摘要
神经辐射场 (NeRF)可以合成真实世界场景的全新视角的照片,其性能优异,因此在计算机视觉领域引起较大的兴趣。NeRF的一个限制条件是需要准确相机位姿。本文提出了集束调整神经辐射场 (BARF) ,可以用不完美的(甚至不知道)相机位姿进行训练,同时学习三维表示和配准相机帧。本文建立了与经典图像对齐的理论联系,并指出由粗到精配准同样适用于NeRF。并且发现简单地使用位置编码对合成物体(指的应该是不同于原始数据,由算法生成的数据)的校准有负面影响。在人造数据和真实数据上的实验表明,BARF可以有效地神经场景表征并解决相机位姿未对准问题。这使得在未知相机位姿的情况下视角合成和视频序列定位成为可能,为视觉定位系统和在三维重建领域的潜在应用打开了大门。
1. 引用
重建物体和配准相机属于先有鸡先有蛋的问题,重建需要精确相机位姿,相机配准需要精确重建信息。sfm或slam的常用方法是通过局部配准,然后在结构和摄像机上进行全局几何捆绑调整(Bundle Adjustment)来解决这个问题。但以来局部配准,而且容易陷入次优解,而且输出的点云不利于下游任务。
NeRF等重建方法对相机位姿要求严苛,最简单的想法是通过back-propagation对相机位姿也同时优化,但是在实践中发现这对初始化很敏感,而且容易收敛到次优解,降低重建质量。注意,positional encoding益于重建,但同时导致次优解。

