过在潜在变量空间中采样来产生对新物体的幻觉(hallucinate views),它们符合源视图(或记忆)的能力可能是有限的。为了训练生成模型,大部分算法需要一个大的室内场景数据集,具有RGB和摄像机姿态。相比之下,我们使用的二维预训练的inpainting 网络,可以在任何图像上进行训练,对训练数据存在的依赖性更少,对室内场景的约束也更少。
三、方法
我们假设有一个具有相机位姿和内参矩阵(poses and intrinsics)的RGB-D序列。深度和姿态可以获得,例如,使用一个密集的 运动结构 pipline。在多数实验中,我们直接使用苹果的ARKit框架捕获提出的RGB-D序列,但我们也表明,我们可以通过使用多视图stereo 方法来估计RGB序列的深度来放松这一要求。在此过程中,我们还假设可以访问要删除的对象的每帧掩码。目标是从这个输入中学习一个NeRF模型,它可以用来合成一致的新视图,其中每帧的mask 区域应该被合理地绘制。方法概述如下图所示。

3.1.RGB和深度 inpainting网络
我们的方法依赖于一个二维单图像的绘制方法来单独绘制每个RGB图像。此外,我们还需要一个深度inpainting网络。我们使用这两个网络作为黑盒,我们的方法与所选择的方法是不可知的。未来对单幅图像内画的改进可以直接转化为对我们的方法的改进。给定一个图像输入In 和相应的掩模Mn,使用单幅图像输入算法生成一张新的图像输入 I ^ \hat I I^n。类似地,深度绘制算法生成一个深度绘制深度图 D ^ \hat D D^n**。图2展示了二维 inpainting网络的一些结果(左边为好的结果,右边为差的结果,包含严重的破坏优化的人工制品)。
3.2 NeRF 中的背景
依据原始的NeRF论文,我们将场景表示为一个MLP FΘ,预测颜色c=[r,g,b]和密度σ,对于包含x,y,z位置和两个观看方向的5维输入。像素r的预测颜色, I ^ \hat I I^n(r) 通过沿其相关光线的体渲染函数得到:
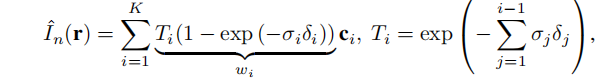
其中,K为射线数量,ti为采样位置,δi = ti+1−ti 为相邻样本之间的距离,wi为alpha的累积权重,根据构造,其和小于或等于1。则NeRF损失为 (如果有输入的深度标签,则可以增加额外的损失):
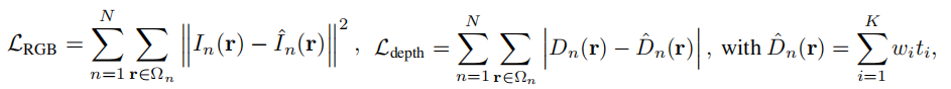
Ωn表示图像n的二维结构域,Dn(r )为像素r的输入深度,ˆDn(r )为对应的预测深度
最后,利用Mip NeRF360中的扭曲正则化损失,以更好地约束NeRF,去除“漂浮物”。它鼓励非零累积权值wi集中在射线的一个小区域,因此对于每个像素r:
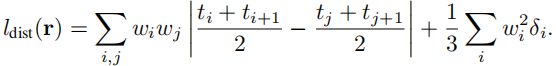
其中前一项为最小化两个小区域之间的w,后一项为单独某个小区域内,使其不透明累积权重w的值最小
3.3.基于置信度的视图选择
尽管大多数单独的RGB图像看起来很真实,但它们仍然存在两个问题: 1)一些插图是不正确的,2)尽管个体可信,它们不是多视图一致的(多个视图中观察到的同一区域不一定以一致的方式完成)。基于置信的视图选择方案,可以自动选择在NeRF优化中使用哪些视图。我们将每个图像n关联为一个非负的不确定性度量Un。相应的每幅图像的置信度e−un用于重新加权NeRF损失。这个置信值可以看作是一个损失衰减项,类似于任意不确定性预测项。RGB损失被设置为(公式5):

