Graph Attention Networks
18年的ICLR,通讯作者是Yoshua Bengio,真大佬。
@inproceedings{
veličković2018graph,
title={Graph Attention Networks},
author={Petar Veličković and Guillem Cucurull and Arantxa Casanova and Adriana Romero and Pietro Liò and Yoshua Bengio},
booktitle={International Conference on Learning Representations},
year={2018},
url={https://openreview.net/forum?id=rJXMpikCZ},
}
一、介绍
这篇文章主要工作是将masked self-attention层(后面又扩展了)引入图神经网络,栈式叠加地访问邻居节点,解决之前的基于谱图模型(spectral-based graph neural network)的一系列问题,也同时适用于转导学习(transductive learning)和归纳学习(inductive learning)。实验数据集有四个:Cora、Citeseer、Pubmed和Protein-protein interaction(前三个属于转导学习,最后一个属于归纳学习)。
二、背景
图神经网络最近算是一个热门的研究领域,它不同之处在于训练数据是一个图,不再是之前的直接用欧式空间就可以随意表征了。最简单的输入数据也要包括邻接矩阵和节点特征两部分,且图的节点不仅仅是加权,还有很多特征。
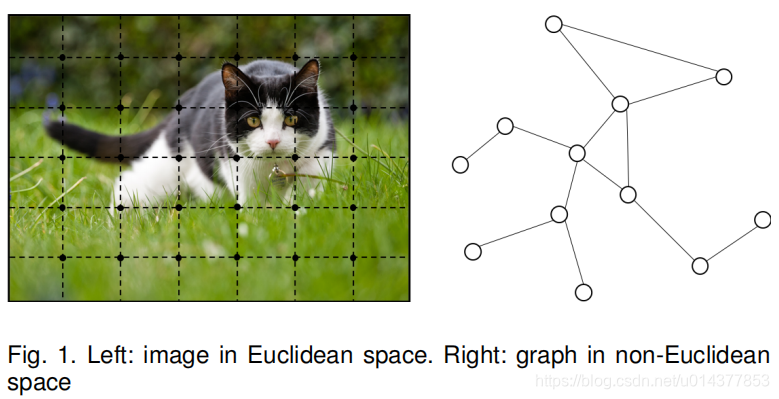
上图来自一篇综述Jie Zhou et al. Graph Neural Networks:A Review of Methods and Applications
三、Idea与解决的问题
Idea来源自注意力机制的三个好处:
- 效率高,因为可以并行访问邻居节点
- 给每个邻居节点设置一个权重,很容易应用到图上
- 模型可以直接应用与归纳学习中,包括生成一些完全没见过的图
解决的主要问题:
- 之前需要整个图的拓扑,即需要在训练的时候知道整个图的结构
这是基于谱图模型的普遍要求,因为谱图需要对图的邻接矩阵进行奇异值分解或其他矩阵分解操作,也就是文中提到的依赖于 Laplacian eigenbasisis。且这种模型不具有泛化性,因为如果换了一个新的拓扑结构,模型也需要重新调整,这显然是无法容忍的问题,因为这已经不是学习了。
- 加速训练,图可以是有向图
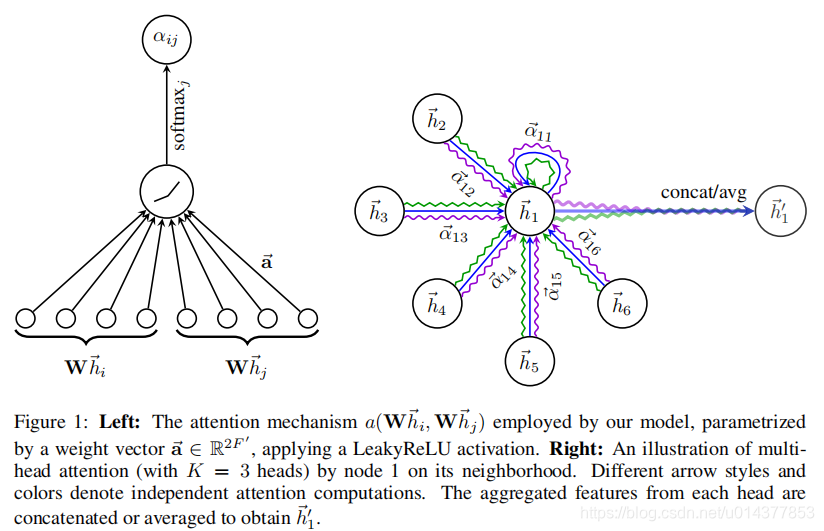
四、Graph Attention Network架构
下面以一个单注意力层为例。
形式化地,输入节点特征的集合 h = { h 1 → , h 2 → , . . . , h N → } , h i → ∈ R F h=\{\overset{\rightarrow}{h_1},\overset{\rightarrow}{h_2},...,\overset{\rightarrow}{h_N}\},\overset{\rightarrow}{h_i}\in{\R^F} h={
h1→,h2→,...,hN→},hi→∈RF,其中 N N N是节点的数量, F F F是每个节点的特征数量。
这一层输出 h ′ = { h 1 ′ → , h 2 ′ → , . . . , h N ′ → } , h i ′ → ∈ R F ′ h^{'}=\{\overset{\rightarrow}{h^{'}_1},\overset{\rightarrow}{h^{'}_2},...,\overset{\rightarrow}{h^{'}_N}\},\overset{\rightarrow}{h^{'}_i}\in{\R^{F^{'}}} h′={
h1′→,h2′→,...,hN′→},hi′→∈RF′
初始步骤,通过权重矩阵 W ∈ R F ′ × F W\in \R^{F^{'}×F} W∈RF′×F,参数化一个共享的线性转换,并将这个转换应用于每一个节点。然后,在每个节点上进行self-attention,即一个shared attentional mechanism a : R F ′ × R F ′ → R a : \R^{F^{'}}×\R^{F^{'}} \rightarrow \R a:RF′×RF′→R,计算出attention系数: e i j = a ( W h i → , W h j → ) (1) e_{ij}=a(W\overset{\rightarrow}{h_i},W\overset{\rightarrow}{h_j}) \tag{1} eij=a(Whi→,Whj→)(1)
(1)式表面节点 j j j的特征对 i i i的重要程度。