“伶荔”(Linly) 项目发布中文LLaMA2模型

大数据系统计算技术国家工程实验室副主任沈琳琳教授团队主持的人工智能项目“伶荔(Linly)”已于前期推出基于LLaMA-1、Falcon等模型的中文迁移版本。最近,团队在LLaMA-2上进行了中文化训练和质量评估,目前已发布Chinese-LLaMA2 7B 和13B版本。让我们一起来看看吧!
1
项目简介
随着大型语言模型在众多领域展现出巨大的应用潜力,基础模型也成为人们关注的焦点。近期,许多机构都推出了中文基础模型,如GLM、baichuan等,这些模型使用了大量算力构建,他们的公开也为社区研究者们提供了极大便利。
同时,也有许多具有代表性的模型都主要基于英文训练(例如LLaMA-1&2、Falcon),虽然他们在英文上能力强大,但是跨语言性能较弱。为了向社区提供更多模型的选择,以及为其他小语种提供训练方案,大数据系统计算技术国家工程实验室副主任、深圳大学计软学院计算机视觉研究所所长,沈琳琳教授带领“伶荔”项目团队提出了一种跨语言迁移的方法,基于英文预训练语言模型,使用相比从头预训练很少的计算量,在中文语料上增量训练并对齐英文知识,获得高性能的中文模型。
在此之前,“伶荔”项目团队已经发布了基于LLaMA-1、Falcon等模型的中文迁移版本。最近,团队在LLaMA-2上进行了中文化训练和质量评估,目前已发布Chinese-LLaMA2 7B 和13B版本。
模型下载地址:https://github.com/CVI-SZU/Linly
Huggingface
在线体验:https://huggingface.co/spaces/Linly-AI/Linly-ChatFlow
2
训练方案
此前的对话模型训练通常区分语言模型训练阶段和指令精调阶段,为了简化训练流程,快速为模型进行知识迁移和增强中文能力,项目团队在Chinese-LLaMA2训练使用包含不同数据源的混合数据。
其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含 SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。
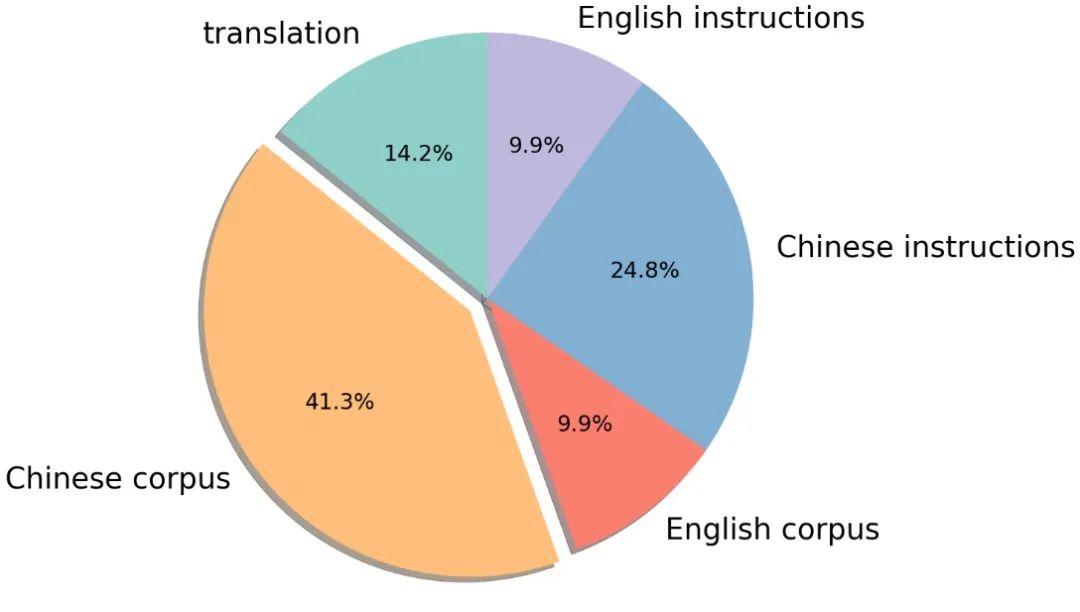
有监督数据包括基于self-instruction构建的指令数据集,例如 BELLE、Alpaca、Baize、InstructionWild 等;使用人工 prompt 构建的数据例如 FLAN、COIG、Firefly、pCLUE 等。语料的分布如图所示:
3
词表扩充与初始化
LLaMA-2 沿用了 LLaMA-1 的词表,因此依然面临缺乏中文词的问题。在 Linly-LLaMA-2 中,直接扩充了 8076 个常用汉字和标点符号,在模型 embedding 和 target 层使用这些汉字在原始词表中对应 tokens 位置的均值作为初始化。
4
模型训练
在训练阶段,使用Alpaca格式作为指令的分隔符,将所有数据随机打乱,全参数微调模型。此外,使用课程学习(Curriculum learning)训练策略,在训练对初期使用更多英文语料和平行语料,随着训练步数增加逐步提升中文数据对比例,为模型训练提供平缓的学习路径,有助于收敛稳定性。训练基于 TencentPretrain 预训练框架,使用 5e-5 学习率、cosine scheduler、2048 序列长度、512 batch size、BF16 精度,用 deepspeed zero2 进行训练。
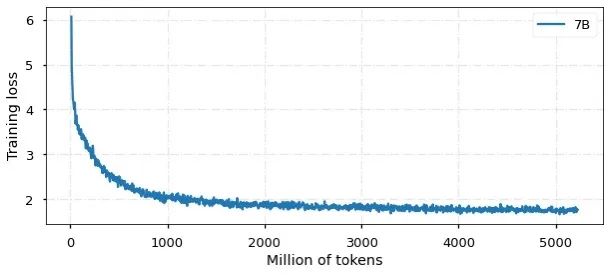
目前,模型已经训练 50亿中英文tokens,收敛情况如图所示:
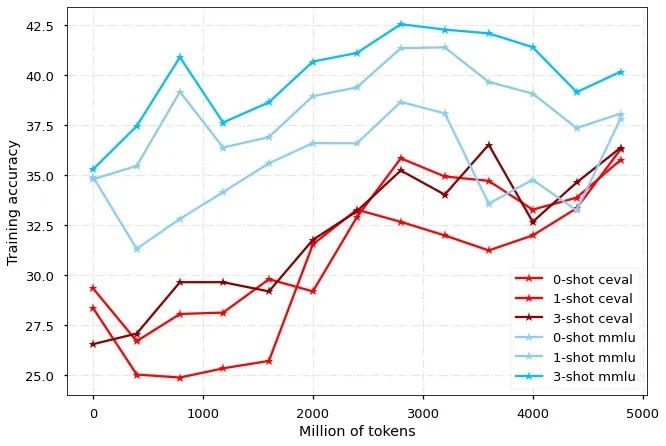
模型分别在 MMLU 和 CEVAL 榜单上评估英文和中文的表现,可以看出,Chinese-LLaMA2模型能够在不损失英文性能的前提下,快速提升中文能力。
5
生成示例
知识问答

