目录
4 基于深度学习的文本分类
4.1 学习目标
- 学习FastText的使用和基础原理
- 学会使用验证集进行调参
4.2 文本表示方法 Part2
4.2.1 现有文本表示方法的缺陷
在上一节,我们介绍的几种文本表示方法:
- One-hot
- Bag of Words
- N-gram
- TF-IDF
也通过sklean进行了相应的实践。但上述方法或多或少都存在一定的问题:转换得到的向量维度很高,需要较长时间的训练时间;没有考虑单词与单词之间的关系,只是进行了统计。
与这些表示方法不同,深度学习也可以用于文本表示,还可以将其映射到一个低维空间。其中比较典型的例子有:FastText、Word2Vec和Bert。在本章我们介绍FastText,将在后面内容介绍Word2Vec和Bert。
4.2.2 FastText
FastText是一种典型的深度学习词向量的表示方法,他非常简单通过Embedding层将单词映射到稠密空间,然后将句子中所有的单词在Embedding空间中进行平均,进而完成分类操作。
所以FastText是一个三层的神经网络:输入层、隐含层和输出层。
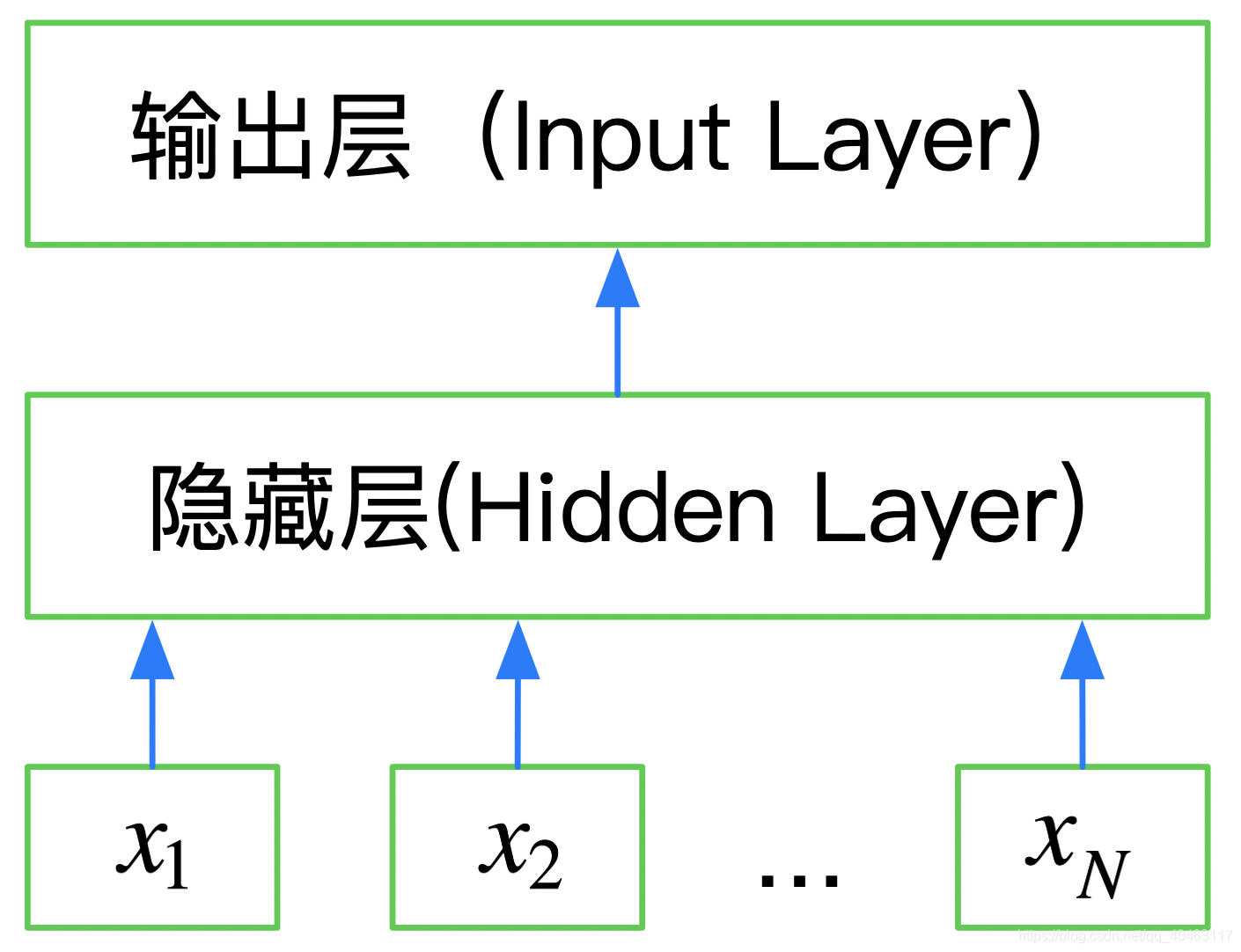
下图是使用Keras实现的FastText网络结构: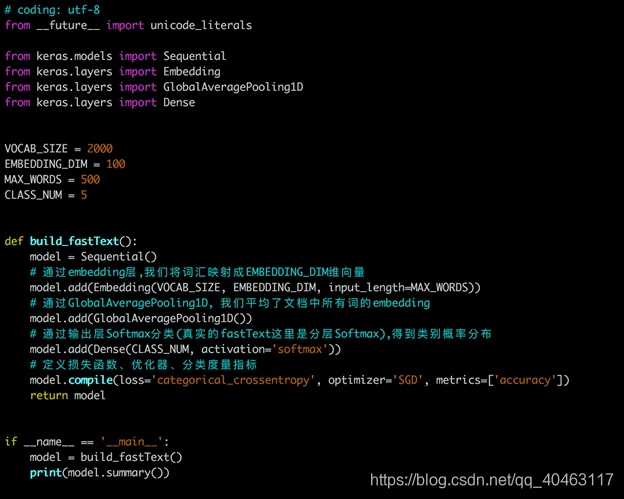
FastText在文本分类任务上,是优于TF-IDF的:
- FastText用单词的Embedding叠加获得的文档向量,将相似的句子分为一类。
- FastText学习到的Embedding空间维度比较低,可以快速进行训练。
如果想深度学习,请参考论文:
Bag of Tricks for Efficient Text Classification
4.3 基于FastText的文本分类
FastText可以快速的在CPU上进行训练,最好的实践方法是官方的开源版本:https://github.com/facebookresearch/fastText/tree/master/python
- pip安装
pip install fasttext - 源码安装
git clone https://github.com/facebookresearch/fastText.git
cd fastText
sudo pip install .
分类模型
import pandas as pd
