Abstract
本文提出了一种方法,能够使用从手机中随意捕获的照片真实地重建可变场景。可以观察到这些类NeRF变形场容易出现局部极小值,本文提出了一种基于坐标的模型从粗到细的优化方法,该方法可以带来更稳定的优化。通过把几何处理和物理模拟的原理应用于类神经网络模型,我们提出了变形场的弹性正则化,进一步提高了鲁棒性。
可变性神经辐射场
在这里,我们描述了在给定一组随意捕捉的场景图像的情况下,对非刚性变形场景进行建模的方法。我们将非刚性变形场景分解为神经辐射场(NeRF)的模板体和将观察坐标中的点与模板上的点关联的逐观察变形场。变形场是我们对NeRF的关键扩展,允许我们表示移动的物体。联合优化能量传递函数和变形场会导致欠约束优化问题。因此,我们引入了变形的弹性正则化、背景正则化和连续的、从粗到细的处理技术,以避免糟糕的局部极小值。
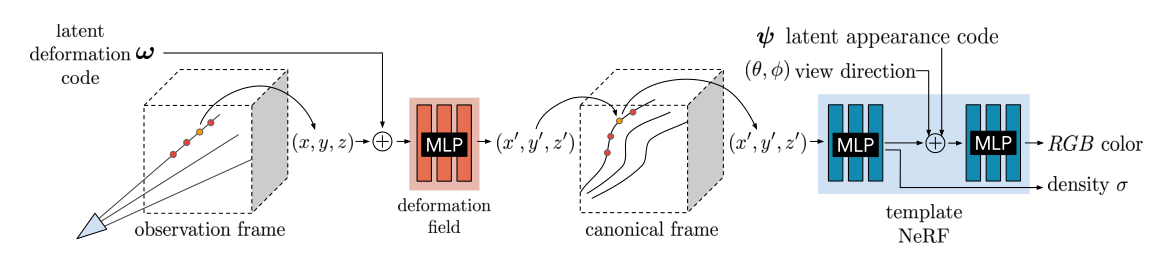
本文将潜在变形码(ω)和外观码(ψ)关联到每个图像。我们在观察帧中跟踪相机光线,并使用以变形码 ω 为条件的编码为 MLP 的变形场将样本沿着光线变换到正则帧。我们使用变换后的样本 ( x ′ , y ′ , z ′ ) (x',y',z') (x′,y′,z′)、观察方向(θ,φ)和外观码 ψ \psi ψ 作为 MLP 的输入来查询模板 NeRF ,并沿光线跟随NeRF积分样本。
神经辐射场(NeRF)
神经辐射场 (NeRF) 是一种连续的体积表示. 它是函数 F : ( x , d , ψ i ) → ( c , σ ) F : (x, d, \psi_i) \rightarrow (c, \sigma) F:(x,d,ψi)→(c,σ), 将三维位置 x = ( x , y , z ) x = (x, y, z) x=(x,y,z) 和观察方向 d = ( ϕ , θ ) d = (\phi, \theta) d=(ϕ,θ) 映射到颜色 c = ( r , g , b ) c = (r, g, b) c=(r,g,b) 和密度 σ \sigma σ .
NeRF 使用定义为 γ ( x ) = ( x , . . . , s i n ( 2 k π x ) , c o s ( 2 k π x ) , . . . ) \gamma(x) = (x, ..., sin(2^k \pi x), cos(2^k \pi x),...) γ(x)=(x,...,sin(2kπx),cos(2kπx),...) 的正弦位置编码 γ : R 3 → R 3 + 6 m \gamma : \mathbb{R}^3 \rightarrow \mathbb{R}^{3+6m} γ:R3→R3+6m 来映射输入 x x x 和 d d d . 其中 m m m 是控制频带总数和 k ∈ { 0 , . . . , m − 1 } k \in \{0,...,m-1\} k∈{ 0,...,m−1} 的超参数 . 这允许 MLP 在低频域中建模高频信号 .
我们还为每个观察到的帧 i ∈ { 1 , . . . , n } i \in \{1,...,n\} i∈{ 1,...,n} 提供了一个外观潜代码 ψ i \psi_i ψi 来调节颜色输出以处理输入帧之间的外观变化, 例如曝光和白平衡 .
NeRF 训练过程依赖于一个事实, 即给定一个3D场景, 来自两个不同摄像机的两条相交光线应产生相同的颜色 . 不幸的是, 许多场景并不是完全静止的, 如拍照时后手会轻微抖动 .
