NLP入门学习2——文本分类(基于keras搭建LSTM)
0.简介
本文将以实战的方式详细介绍使用keras搭建单层、多层、单向、双向的LSTM模型,以完成对新闻数据的分类。主要面向NLP初学者,所以写的尽可能详细,当然也欢迎各路大佬提出宝贵的意见。
所用的数据为清华大学新闻数据THUCNews的子集,
下载链接:https://pan.baidu.com/s/1U_Ypqiu8Cq4IAWdqiDLR_g 提取码:9766
附THUCNews网址http://thuctc.thunlp.org/
数据的train、val、test集分别包含了50000,5000,10000条新闻,并且标明了每条新闻属于哪一个类别,共10个类别。
先贴出参考链接:
参考链接1
参考链接2
参考链接3
参考链接4
参考链接5
本文的主要参考https://zhuanlan.zhihu.com/p/39884984中对模型的构建和训练过程进行了比较详细的描述,我在此基础上加入了自己的理解和更加详细的注释,以及更多的模型结构。
1.环境依赖
本文主要用到以下模块:
| 模块 | 版本 |
|---|---|
| keras | 2.4.3 |
| scikit-learn | 0.19.1 |
| scipy | 1.0.0 |
| seaborn | 0.8.1 |
| numpy | 1.14.0 |
注意,如果numpy的版本过高的话,可能会出现sklearn import失败的问题。
2.分词处理
在拿到数据之后,首先要进行简单的预处理工作,在这里也就是将新闻进行分词,可用的工具有好几种,不妨使用常用的中文分词工具jieba。
train_df['cutword'] = '' # 给dataframe新建一个名为cutword的列
for row in train_df.iterrows(): # 对每一行进行操作
cut_res = ' '.join(jieba.cut(row[1]['text'])) # jieba分词
#print(cut_res)
train_df['cutword'][row[0]] = cut_res # 将分词的结果写入dataframe
处理完之后的dataframe应该是这个样子的。

同样的val和test也需要进行相同的处理。
或者如果嫌麻烦不想自己做分词的话也可以直接使用参考链接1中分好的csv文件,在原文中有下载链接。
3.模型构建
3.1 单向单层的LSTM
这一部分其实就是对https://zhuanlan.zhihu.com/p/39884984中的内容进行了复现,如果原文博主介意的话请提醒我修改或删除。
首先是导入所需要的的包:
import pandas as pd
import numpy as np
from sklearn import metrics # 模型评价指标
from sklearn.preprocessing import LabelEncoder,OneHotEncoder # 用于对数据集的标签进行编码
from keras.models import Model # 通用模型定义方法
from keras import Sequential # 序列模型定义方法
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding # keras中添加的各层
from keras.optimizers import RMSprop # 优化器
from keras.preprocessing.text import Tokenizer # 词典生成
from keras.preprocessing import sequence # 主要用于序列的padding
from keras.callbacks import EarlyStopping # 训练过程中的早停
import seaborn as sns
在这里我因为比较懒的缘故,没有对字体进行设置,在后面作图的时候就直接用拼音代替了。
导入数据:
train_df = pd.read_csv('/root/news/cnews_train.csv')
val_df = pd.read_csv('/root/news/cnews_val.csv')
test_df = pd.read_csv('/root/news/cnews_test.csv')
test_df.head()
对数据的label进行编码

# 对标签进行编码
# labelencoder的效果是将标签转变为数字编号,本例中就是0-9的数字
train_y = train_df.label
val_y = val_df.label
test_y = test_df.label
LabelE = LabelEncoder()
train_y = LabelE.fit_transform(train_y).reshape(-1,1)
val_y = LabelE.transform(val_y).reshape(-1,1)
test_y = LabelE.transform(test_y).reshape(-1,1)
