Bert 和 T5 之间的主要区别在于预测中使用的标记(单词)的大小。 Bert 预测一个由单个词组成的目标(single token masking),另一方面,T5 可以预测多个词,如上图所示。它在学习模型结构方面为模型提供了灵活性。
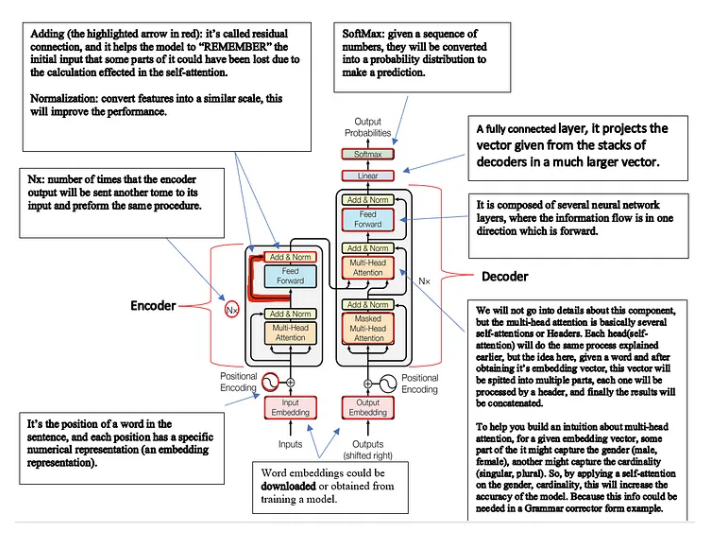
Transformer 是一种使用自注意力机制的深度学习模型。 Self-attention 的工作原理是在给定单词与其周围环境之间建立一定程度的重要性或关系。
在进入细节之前,请记住词嵌入是一个词的实数值数值表示,这种表示对一个词的含义进行编码,这将有助于检查哪个其他词具有相似的编码。相似的编码意味着单词彼此高度相关。
回到自我关注!
“今天我正在写一篇关于搜索引擎的文章。”
假设我想计算“文章”这个词的自注意力。
SA(‘article’) = “article”这个词与句子中其他词之间的关系量 (SA = Self-attention)。
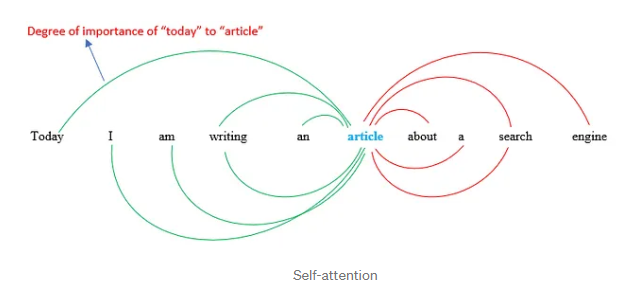
每个箭头代表单词“article”和句子中任何单词之间的注意力。换句话说,每个箭头表示这两个词彼此相关的程度。我们应该注意,这只是一个词的注意力,我们应该对所有其他词重复此步骤。
在该过程的最后,我们将为每个单词获得一个向量,其中包含代表单词及其与其他单词的关系的数值。
他们为什么要创建self-attention机制?
创建自我注意机制的原因是因为在其他基本模型中发现的局限性。
例如,skip-gram 是一个生成词嵌入的模型。在 skip-gram 的训练阶段,它学习预测给定单个单词作为输入的周围特定数量的单词。通常,我们指定窗口大小,即有多少包围的单词将作为输入给出。
但该模型的主要局限在于,对给定单词的预测将仅基于有限数量的周围单词。另一方面,self-attention 不仅会检查句子中的所有其他单词,还会赋予它们一定程度的重要性。
示例:ML 模型如何预测以下句子中的单词“river”:Bank of a (river)