**
神经变形场
基于对这一局限性的理解, 我们扩展了 NeRF 以允许重建非刚性变形场景。该模板包含场景的相对结构和外观,而渲染将使用模板的非刚性变形版本。

在观测帧和正则帧参考系中恢复的可视化三维模型,插图显示了正向和左侧的正交视图。注意观察帧和正则帧之间从右到左和从前到后的位移,这些位移由该观察帧的变形场建模。
我们对每一帧 i ∈ { 1 , . . . , n } i \in \{1,...,n\} i∈{ 1,...,n} 进行观测to正则的变形, 其中 n n n 是观测到的帧数. 这定义了一个映射 T i : x → x ′ T_i : x \rightarrow x' Ti:x→x′ , 将所有观测空间坐标 x x x 映射到正则空间坐标 x ′ x' x′ . 我们使用映射 T : ( x , w i ) → x ′ T : (x, w_i) \rightarrow x' T:(x,wi)→x′ 为所有时间步长的变形场建模, 以每帧学习的潜在变形码 w i w_i wi 为条件. 每个潜在变形码对第 i i i 帧中的场景状态进行编码. 给定正则空间辐射场 F F F 和 观测to正则的映射 T T T,观察空间辐射场可以计算为: G ( x , d , ψ i , w i ) = F ( T ( x , w i ) , d , ψ i ) G(x,d,\psi_i,w_i) = F(T(x,w_i),d,\psi_i) G(x,d,ψi,wi)=F(T(x,wi),d,ψi) 渲染时, 我们只需在观察帧中投射光线和采样点, 然后使用变形场将采样点映射到模板中.
变形的一个简单模型是位移场 V : ( x , w i ) → t V:(x,w_i) \rightarrow t V:(x,wi)→t 将变换定义为 T ( x , w i ) = x + V ( x , w i ) T(x,w_i) = x + V(x,w_i) T(x,wi)=x+V(x,wi) 该公式足以表示所有连续变形;但是,使用平移场旋转一组点需要对每个点进行不同的平移,因此难以同时旋转场景区域。因此,我们使用密集SE(3)场 W : ( x , w i ) → S E ( 3 ) W:(x,w_i) \rightarrow SE(3) W:(x,wi)→SE(3) 来表示变形。SE(3)变换对刚性运动进行编码,允许我们使用相同的参数旋转一组远处的点。
我们将刚性变换编码为螺旋轴 S = ( r ; v ) ∈ R 6 S=(r;v)\in \mathbb{R}^6 S=(r;v)∈R6. 注意 r ∈ s o ( 3 ) r\in so(3) r∈so(3) 对旋转进行编码,其中 r ^ = r / ∥ r ∥ \hat r =r /\|r\| r^=r/∥r∥ 是旋转轴, θ = ∥ r ∥ \theta = \|r\| θ=∥r∥ 是旋转角度。r的指数产生旋转矩阵 e r ∈ S O ( 3 ) e^r \in SO(3) er∈SO(3) : e r ≡ e [ r ] × + s i n θ θ [ r ] × + 1 − c o s θ θ 2 [ r ] × 2 e^r \equiv e^{[r]_\times} + \frac{sin\theta}{\theta}[r]_\times + \frac{1-cos\theta}{\theta^2}[r]_\times^2 er≡e[r]×+θsinθ[r]×+θ21−cosθ[r]×2 其中 [ x ] × [x]_\times [x]× 表示向量x的叉积矩阵。
相似的,螺旋运动 S 的平移编码可以恢复为 p = G v p = Gv p=Gv. 其中 G = I + 1 − c o s θ θ 2 [ r ] × + θ − s i n θ θ 3 [ r ] × 2 G = I + \frac{1-cos\theta}{\theta^2}[r]_\times + \frac{\theta - sin\theta}{\theta^3}[r]_\times^2 G=I+θ21−cosθ[r]×+θ3θ−sinθ[r]×2 结合这些公式并使用指数映射,我们得到转换点为 x ′ = e S x = e r x + p x' = e^Sx = e^rx + p x′=eSx=erx+p
如前所述,我们使用类NeRF架构在MLP W : ( x , w i ) → ( r , v ) W:(x,w_i) \rightarrow (r,v) W:(x,wi)→(r,v) 中对变换场进行编码,并通过调节潜在码 w i w_i wi 来表示每个帧 i i i 的变换。我们通过嵌入层优化潜在码。与模板一样,我们使用位置编码 γ α \gamma_\alpha γα 映射输入 x x x.
弹性正则化
变形场增加了模糊性,使优化更具挑战. 这些模糊性导致欠约束优化问题,从而产生令人难以置信的结果和伪影(图6). 可以通过引入先验知识来解决.

图6: 通过线性插值羽毛球两帧 (左和右) 的变形潜在码合成的新视图显示了平滑的网拍运动.
