对于 Bert 来说,用于文本分类是最常见的,并且准确率也很高。本文将会对 bert 用于文本分类来做详细的介绍。
预训练模型
预训练模型下载地址:Models - Hugging Face
本文使用的是中文数据集,因此需要选择中文的预训练模型:bert-base-chinese at main
Bert 模型主要结构
BertModel 主要为 transformer encoder 结构,包含三个部分:
- embeddings,即BertEmbeddings类的实体,对应词嵌入;
- encoder,即BertEncoder类的实体;
- pooler,即BertPooler类的实体,这一部分是可选的。
注意:BertModel 也可以配置为 Decoder

图1 bert 模型初始化/结构
Bert文本分类模型常见做法为将bert最后一层输出的第一个token位置(CLS位置)当作句子的表示,后接全连接层进行分类。
Bert 模型输入
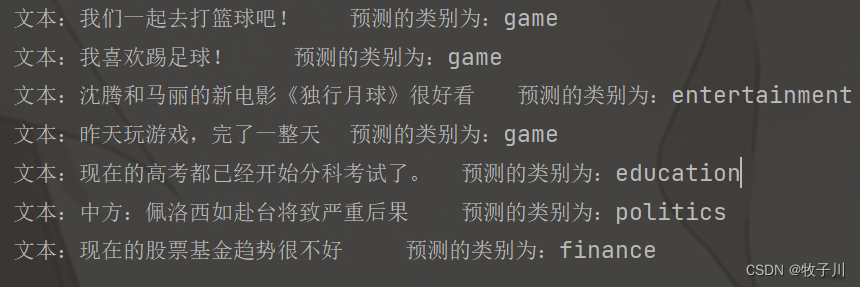
Bert 模型可以用于不同的场景,在文本分类,实体识别等场景的输入是不同的。
对于文本分类,其最主要的有两个参数:input_ids,attention_mask

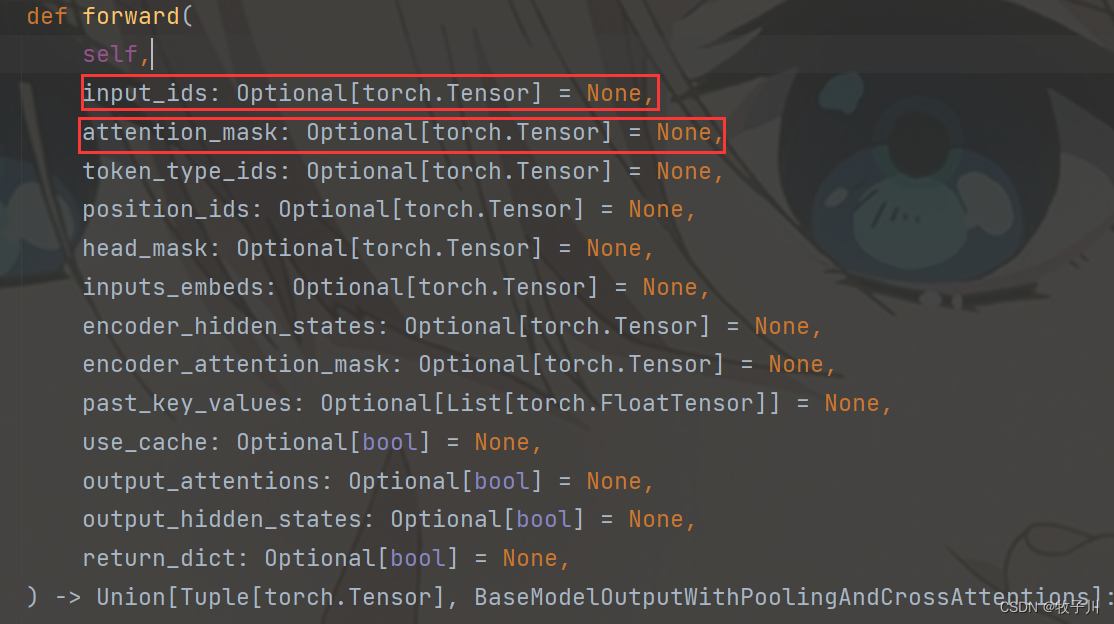
图2 bert 模型输入
input_ids:经过 tokenizer 分词后的 subword 对应的下标列表;
attention_mask:在 self-attention 过程中,这一块 mask 用于标记 subword 所处句子和 padding 的区别,将 padding 部分填充为 0;
Bert 模型输出
该模型的输出也是有多个,但是只有一个是用于文本分类的
bert的输出结果的其中四个维度:
1、last_hidden_state:shape是(batch_size, sequence_length, hidden_size),hidden_size=768,它是模型最后一层输出的隐藏状态。
2、pooler_output:shape是(batch_size, hidden_size),在通过用于辅助预训练任务的层进行进一步处理后,序列的第一个token(classification token)的最后一层的隐藏状态。例如。对于 BERT 系列模型,这会在通过线性层和 tanh 激活函数处理后返回分类标记。线性层权重在预训练期间从下一个句子预测(分类)目标进行训练。
3、hidden_states:shape是(batch_size, sequence_length, hidden_size),这是输出的一个可选项,如果输出,
需要指定`output_hidden_states=True` is passed or when `config.output_hidden_states=True`
它的第一个元素是embedding,其余元素是各层的输出。每层输出的模型隐藏状态加上可选的初始嵌入输出。
4、attentions:shape是(batch_size,num_heads,sequence_length,sequence_length),这也是输出的一个可选项,如果输出,
需要指定`output_attentions=True` is passed or when `config.output_attentions=True`
它的元素是每一层的注意力权重(softmax),用于计算self-attention heads的加权平均值。
我们是微调模式,需要获取bert最后一个隐藏层的输出输入到下一个全连接层,所以取第一个维度,也就是hiden_outputs.pooler_output
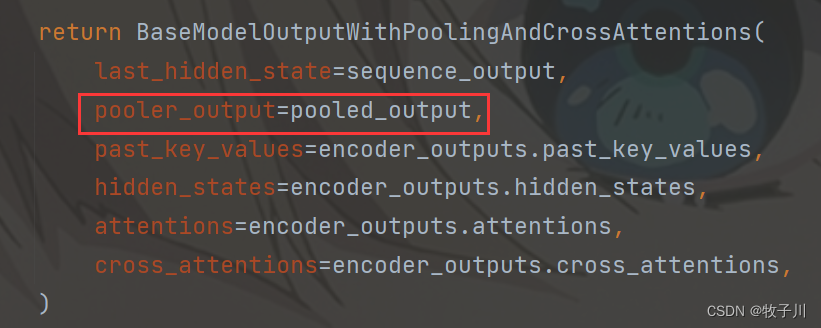
图3 bert 模型的输出
数据处理
数据格式