# 对标签进行one-hot编码
# 再将刚才的编号转为one-hot
OneHotE = OneHotEncoder()
train_y = OneHotE.fit_transform(train_y).toarray()
val_y = OneHotE.transform(val_y).toarray()
test_y = OneHotE.transform(test_y).toarray()
依据词频,对文本中的词语进行编号,词频越大的词,编号越小。
max_words = 5000 # 词表中的最大词语数量
max_len = 600 # 新闻向量的最大长度
tok = Tokenizer(num_words=max_words)
tok.fit_on_texts(train_df.cutword)
使用tok.word_index.items(),查看词频最大的10个词对应的编号:
for ii,iterm in enumerate(tok.word_index.items()):
if ii < 10:
print(iterm)
else:
break
输出:
('我们', 1)
('一个', 2)
('中国', 3)
('可以', 4)
('基金', 5)
('没有', 6)
('自己', 7)
('他们', 8)
('市场', 9)
('这个', 10)
使用tok.word_counts.items(),查看词库中前10个单词在词库中出现的词频:
for ii,iterm in enumerate(tok.word_counts.items()):
if ii < 10:
print(iterm)
else:
break
输出:
('马晓旭', 2)
('意外', 1641)
('受伤', 1948)
('国奥', 148)
('警惕', 385)
('无奈', 1161)
('大雨', 77)
('格外', 529)
('青睐', 1092)
('殷家', 1)
至此每个词语都已经用编号来表示了,那么就可以将每条新闻都转为一个向量。并且为了确保在后面模型的输入中,所有的向量保持相同的维度,需要进行padding操作,也就是把所有新闻都补齐到相同的长度,max_len=600
train_seq = tok.texts_to_sequences(train_df.cutword)
val_seq = tok.texts_to_sequences(val_df.cutword)
test_seq = tok.texts_to_sequences(test_df.cutword)
# 将每个序列调整为相同的长度
train_seq_mat = sequence.pad_sequences(train_seq,maxlen=max_len)
val_seq_mat = sequence.pad_sequences(val_seq,maxlen=max_len)
test_seq_mat = sequence.pad_sequences(test_seq,maxlen=max_len)
准备工作做好之后,就可以利用keras来搭建LSTM模型了。在keras中的模型搭建主要包括两种方式,通用模型和序列模型。参考的原文中采用的是利用通用模型Model进行搭建,由于本文是面向初学者,所以同时给出另一种方法序列模型Sequential的搭建。至于两种模型的区别此处不做详细的介绍,可以自行百度。
首先是通用模型:
inputs = Input(name='inputs',shape=[max_len])
## Embedding(词汇表大小,batch大小,每个新闻的词长)
layer = Embedding(max_words+1,128,input_length=max_len)(inputs) # 定义Embedding层,128是embedding之后的维度
layer = LSTM(128)(layer) # 定义LSTM层,上一层的输出维度128
layer = Dense(128,activation="relu",name="FC1")(layer) # 定义全连接层
layer = Dropout(0.5)(layer)
layer = Dense(10,activation="softmax",name="FC2")(layer)
model = Model(inputs=inputs,outputs=layer) # 建立模型
model.summary()
model.compile(loss="categorical_crossentropy",optimizer=RMSprop(),metrics=["accuracy"]) # 损失函数、优化器、评价标准
模型summary:
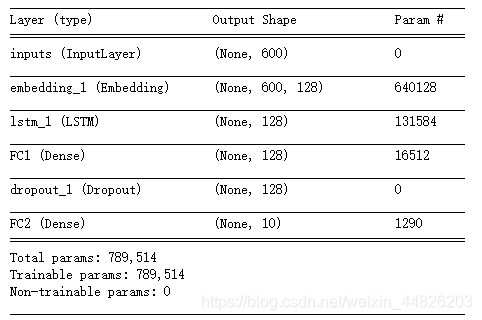
至此,数据的准备工作和模型结构搭建都已经完成了,接下来就可以开始训练了。为了节省时间,在这里采用了早停的机制。
model_fit = model.fit(train_seq_mat,train_y,batch_size=128,epochs=10,
validation_data=(val_seq_mat,val_y),