本文处理从不完善的相机位姿训练NeRF表征问题,也就是把重建三维场景和对准相机位姿联合起来(图1)。我们从经典图像对准方法中获得灵感并建议了理论连接,证明了由粗到精配准对NeRF也是极其重要的。我们特别指出,输入三维点的位置编码扮演重要角色,它使系统高频函数的拟合成为可能,位置编码更易受次优对准结果的影响。为了这个目地,我们提出了集束调整NeRF (BARF),使用简单有效的策略在基于坐标和场景表征上由粗到精地对准。可以认为BARF是一类光度BA,只是目替换成了人造视角。但是,与传统BA不同,BARF可以从零开始学习场景表征(也就是说可以随机初始化网络权重),解除局部匹配子过程的依赖并允许更为通用的应用。
主要贡献
- 建立了经典图像对齐到联合配准和用神经辐射场重建的理论联系;
- 表明positional encoding对配准的影响,提出coarse-to-fine配准策略;
- BARF可以从不完美相机位姿中重建场景三维表示,使得新视角合成和视频序列定位能从位未知视角中获得。
2. 相关工作
2.1. Structure from motion (SfM) and SLAM
给定一组图片,SfM和SLAM可以恢复三维结构和传感器位姿。其方法可以分为直接法和特征点法。目前特征点法已经取得了巨大的成功,但在无纹理和重复纹理区域其效果并不好。所以一些人正在使用神经网络来直接从数据中学习特征。直接法并不依赖于特征,它的每个像素光度语差有贡献。这使得在特征较为稀疏的情况下更为鲁棒,而且了更容易集成进深度学习框架。BARF就是一种直接法。但BARF并没有使用显示的几何信息(如点云)来表征三维场景,而是用神经网络把场景编码为坐标表征。
2.2. 视角合成
给定一组已知位姿的图片,视角合成技术可以模拟出一个全新视角的图片,该技术与三维重建技术有紧密有联系。
2.3. Neural Radiance Fields (NeRF)
由于简单和优异和性能,目前NeRF获得广泛的关注,而且它也被扩展到了许多其它方向。最近还有人使用大量数据预训练多层感知机,使其能够从单张图片推理辐射场。但是这些方法都有一个明显的缺点:它们需要图片的位姿是已知的。BARF恰恰可以规避这一需求,BARF使用了由粗到精的集束调整技术,可以用不完善的相机位姿甚至位姿的视频序列来恢复辐射场。
3. 方法
我们从二维情况开始,以经典的图片对准为便展开本文。然后讨论相同的概念对三维情况如何适用,它们如何提示我们提出BARF。
3.1. 平面图片对齐(2D)
2D图像对齐可以归纳成一个问题就是学习一个变换使得photometric error最小
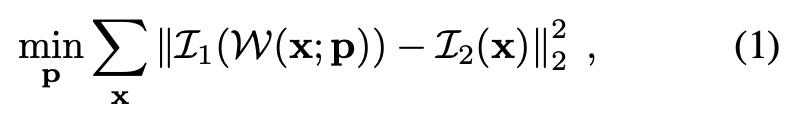
W就是warp function从2维映射到2维,由p维向量作为权重参数化,由于是个非线性问题,可以用梯度下降法,其中
![]()
如果用随机梯度下降法A就是一个标量学习率
而J可以表示为
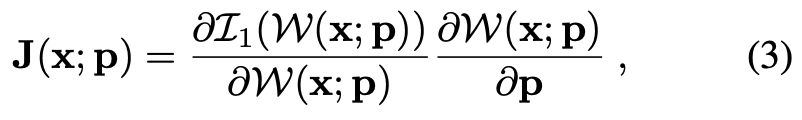
其中是warp雅可比矩阵限制对预定义warp的像素位移。
基于梯度方法的配准核心是图像梯度建模了一个局部的逐像素的表面和空间位移之间的线性关系,经常由有限差分来估计。显然的是如果每像素的预测之间有关系(即信号是光滑的),那么
的估计会更有效。
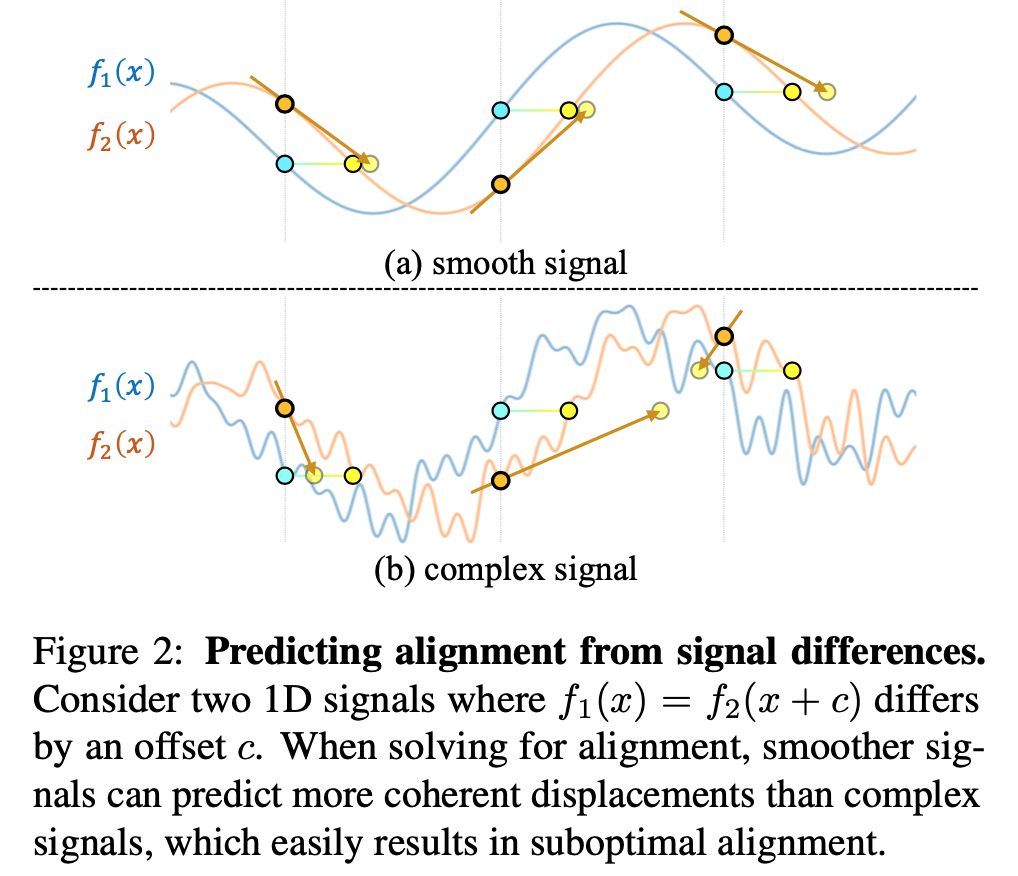
因此,通过在配准的早期阶段模糊图像,有效地扩大吸引区域和smoothening the alignment landscape,实践了从粗到细的策略。
图片作为神经网络
另一种方式是在解决p的时候用神经网络学一个图像的表示,神经网络参数是
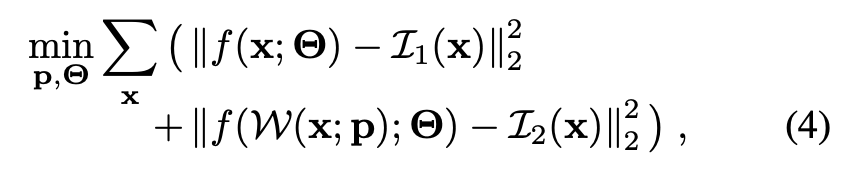
或者对每个图分别学一个p,回顾一下,p是warp function的P维向量参数
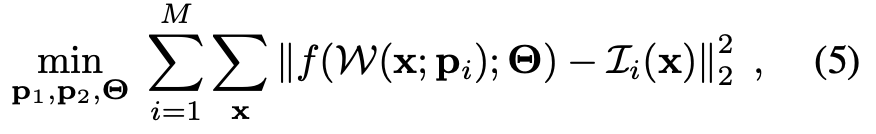
神经网络使得梯度不再是数值估计而是网络参数对位置的偏导,不再依赖启发式的对图像的模糊,这使得能泛化到三维情况。
3.2. 神经辐射场(3D)
为了保持一致性, 三维情况下x表示三维坐标,W表示nerf中的网络。NeRF实际上是用MLP 把三维坐标映射到四维输出,记为
![]()
是网络参数。实际上还有d,这里简化处理。
设一个像素点的坐标是u,那么齐次坐标是,根据多视图几何理论,在深度
的坐标就是
,那么渲染公式可以写为
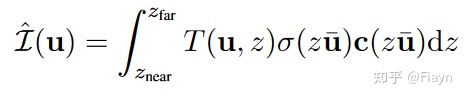
由于是N个采样点,最终得到的是一个三通道颜色,可以直接改写为