from sklearn.metrics import f1_score
# 转换为FastText需要的格式
train_df = pd.read_csv('../input/train_set.csv', sep='\t', nrows=15000)
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
train_df[['text','label_ft']].iloc[:-5000].to_csv('train.csv', index=None, header=None, sep='\t')
import fasttext
model = fasttext.train_supervised('train.csv', lr=1.0, wordNgrams=2,
verbose=2, minCount=1, epoch=25, loss="hs")
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in train_df.iloc[-5000:]['text']]
print(f1_score(train_df['label'].values[-5000:].astype(str), val_pred, average='macro'))
# 0.82
此时数据量比较小得分为0.82,当不断增加训练集数量时,FastText的精度也会不断增加5w条训练样本时,验证集得分可以到0.89-0.90左右。
4.4 如何使用验证集调参
在使用TF-IDF和FastText中,有一些模型的参数需要选择,这些参数会在一定程度上影响模型的精度,那么如何选择这些参数呢?
- 通过阅读文档,要弄清楚这些参数的大致含义,那些参数会增加模型的复杂度
- 通过在验证集上进行验证模型精度,找到模型在是否过拟合还是欠拟合
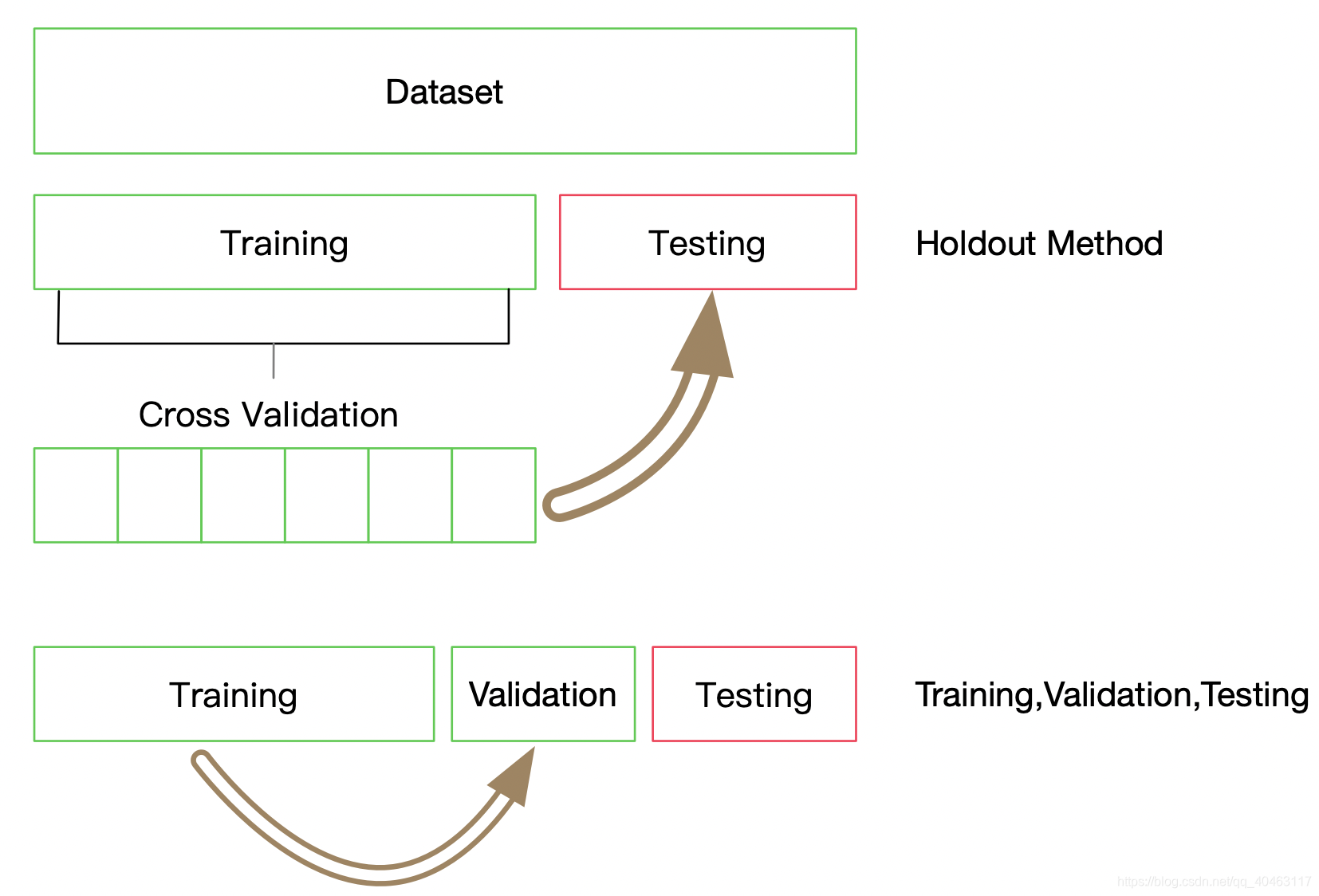
这里我们使用10折交叉验证,每折使用9/10的数据进行训练,剩余1/10作为验证集检验模型的效果。这里需要注意每折的划分必须保证标签的分布与整个数据集的分布一致。
label2id = {
}
for i in range(total):
label = str(all_labels[i])
if label not in label2id:
label2id[label] = [i]
else:
label2id[label].append(i)