callbacks=[EarlyStopping(monitor='val_loss',min_delta=0.0001)] # 当val-loss不再提升时停止训练
)
在我的训练过程中仅仅经过了两个epoch,测试集上的效果就不再提高了,于是触发了早停。损失和准确性的情况如下:

然后对测试集进行预测,看一下模型的准确率、召回率。
# 对测试集进行预测
test_pre = model.predict(test_seq_mat)
# 计算混淆矩阵
confm = metrics.confusion_matrix(np.argmax(test_pre,axis=1),np.argmax(test_y,axis=1))
print(metrics.classification_report(np.argmax(test_pre,axis=1),np.argmax(test_y,axis=1)))
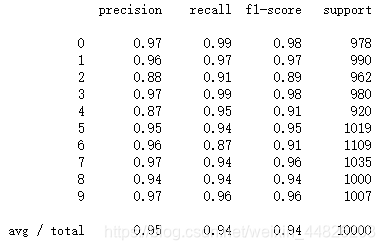
用热图对混淆矩阵进行可视化:
Labname = ["tiyu","yule","jiaju","fangchan","jiaoyu","shishang","shizheng","youxi","keji","caijing"] # 没有设置字体,就直接用拼音代替了
plt.figure(figsize=(8,8))
sns.heatmap(confm.T, square=True, annot=True,
fmt='d', cbar=False,linewidths=.8,
cmap="YlGnBu")
plt.xlabel('True label',size = 14)
plt.ylabel('Predicted label',size = 14)
plt.xticks(np.arange(10)+0.5,Labname,size = 12)
plt.yticks(np.arange(10)+0.3,Labname,size = 12)
plt.show()
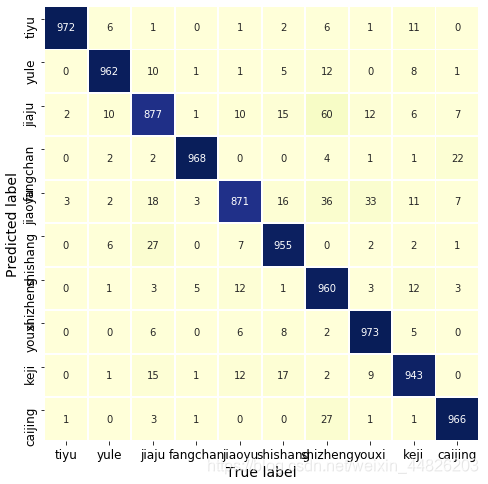
总的来说效果还不错,与原文博主的结果也基本保持一致。
接下来再用序列模型的方法搭建LSTM。直接贴代码:
from keras import Sequential
model = Sequential() # 首先将模型定义为序列模型
model.add(Embedding(max_words+1, 128, input_length=max_len)) # 添加一个embedding层
model.add(LSTM(128)) # 添加一个LSTM层
model.add(Dense(128,activation='relu',name='FC1')) # 添加一个全连接层
model.add(Dropout(0.5))
model.add(Dense(10,activation='softmax',name='FC2'))
model.compile(loss='categorical_crossentropy',optimizer=RMSprop(),metrics=['accuracy'])
model.summary()
对比一下summary的结果,发现与之前的模型完全一致。

还是用相同的方法训练一下。在这里干脆就让epoch固定在2了。
model_fit = model.fit(train_seq_mat,train_y,batch_size=128,epochs=2,
validation_data=(val_seq_mat,val_y),
callbacks=[EarlyStopping(monitor='val_loss',min_delta=0.0001)]
)
结果发现训练了两个epoch之后的效果并不如刚才的模型训练两个epoch的效果,可能模型不应该在这个时候停止训练。但是随着epoch的增加,两个模型最后的效果应该是一致的。
3.2 单向多层的LSTM
多层的LSTM的定义与单层的LSTM大同小异,只是稍微注意一下上一层的输出就好了。
在这里以序列模型为例,构建一个双层的LSTM模型。
from keras import Sequential
model = Sequential()
model.add(Embedding(max_words+1, 128, input_length=max_len))
model.add(LSTM(128,return_sequences=True,name='LSTM1')) # 添加第一个LSTM层
model.add(LSTM(128,name='LSTM2')) # 添加第二个LSTM层
model.add(Dense(128,activation='relu',name='FC1'))
model.add(Dropout(0.5))
model.add(Dense(10,activation='softmax',name='FC2'))
model.compile(loss='categorical_crossentropy',optimizer=RMSprop(),metrics=['accuracy'])
