大家好,我是微学AI,今天给大家介绍一下人工智能(Pytorch)搭建T5模型,真正跑通T5模型,用T5模型生成数字加减结果。T5(Text-to-Text Transfer Transformer)是一种由Google Brain团队在2019年提出的自然语言处理模型。T5模型基于Transformer结构,可以执行多种自然语言任务,如翻译、摘要、问答、文本生成等。它不同于其他模型的地方在于,T5模型采用了统一的输入输出格式,并通过微调来适应不同的任务。
一、T5模型优势
T5模型基于Transformer结构,其训练方式是无监督的。首先将大量的文本数据输入到模型中进行预训练,使得模型学习到了输入和输出之间的对应关系。而后,再利用有标注的数据对模型进行微调,以适应具体的任务需求。与其他自然语言处理模型相比,T5具备以下优势:
多任务学习能力强:同一个模型可以执行多种自然语言任务,只需要使用不同的微调方法即可。
零样本学习能力强:T5模型可以利用已有知识完成类似但未曾见过的任务。
表示能力强:T5模型可以捕获多种语义信息,并且可以用较少的参数来达到很好的性能。
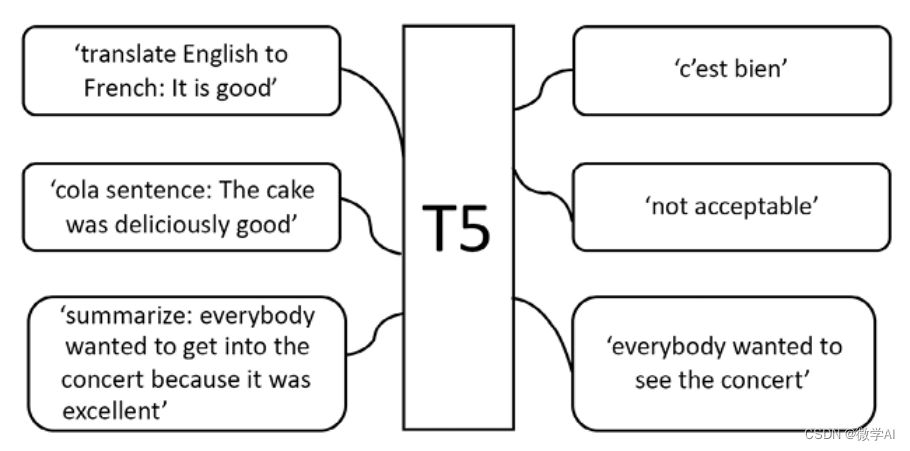
T5模型与传统语言模型不同,T5并不仅仅只是单纯地预测下一个词或者下一个句子,它可以直接生成完整的文本、回答问题或者进行翻译等多种任务。这归功于T5所使用的“Text-to-Text”框架,即将所有的自然语言处理任务转化为输入和输出都是文本的问题。
T5模型的训练过程中,使用了一种被称为“预训练+微调”的方法。首先,对大规模的数据集进行预训练,学习通用的语言表示;然后,使用少量的目标任务数据对模型进行“微调”,针对具体任务进行优化。T5模型还使用了一种名为“Span Extraction”的技术,使得模型可以在输出序列中找到最相关的片段,从而更好地完成各种任务。同时,T5模型使用了“Token Dropout”机制来避免过拟合,并采用了许多其他技巧,包括多层解码器、混合精度训练等。
二、代码实现
import torch
from torch.utils.data import DataLoader, Dataset
from transformers import T5ForConditionalGeneration, T5Tokenizer, AdamW
import random
# 自己定义输入的数据
class MyDataset(Dataset):
def __init__(self, data, tokenizer, max_length):
self.data = data
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
input_text, target_text = self.data[idx]
inputs = self.tokenizer(input_text, return_tensors="pt", padding="max_length", max_length=self.max_length, truncation=True)
targets = self.tokenizer(target_text, return_tensors="pt", padding="max_length", max_length=self.max_length, truncation=True)
return {
"input_ids": inputs["input_ids"].squeeze(),
"attention_mask": inputs["attention_mask"].squeeze(),
"labels": targets["input_ids"].squeeze()
}
# 指定使用的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 使用 T5-small 模型。 如果想用更大的模型,可以将 "t5-small" 替换为例如 "t5-base" 或 "t5-large"
model_name = "t5-small"
model = T5ForConditionalGeneration.from_pretrained(model_name).to(device)
tokenizer = T5Tokenizer.from_pretrained(model_name)
# 构造训练数据
data = []
for i in range(800):
a = random.randint(0, 9)
b = random.randint(0, 9)
op = random.choice(["+", "-"])
if op == "+":
result = a + b
else:
result = a - b
data.append((f"{a} {op} {b}", str(result)))
max_length = 32
train_dataset = MyDataset(data, tokenizer, max_length)
#train_dataset = MyDataset(data, tokenizer)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
# 训练模型
num_epochs = 10
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
for epoch in range(num_epochs):
model.train()
for batch in train_loader:
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = batch["labels"].to(device)
outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f"Epoch: {epoch}, Loss: {loss.item():.6f}")
# 测试训练后的模型
model.eval()
input_text = "1 + 1"
inputs = tokenizer(input_text, return_tensors="pt", padding=True).to(device)
outputs = model.generate(inputs["input_ids"], attention_mask=inputs["attention_mask"])
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"Model prediction: {input_text} = {result}")
# 保存模型
model.save_pretrained("trained_t5")
tokenizer.save_pretrained("trained_t5")以上是T5ForConditionalGeneration模型,利用简单的训练数据进行训练。后面需要添加更多的数据以实现更高的准确率。
训练完的模型和tokenizer会被保存到名为trained_t5的文件夹中。
使用较有限的数据进行较少的训练轮次可能导致较低的准确率,
我这里给大家提供了模型训练和验证的基本方法。如果需要提高模型的性能,可以尝试使用更大的数据集、增加训练轮次以及在设备性能允许的情况下试验更大的T5模型。后续文本生成就是利用这个模型训练的,也可以训练做类似ChatGPT类似的聊天机器人。
大家继续期待吧,后面还有更多的模型使用技巧贡献出来!!