一个相机的参数,而相机坐标系下的x也可以通过W映射变到世界坐标系下,那么颜色可以写成关于像素坐标u和相机位姿p的函数

这个网络参数就是学习的神经辐射场的三维表示
如果有M张图,那么目标就是优化NeRF学习三维表示,并且优化相机位姿
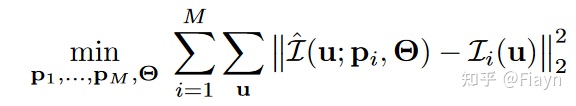
同样地可以推导出J的表达式用于更新p

3.3. 位置编码与配准
位置编码就是把信号映射到高频

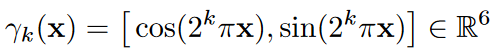
但是可以看到雅克比矩阵会有一个离谱的增益,这对预测来说是很不好的,适合重建中学习高频信号但是不适合配准中的学习,图像配准更希望平滑的信号。

3.4. 集束调整神经辐射场
处理上述问题的方法是加一个mask,作为一个低通滤波器,第k频率的位置编码就变成了
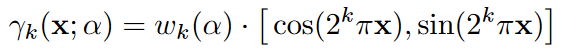

是一个和优化进程正相关的[0,L]之间的可控参数,那么雅克比矩阵就变成了
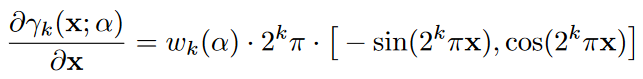
所以最开始raw input中是0,高频信号的雅可比矩阵系数都是0,慢慢的到最后
变成L,高频信号就和原始NeRF一样了。
这使得最开始从平滑信号学习图像配准,到后边学习高保真场景表示。
参考文献
BARF: Bundle-Adjusting Neural Radiance Fields