model.summary()
需要注意一下两层LSTM在添加时的区别,第二层LSTM与之前的LSTM层的添加没有什么区别,但是如果它的上一层LSTM不写return_sequences=True的话,在执行第二层LSTM添加语句时就会维度方面的错误。这就要说道LSTM的return_sequences参数了。
这个参数用来控制LSTM层是否返回每一个节点的hidden state,在keras中,默认return_sequences为False,也就是只返回最后一个时间的hidden state。
这样一来,如果不记录下所有时间的hidden state,那么在第二层LSTM的输入过程中,输入的维度就不再是128了,于是会报错。
然后看一下模型的summary:
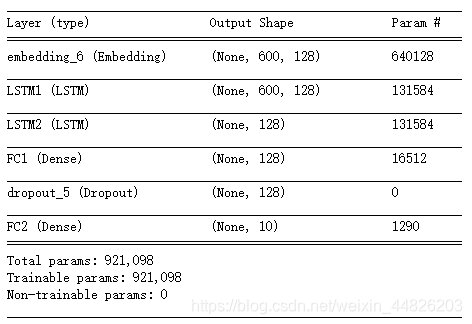
然后训练两个epoch试一下,时间关系没有训练很多。

模型训练变慢了,但是从前两个epoch来看,加一层LSTM并没有提高模型的准确性,不知道继续训练下去会是什么效果。
3.3 双向LSTM
使用keras搭建一个双向的模型,只需要import一下Bidirectional就可以了,然后在LSTM层前面加上Bidirectional使它变成双向。
from keras import Sequential
from keras.layers import Bidirectional
model = Sequential()
model.add(Embedding(max_words+1, 128, input_length=max_len))
model.add(Bidirectional(LSTM(128)))
model.add(Dense(128,activation='relu',name='FC1'))
model.add(Dropout(0.5))
model.add(Dense(10,activation='softmax',name='FC2'))
model.compile(loss='categorical_crossentropy',optimizer=RMSprop(),metrics=['accuracy'])
model.summary()
然后,同样的方法训练2个epoch。

效果看上去并没有太大的变化。就是比单向单层的情况训练所需的时间变长了。
4.模型的保存和应用
4.1 模型的保存
除了要保存模型,还需要保存训练的tokenizer。下面的代码分别是保存和加载。
import pickle
# saving
with open('tok.pickle', 'wb') as handle:
pickle.dump(tok, handle, protocol=pickle.HIGHEST_PROTOCOL)
# loading
with open('tok.pickle', 'rb') as handle:
tok = pickle.load(handle)
然后把模型也保存为h5文件,以及模型的加载:
from keras.models import load_model
# 保存模型
model.save('LSTM.h5')
del model
# 加载模型
model = load_model(LSTM.h5')
# 如果工作空间中已有模型model,需要先把它删了再加载。
# del model
4.2 模型的应用
模型训练好之后就可以用来做新闻的分类了。如果想直接看看验证集上的分类效果:
val_seq = tok.texts_to_sequences(val_df.cutword)
# 将每个序列调整为相同的长度
val_seq_mat = sequence.pad_sequences(val_seq,maxlen=max_len)
# 对验证集进行预测
pre = model.predict(val_seq_mat)
pre是一个数组,每一条中包含十个元素,其中最大的元素的位置就是其对应的类别。
但是这样用,似乎。。。不太方便的样子,如果想看验证集上某个id的新闻对应的类别,则可以通过这样一个简单的函数来实现:
def pre_res(id):
'''
查看指定id的新闻的分类结果
'''
loc = np.argmax(val_pre[id])
if loc == 0:
res = '体育'
elif loc == 1:
res = '娱乐'
elif loc == 2:
res = '家居'
elif loc == 3:
res = '房产'
elif loc == 4:
res = '教育'
elif loc == 5:
res = '时尚'
elif loc == 6:
res = '时政'
elif loc == 7:
res = '游戏'
elif loc == 8:
res = '科技'
elif loc == 9:
res = '财经'
return res
测试一下:
pre_res(4998)
结果为财经。分类准确。
5.结束
到这里,利用keras搭建LSTM的内容就介绍完成了,接下来看时间看心情更TensorFlow或者torch版本,那么我们下期再见。