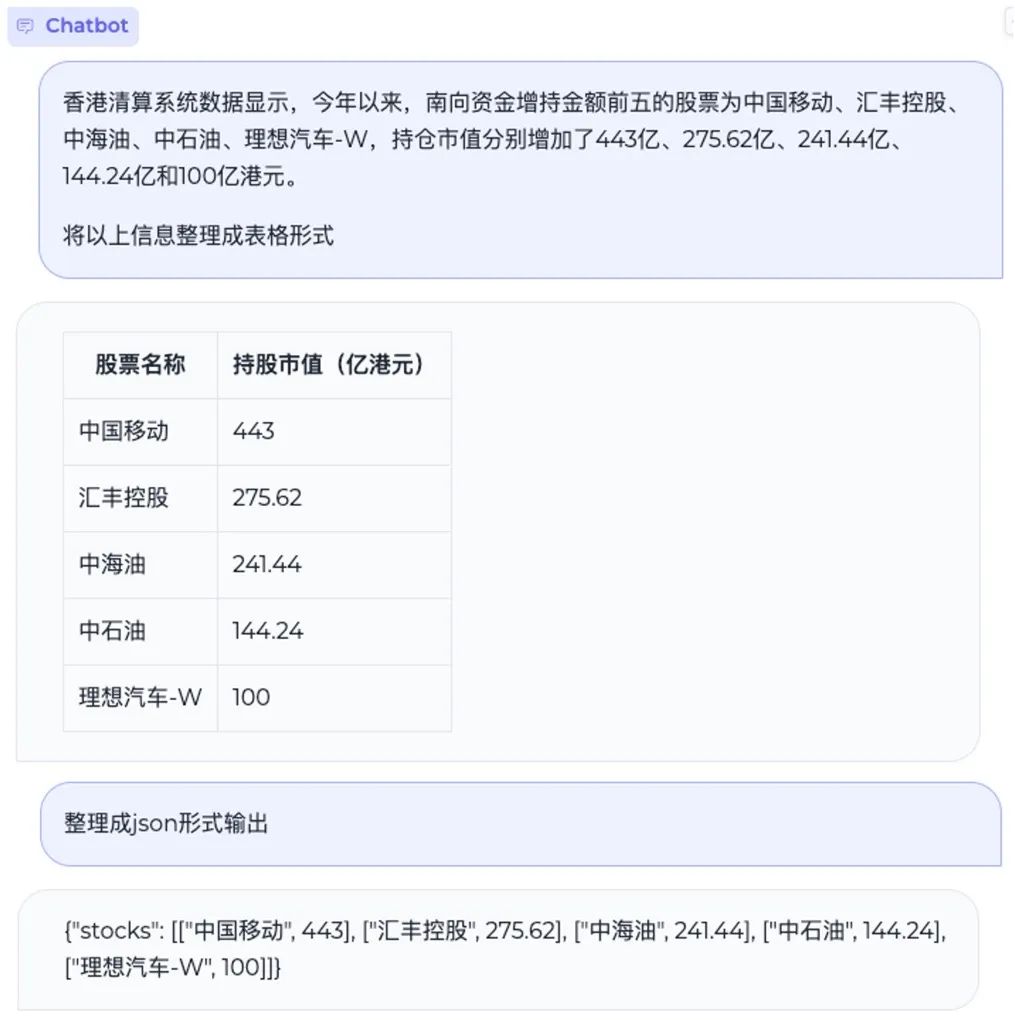
信息抽取
代码生成


AINLP
一个有趣有AI的自然语言处理公众号:关注AI、NLP、机器学习、推荐系统、计算广告等相关技术。公众号可直接对话双语聊天机器人,尝试自动对联、作诗机、藏头诗生成器,调戏夸夸机器人、彩虹屁生成器,使用中英翻译,查询相似词,测试NLP相关工具包。