通过10折划分,我们一共得到了10份分布一致的数据,索引分别为0到9,每次通过将一份数据作为验证集,剩余数据作为训练集,获得了所有数据的10种分割。不失一般性,我们选择最后一份完成剩余的实验,即索引为9的一份做为验证集,索引为1-8的作为训练集,然后基于验证集的结果调整超参数,使得模型性能更优。
4.5 本章小结
本章介绍了FastText的原理和基础使用,并进行相应的实践。然后介绍了通过10折交叉验证划分数据集。
4.6 作业
1. 阅读FastText的文档,尝试修改参数,得到更好的分数。
- 加载词向量模型
model = fasttext.load_model(“model.bin”,encoding = “utf-8”)
- model 方法一览:
print model.model_name ‘’’ 模型名称 ‘’’
print model.words ‘’’ 词汇列表 ‘’’
print model.dim ‘’’ 词向量维度 ‘’’
print model.ws ‘’’ 上下文窗口大小 ‘’’
print model.epoch ‘’’ epochs 数量 ‘’’
print model.min_count ‘’’ 最低词频 ‘’’
print model.word_ngrams ‘’’ n-gram 设置’’’
print model.loss_name ‘’’ 损失函数名称 ‘’’
print model.minn ‘’’ 模型最小字符长度 ‘’’
print model.maxn ‘’’ 模型最大字符长度 ‘’’
print model.lr_update_rate ‘’’ 学习率更新速率 ‘’’
print model.t ‘’’ 采样阈值 ‘’’
print model.encoding ‘’’ 模型编码 ‘’’
print model[word] ‘’’ word 的词向量 ‘’’
当验证集数量达到20w时,得分为0.909。
2. 基于验证集的结果调整超参数,使得模型性能更优。
我们还可以改变 训练次数epochs,学习率lr(learning rate)和使用word n-gram(-wordNgrams)来提高精度
简单的调整参数后结果得出0.914。

实际上,分层softmax在效果上比完全softmax略差。这是因为,分层softmax是完全softmax的一个近似,分层softmax可以让我们在大数据集上高效的建立模型,但通常会以损失精度的几个百分点为代价。因设备和时间问题此处不做演示。