其中,像素r的颜色由mask像素的 inpainting 图像监督,并由mask 外像素的输入RGB图像监督。这个损失的第二项只在一组有限的图像P上计算,其中P⊆{1,…,N}。实践中,这意味着在NeRF优化中只使用 inpainting区域。下面我们将讨论如何选择集合P。
我们使用split mask内外的像素来构造深度损失:
最后,我们包括两个正则化器。一个是关于不确定性权重LPreg,以防止e−Un为0的平凡解。另一种是基于Mip-NeRF的失真正则化器,围绕着方程(4)中详细描述的损失,所以
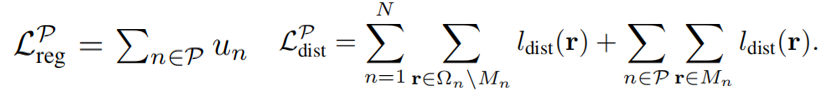
视图的方向和多视图的一致性。在优化NeRF时,我们做了三个观察: a) inpainting的多视图不一致由网络使用观察方向建模;b) 我们可以通过从输入中删除观察方向来加强多视图一致性;c) 当不使用观察方向作为输入时,不一致会在密度中引入类似云的伪影。
为了防止A和C,并正确优化捕获inpainting图像 I ^ \hat I I^n 的不确定性的变量Un,我们提出:
1)在NeRF中添加一个的辅助网络头FΘMV,不以观察方向作为输入,2)停止从彩色inpainting和FΘMV到密度的梯度,留下不确定性变量un作为唯一的视图相关的输入。这种设计迫使模型将 inpainting之间的不一致性编码到不确定性预测中,同时保持模型在不同视图之间的一致性。FΘMV的损失期限基于公式 5: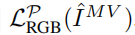
下图为结构说明:

以下为总损失,通过MLP参数{Θσ, Θc, ΘMV } 和不确定性权重UP ={un, n ∈ P}进行优化: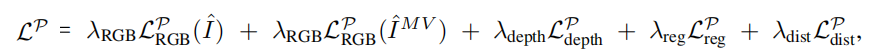
迭代细化。在一次迭代中,利用预测的每幅图像的不确定性Un,逐步从NeRF的优化中去除 non-confident的图像,即,网络迭代更新mask中对于损失有贡献的图像集合P。经过K步优化LP后,我们找到估计的置信中值m。然后,我们从训练集中删除所有相关置信度分数小于m的二维inpaint 区域,用更新的训练集重新训练NeRF,并重复这些步骤K次。请注意,从P中排除的图像仍然参与了优化,但只针对非mask区域中的光线,因为它们包含了关于场景的有价值的信息。上图右侧为伪代码
3.4 实施细节
掩模化要移除的对象:我们的方法需要每一帧的掩码作为输入。如在其他 inpaint 方法中所做的那样,使用2D mask手动注释每一帧,是很耗时的。相反,我们建议手动注释一个包含对象的3D框,每个场景只需完成一次。我们利用摄像机姿态和输入深度图重建场景的三维点云,导入到一个3D可视化和编辑软件(如MeshLab,在其中指定出被移除的对象的3D边界框。或者,我们可以依赖二维对象分割方法(如Mask RCNN),或3D对象边界框检测器Objectron中的一个基线,来mask对象。
mask细化。实践中,从带注释的三维边界框中获得的 mask相当粗糙,包含了大部分的背景。我们提出了一个 mask细化步骤(删除3D边界框中的部分空白空间),以获得在物体周围更紧密的掩模。首先取重建的三维点云中位于三维边界盒内的所有点。然后,通过将这些点渲染到每个图像中,并与深度图进行简单的比较,以检查当前图像中的遮挡情况,从而获得细化的掩模。通过使用二值膨胀和侵蚀放大传感器噪声引起的像素泄漏,清理产生的掩模。我们的掩模细化步骤的效果如图5所示。