读取所有数据
# 读取文件
all_data = open(file, "r", encoding="utf-8").read().split("\n")
# 得到所有文本、所有标签、句子的最大长度
texts, labels, max_length = [], [], []
for data in all_data:
if data:
text, label = data.split("\t")
max_length.append(len(text))
texts.append(text)
labels.append(label)
将数据处理成模型输入的格式
# 取出一条数据并截断长度
text = self.all_text[index][:self.max_len]
label = self.all_label[index]
# 分词
text_id = self.tokenizer.tokenize(text)
# 加上起始标志
text_id = ["[CLS]"] + text_id
# 编码
token_id = self.tokenizer.convert_tokens_to_ids(text_id)
# 掩码 -》
mask = [1] * len(token_id) + [0] * (self.max_len + 2 - len(token_id))
# 编码后 -》长度一致
token_ids = token_id + [0] * (self.max_len + 2 - len(token_id))
# str -》 int
label = int(label)
# 转化成tensor
token_ids = torch.tensor(token_ids)
mask = torch.tensor(mask)
label = torch.tensor(label)
return (token_ids, mask), label模型准备
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.args = parsers()
self.device = "cuda:0" if self.args.device else "cpu"
# 加载 bert 中文预训练模型
self.bert = BertModel.from_pretrained(self.args.bert_pred)
# 让 bert 模型进行微调(参数在训练过程中变化)
for param in self.bert.parameters():
param.requires_grad = True
# 全连接层
self.linear = nn.Linear(self.args.num_filters, self.args.class_num)
def forward(self, x):
input_ids, attention_mask = x[0].to(self.device), x[1].to(self.device)
hidden_out = self.bert(input_ids, attention_mask=attention_mask,
output_all_encoded_layers=False) # 控制是否输出所有encoder层的结果
# shape (batch_size, hidden_size)
pred = self.linear(hidden_out.pooler_output)
# 返回预测结果
return pred模型训练
for epoch in range(args.epochs):
loss_sum, count = 0, 0
model.train()
for batch_index, (batch_text, batch_label) in enumerate(train_dataloader):
batch_label = batch_label.to(device)
pred = model(batch_text)
loss = loss_fn(pred, batch_label)
opt.zero_grad()
loss.backward()
opt.step()
loss_sum += loss
count += 1
# 打印内容
if len(train_dataloader) - batch_index <= len(train_dataloader) % 1000 and count == len(train_dataloader) % 1000:
msg = "[{0}/{1:5d}]\tTrain_Loss:{2:.4f}"
logging.info(msg.format(epoch + 1, batch_index + 1, loss_sum / count))
loss_sum, count = 0.0, 0
if batch_index % 1000 == 999:
msg = "[{0}/{1:5d}]\tTrain_Loss:{2:.4f}"
logging.info(msg.format(epoch + 1, batch_index + 1, loss_sum / count))
loss_sum, count = 0.0, 0训练结果
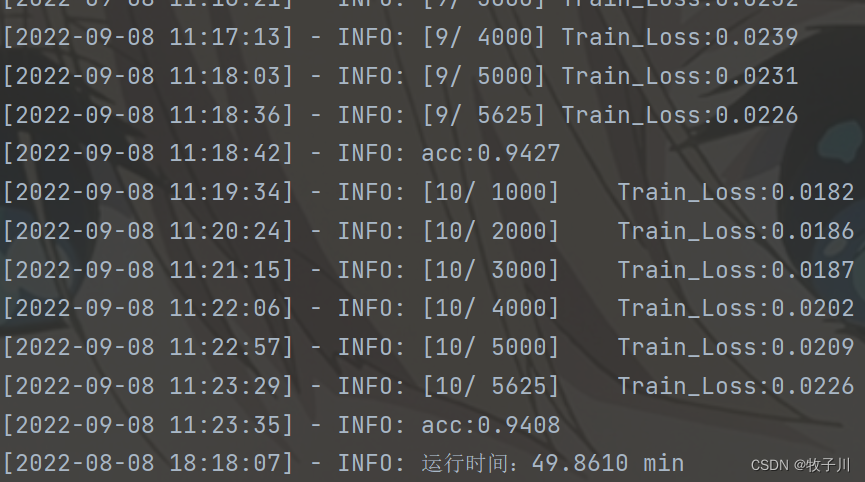
模型预测