所谓Attention机制,便是聚焦于局部信息的机制,如图像中的某一个图像区域。随着任务的变化,注意力区域往往会发生变化。注意力机制是深度学习常用的一个小技巧,当我们使用卷积神经网络去处理图片时,我们希望卷积神经网络去注意相对重要的地方,注意力机制就是实现网络自适应注意的一个方式。
注意力机制通常可以分为通道注意力和空间注意力,或者是二者的相互结合。
一、通道注意力(SENet)
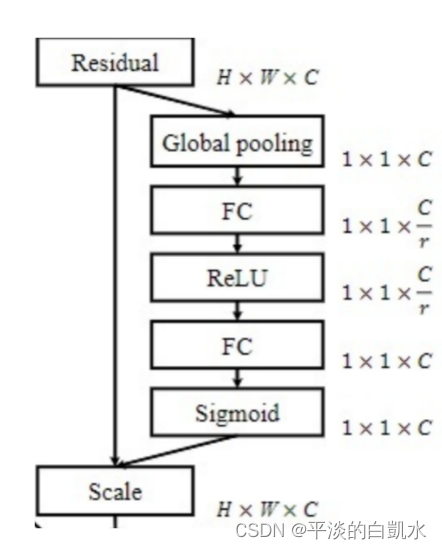
通道注意力在意的是每个特征通道的权重,让网络关注它最需要关注的通道。上图显示了其具体实现步骤,有以下6步:
1)对输入进来HxWxC的特征图进行全局池化(最大/平均),可以得到一个1x1xC特征长条,长度是输入特征图的通道数C;
2)然后进行一次全连接,降维到神经元个数较少C/r维,得到一个1x1XC/r的向量;
3)ReLu激活函数;
4)第二次全连接,使其向量长度恢复到与之前相同,即1x1xC的向量;
5)Sigmoid函数将每个权值归一化到0-1之间;
6)输入特征图的每个通道乘以每个通道的权值,得到新的特征图即可。
实现代码如下(代码中用了最大和平均池化,最后相加):
import torch
import torch.nn as nn
import torch.utils.data as Data
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x): # x 的输入格式是:[B, C, H, W]
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
二、空间注意力
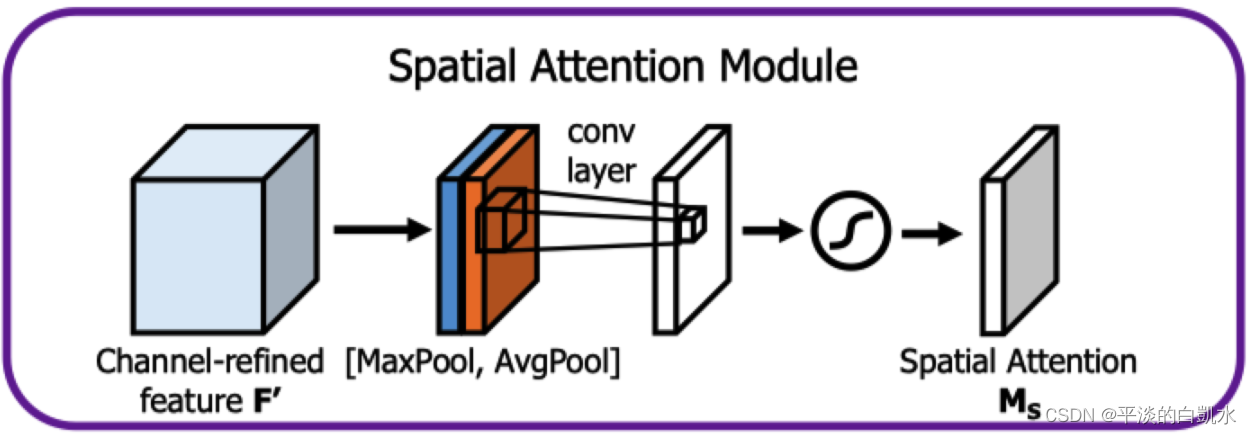
空间注意力在意的是面上每一个局部的权重,具体实现步骤有以下5步:
1)对输入进来HxWxC的特征图的每个位置,其所有通道取最大值,可以得到一个HxWx1的特征图;
2)对输入进来HxWxC的特征图的每个位置,其所有通道取平均值,也得到一个HxWx1的特征图;
3)对两个特征图进行堆叠(concat),得到HxWx2的特征图,进行一次卷积调整通道数为1,得到HxWx1的特征图;
4)Sigmoid函数将每个位置权值归一化到0-1之间;
5)输入特征图的每个位置乘以每个位置的权值,得到新的特征图即可。
实现代码如下:
import torch
import torch.nn as nn
import torch.utils.data as Data
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x): # x 的输入格式是:[B, C, H, W]
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
三、CBAM的实现
CBAM将通道注意力机制和空间注意力机制进行一个结合,相比于SENet只关注通道的注意力机制可以取得更好的效果。其实现示意图如下所示,CBAM会对输入进来的特征层,分别进行通道注意力机制的处理和空间注意力机制的处理。
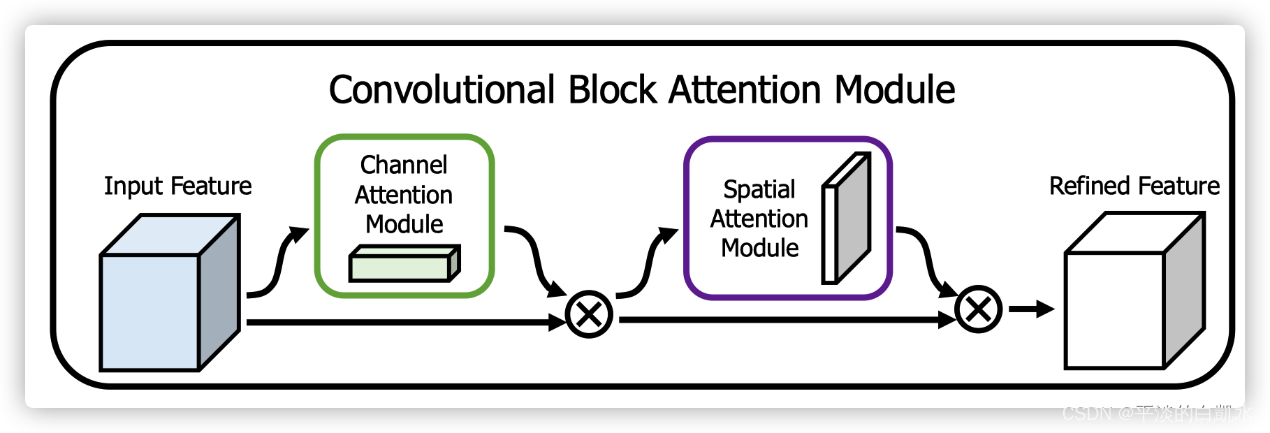
注意力模块的布局:给定输入图像,通道和空间两个注意模块计算互补注意,分别关注“什么”和“在哪里”。考虑到这一点,两个模块可以以并行或顺序的方式放置。原论文作者发现顺序排列比并行排列可得到更好的结果。
实现代码如下:
class cbam_block(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=7):
super(cbam_block, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x * self.channelattention(x)
x = x * self.spatialattention(x)
return x