探索语言模型
介绍
在这篇博文中,我将讨论 BERT、BART 和 T5 等大型语言模型。到 2020 年,法学硕士领域取得的重大进展包括这些模型的开发。BERT和T5是Google开发的,BART是Meta开发的。我将根据这些型号的发布日期按顺序介绍它们的详细信息。在上一篇博客文章自然语言处理的自回归模型中,我讨论了生成式预训练 Transformer 的自回归性质。在这篇博客中,我将比较这些模型与自回归模型的不同之处。因此,如果您还没有查看过上一篇文章,请去查看一下。BERT 论文于 2018 年发布,BART 于 2019 年发布,T5 于 2020 年发布。我将按照相同的顺序介绍论文的详细信息。
Transformer 的双向编码器表示 (BERT)
BERT模型基于多层双向Transformer编码器。BERT 旨在通过在所有层中联合调节左右上下文来预训练未标记文本的深度双向表示。因此,只需一个额外的输出层即可对预训练的 BERT 模型进行微调,以创建最先进的模型。BERT 使用屏蔽语言模型预训练目标来克服单向性约束。BERT的预训练也是通过下一句预测来完成的。
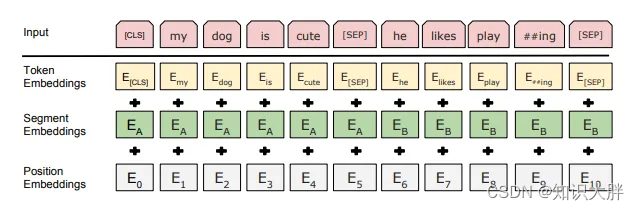
与 Transformer 相比,BERT 的输入表示是 token 嵌入、段嵌入和位置嵌入的总和。还添加了特殊分类标记和句子分隔符标记。令牌嵌入是词汇量为 30,000 的词块嵌入。预训练时使用的数据集是BookCorpus和Wikipedia。
屏蔽语言模型
在MLM预训练中,取输入序列的15%的单词。其中 80% 被屏蔽,10% 被随机单词替换,10% 保持不变。因此&#