弹性能量 : 对于一个固定的潜码 w i w_i wi,形变场 T T T 是一个从 R 3 R^3 R3 的观测坐标到 R 3 R^3 R3 的正则坐标的非线性映射。这个映射在 x ∈ R 3 x \in R^3 x∈R3 点的 Jacobian 矩阵 J T ( x ) J_T(x) JT(x) 描述了这个点上变换的最佳线性近似。因此,我们可以通过 J T J_T JT 控制形变的局部行为。注意,与其他使用离散曲面的方法不同,我们的连续公式允许我们通过MLP的自动微分直接计算 J T J_T JT。有几种方法来惩罚 Jacobian 矩阵 J T J_T JT 对刚性变换的偏差。考虑 Jacobian 矩阵 J T = U Σ V T J_T = U \Sigma V^T JT=UΣVT 的奇异值分解,多种方法惩罚离最近旋转 ∥ J T − R ∥ F 2 \|J_T - R\|_F^2 ∥JT−R∥F2 的偏差,其中 R = V U T R=VU^T R=VUT , ∥ ⋅ ∥ F \|\cdot\|_F ∥⋅∥F 是 Frobenius 范数。 我们选择直接使用 J T J_T JT 的奇异值,并测量其偏离恒等式。奇异值的对数对同一因子的收缩和展开给予同等的权重,我们发现它的表现更好。因此,我们惩罚了对数奇异值从零的偏差: L e l a s t i c ( x ) = ∥ l o g Σ − l o g I ∥ F 2 = ∥ l o g Σ ∥ F 2 L_{elastic}(x) = \|log\Sigma - logI\|_F^2 = \|log\Sigma\|_F^2 Lelastic(x)=∥logΣ−logI∥F2=∥logΣ∥F2. 这里的log是矩阵的对数。
鲁棒性 : 虽然人类大多是稳定的,但有一些动作可以打破我们对局部稳定的假设,例如,面部表情会局部拉伸和压缩我们的皮肤。因此,我们使用鲁棒损失重新映射上述定义的弹性能量: L e l a s t i c − r ( x ) = ρ ( ∥ l o g Σ ∥ F , c ) ρ ( x , c ) = 2 ( x / c ) 2 ( x / c ) 2 + 4 L_{elastic-r}(x) = \rho(\|log\Sigma\|_F,c) \\ \rho(x,c) = \frac{2(x/c)^2}{(x/c)^2+4} Lelastic−r(x)=ρ(∥logΣ∥F,c)ρ(x,c)=(x/c)2+42(x/c)2 其中ρ(·)为用超参数c = 0.03参数化的鲁棒误差函数。这种鲁棒的误差函数使得损失的梯度在参数值较大时降为零,从而减少了训练过程中异常值的影响。
weights: 我们允许变形场在空白空间中自由活动,因为相对于背景移动的主体需要空间中某处的非刚性变形。因此,我们根据光线对渲染视图的贡献来权衡每个样本的弹性惩罚.
背景正则化
我们可以选择添加一个正则化项来阻止背景移动。给定场景中的一组 3D 点,我们知道这些点应该是静态的,可以限制这些点的任何变形。例如,来自运动相机产生的一组 3D 特征点,这些点至少在一些观测值上表现静态。给定这些静态的3D点 { x 1 , . . . , x k } \{x_1,...,x_k\} { x1,...,xk},我们对运动的惩罚为: L b g = 1 K ∑ k = 1 K ∥ T ( x k ) − x k ∥ 2 L_{bg}=\frac{1}{K} \sum_{k=1}^{K}\|T(x_k)-x_k\|_2 Lbg=K1k=1∑K∥T(xk)−xk∥2 除了保持背景点不移动之外,这种正则化还具有将观测坐标系对准正则坐标系的优点。
由粗到细的变形正则化
回想一下 §3.1 中引入的位置编码参数 m m m ,它控制编码中使用的频带数. 且它也控制了网络的平滑度 : m m m 的值越低,就会产生低频偏差 (低分辨率) ,而m的值越大,就会产生高频偏差(高分辨率).
考虑一个如 图5 所示的动作,受试者旋转头部并微笑. 由于变形场的 m m m 值较小,模型无法捕捉微笑的微小运动. 相反,当m较大时,模型不能正确旋转头部,因为模板过度拟合到一个未优化的变形场. 为了克服这种权衡,我们提出了一种从低频偏差开始到高频偏差结束的粗到细的方法.

图5: 在这个捕捉中,主体旋转他们的头(上)和微笑(下)。当 m = 4 个位置编码频率时,变形模型不能捕捉笑脸,而当m = 8个频率时,变形模型不能旋转头部。通过从粗到细的正则化(c2f),该模型同时捕捉了这两种情况。