Inpainting 网络:我们使用 [Resolution-robust large mask inpainting with fourier convolutions] 模型来同时Inpaint RGB和深度。RGB图像和深度图的绘制是独立完成的,我们使用了[该模型提供的参考网络。我们的深度图经过预处理,通过剪切到5m,并将深度在[0 m,5 m]中线性映射到[0,255]的像素值。这个矩阵被复制成一个H×W×3张量,以便输入到模型
NeRF 估计:我们的方法的实现是建立在Mip NeRF和Reg NeRF之上的。共享的MLP FσΘ由8个256维层组成,而分支FcΘ和FMVΘ分别由4个128维组成。最终的输出使用softplus激活密度,ReLU激活不确定性,sigmoid 激活颜色通道。我们使用λRGB = λdepth = λdist = 1和λreg = 0.005对损失函数加权,Adam进行优化,初始学习率lr = 0.0005。过滤步骤:每Kgrad=50000步去除低置信图像,得到Kouter = 4过滤步骤。
四. Experiments
4.1. Datasets
介绍了一个真实场景的RGB-D数据集,旨在评估对象去除的质量。我们的数据集将公开,有两个变体:
- Real objects:有17个场景:室内/室外景观/肖像方向,聚焦于至少有一个对象的小区域,其中一个被标记为感兴趣的对象。它们在背景纹理、对象大小和场景几何的复杂性方面的难度有所不同。对于每个场景,我们收集了两个序列,一个有,另一个没有我们想要删除的对象。这些序列是在带有激光雷达的iPhone 12 Pro上使用ARKit收集的,并包含RGB-D图像(分辨率192×256)和位姿。同一场景的两个序列使用相同的相机坐标系,序列长度从194帧到693帧不等。
如前所述,mask 是通过注释感兴趣对象的3D边界框来获得的,并对所有场景进行了细化。对于每个场景,我们使用带有对象的序列和相应的掩模来训练NeRF模型,并使用没有对象的序列来进行测试。使用真实的对象使它更容易评估系统如何处理真实的阴影和反射,以及新的视图合成
- Synthetic objects:大多数视频和图像的 inpaint方法,不执行新的视图合成,意味着不能在“真实对象”数据集上得到公平的评估。因此,我们引入了我们的数据集的一个单独的综合增强变体。这使用与真实对象数据集相同的场景,但我们只使用不包含对象的序列。然后,我们在每个场景中手动定位一个来自形状网[7]的3D对象网格。物体的放置使它有一个合理的位置和大小,例如,桌子上的笔记本电脑。这些掩模是通过将网格投影到输入图像中而获得的,这是我们对三维对象网格的唯一使用。对于这个合成数据集,每8帧进行测试,其余的帧用于训练NeRF模型。
- ARKitScenes:我们在ARKitScenes上定性地进一步验证了我们的方法。这是一个包含1661个场景的RGB-D数据集,其中的深度是通过iPhone Lidar捕获的
4.2.评估指标
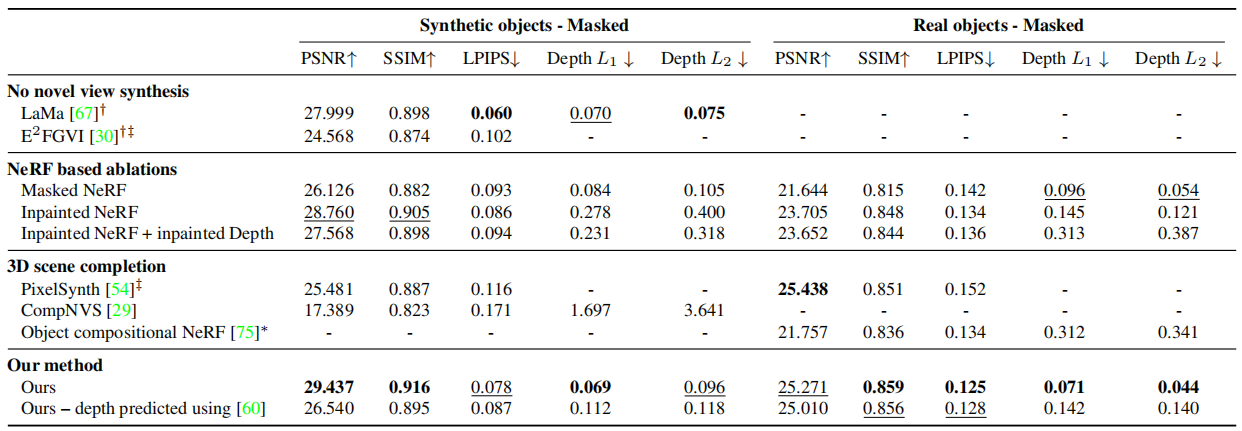
本文中的所有指标仅在掩蔽区域内计算(比较测试图像的系统输出图像与GroundTruth图像)。NeRF评估的三个标准指标: PSNR ,SSIM 和LPIPS 。评估几何补全率,计算了渲染深度图和mask 区域内的GroundTruth深度的L1和L2误差(序列所有帧上取平均值,所有序列取平均值)
基线和最先进的方法的比较:

总结
提示:这里对文章进行总结:
本文提出了一个框架来训练神经辐射场,其中对象可以从输出渲染中删除。该方法利用现有的二维inpaint工作,引入了一种基于置信度的自动视图选择方案来选择具有多视图一致性的单视图内画。我们通过实验验证,与现有的工作相比,我们提出的方法改进了三维绘制场景的新视图合成。我们还介绍了一个数据集来评估这项工作,它为该领域的其他研究人员设置了一个基准。